A Dynamic LLM-Powered Agent Network for Task-Oriented Agent Collaboration
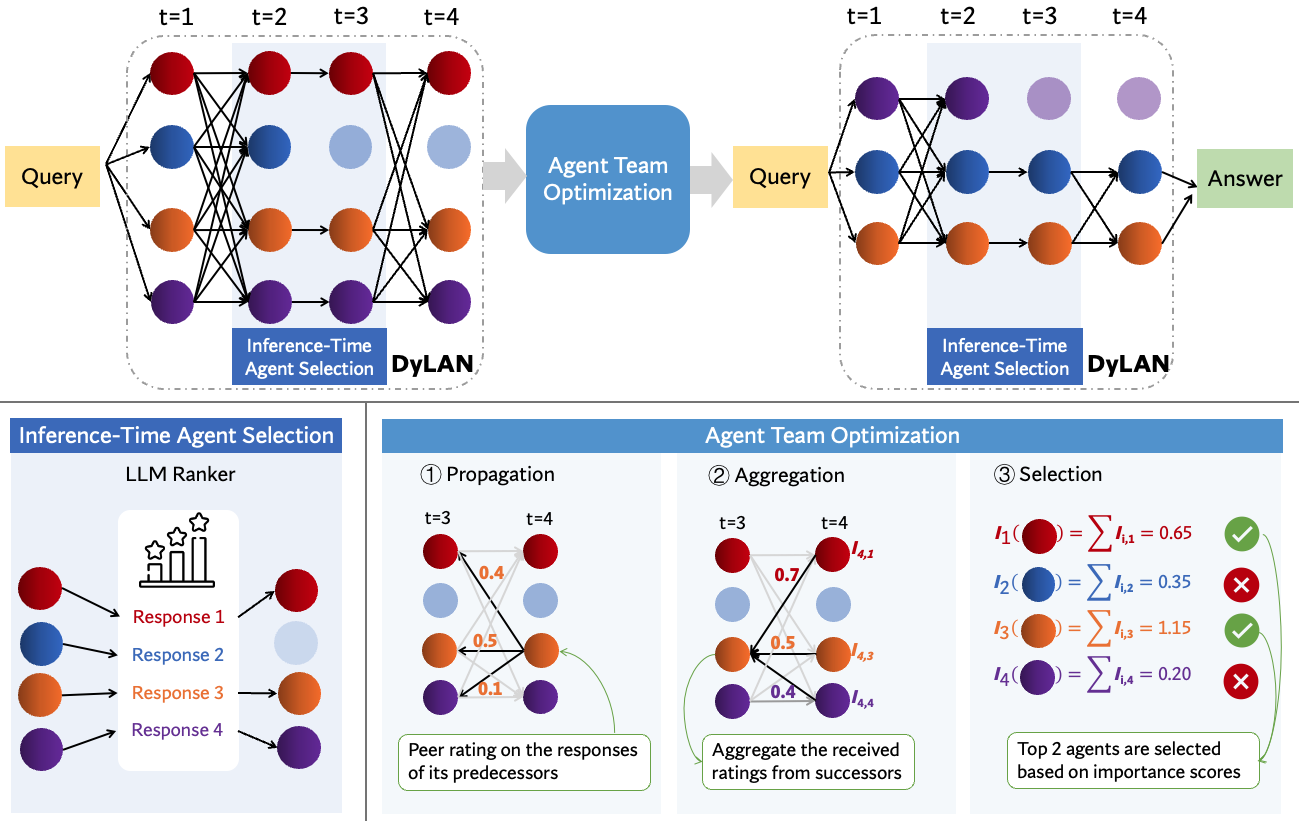
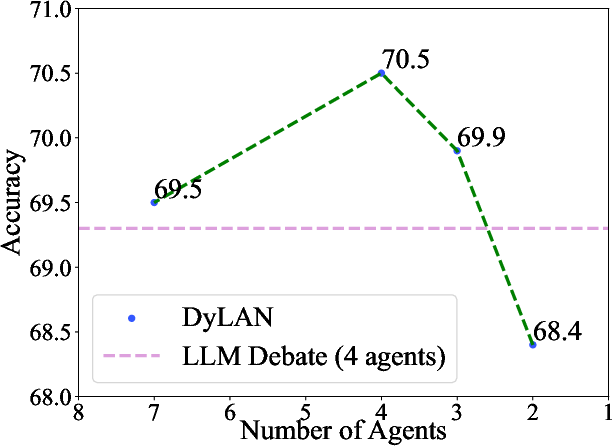
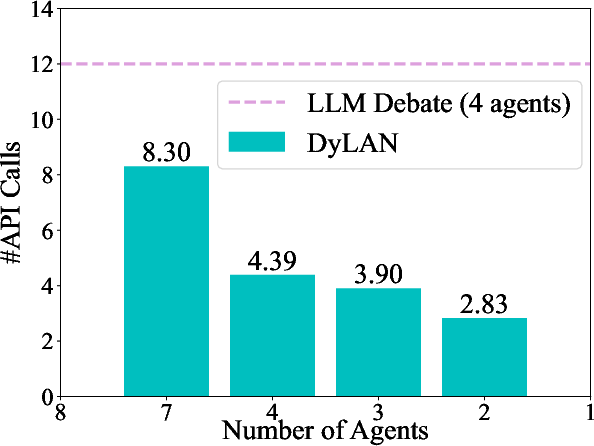
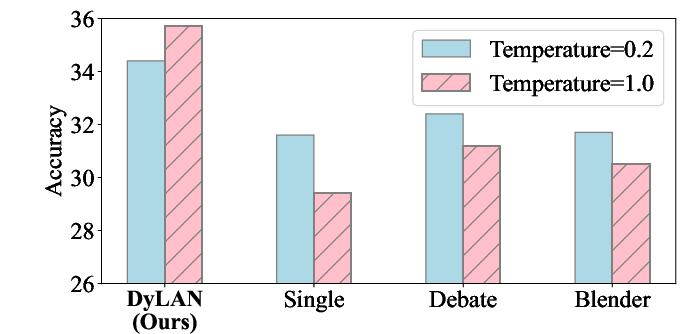
Abstract: Recent studies show that collaborating multiple LLM powered agents is a promising way for task solving. However, current approaches are constrained by using a fixed number of agents and static communication structures. In this work, we propose automatically selecting a team of agents from candidates to collaborate in a dynamic communication structure toward different tasks and domains. Specifically, we build a framework named Dynamic LLM-Powered Agent Network ($\textbf{DyLAN}$) for LLM-powered agent collaboration, operating a two-stage paradigm: (1) Team Optimization and (2) Task Solving. During the first stage, we utilize an $\textit{agent selection}$ algorithm, based on an unsupervised metric called $\textit{Agent Importance Score}$, enabling the selection of best agents according to their contributions in a preliminary trial, oriented to the given task. Then, in the second stage, the selected agents collaborate dynamically according to the query. Empirically, we demonstrate that DyLAN outperforms strong baselines in code generation, decision-making, general reasoning, and arithmetic reasoning tasks with moderate computational cost. On specific subjects in MMLU, selecting a team of agents in the team optimization stage improves accuracy by up to 25.0% in DyLAN.
- Let’s sample step by step: Adaptive-consistency for efficient reasoning with llms, 2023.
- Graph of thoughts: Solving elaborate problems with large language models, August 01, 2023 2023.
- Practical byzantine fault tolerance. In Proceedings of the Third Symposium on Operating Systems Design and Implementation, OSDI ’99, pp. 173–186, USA, 1999. USENIX Association. ISBN 1880446391.
- ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate. arXiv e-prints, art. arXiv:2308.07201, August 2023.
- Codet: Code generation with generated tests. In The Eleventh International Conference on Learning Representations, 2023a. URL https://openreview.net/forum?id=ktrw68Cmu9c.
- Evaluating large language models trained on code, July 01, 2021 2021. corrected typos, added references, added authors, added acknowledgements.
- Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors in agents, 2023b.
- Self-collaboration Code Generation via ChatGPT. arXiv e-prints, art. arXiv:2304.07590, April 2023.
- Improving factuality and reasoning in language models through multiagent debate, May 01, 2023 2023. Project Webpage and Code: https://composable- models.github.io/llm_debate/.
- Chatllm network: More brains, more intelligence, April 01, 2023 2023.
- Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR), 2021a.
- Measuring mathematical problem solving with the math dataset. NeurIPS, 2021b.
- Trueskill™: A bayesian skill rating system. In B. Schölkopf, J. Platt, and T. Hoffman (eds.), Advances in Neural Information Processing Systems, volume 19. MIT Press, 2006. URL https://proceedings.neurips.cc/paper_files/paper/2006/file/f44ee263952e65b3610b8ba51229d1f9-Paper.pdf.
- Metagpt: Meta programming for multi-agent collaborative framework, August 01, 2023 2023.
- LLM-blender: Ensembling large language models with pairwise ranking and generative fusion. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 14165–14178, Toronto, Canada, July 2023. Association for Computational Linguistics. URL https://aclanthology.org/2023.acl-long.792.
- Surrealdriver: Designing generative driver agent simulation framework in urban contexts based on large language model, 2023.
- Encouraging divergent thinking in large language models through multi-agent debate, May 01, 2023 2023. Work in progress.
- An efficient and truthful pricing mechanism for team formation in crowdsourcing markets. In 2015 IEEE International Conference on Communications (ICC), pp. 567–572, 2015.
- Agentbench: Evaluating llms as agents, August 01, 2023 2023a. 38 pages.
- Bolaa: Benchmarking and orchestrating llm-augmented autonomous agents, August 01, 2023 2023b. Preprint.
- Chameleon: Plug-and-play compositional reasoning with large language models. arXiv preprint arXiv:2304.09842, 2023.
- A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, pp. 4768–4777, Red Hook, NY, USA, 2017. Curran Associates Inc. ISBN 9781510860964.
- Self-organization in online collaborative work settings. Collective Intelligence, 1(1), sep 2022.
- Yohei Nakajima. Babyagi. https://github.com/yoheinakajima/babyagi, 2023.
- GPT-in-the-Loop: Adaptive Decision-Making for Multiagent Systems. arXiv e-prints, art. arXiv:2308.10435, August 2023.
- Skeleton-of-thought: Large language models can do parallel decoding, July 01, 2023 2023. Technical report, work in progress.
- OpenAI. Gpt-4 technical report, 2023.
- Matt Post. A call for clarity in reporting BLEU scores. In Proceedings of the Third Conference on Machine Translation: Research Papers, pp. 186–191, Belgium, Brussels, October 2018. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/W18-6319.
- Large language models are effective text rankers with pairwise ranking prompting, June 01, 2023 2023. 12 pages, 3 figures.
- Codebleu: a method for automatic evaluation of code synthesis. ArXiv, abs/2009.10297, 2020.
- Reworkd. Agentgpt. https://github.com/reworkd/AgentGPT, 2023.
- Toran Bruce Richards and et al. Auto-gpt: An autonomous gpt-4 experiment. https://github.com/Significant-Gravitas/Auto-GPT, 2023.
- Tptu: Task planning and tool usage of large language model-based ai agents, August 01, 2023 2023.
- Reflexion: Language agents with verbal reinforcement learning, March 01, 2023 2023. v3 contains additional citations.
- Voyager: An Open-Ended Embodied Agent with Large Language Models. arXiv e-prints, art. arXiv:2305.16291, May 2023.
- Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations, 2023a. URL https://openreview.net/forum?id=1PL1NIMMrw.
- Unleashing cognitive synergy in large language models: A task-solving agent through multi-persona self-collaboration, July 01, 2023 2023b. work in progress.
- Chain-of-thought prompting elicits reasoning in large language models, January 01, 2022 2022.
- Autogen: Enabling next-gen llm applications via multi-agent conversation framework, August 01, 2023 2023. 28 pages.
- Listwise approach to learning to rank: Theory and algorithm. In Proceedings of the 25th International Conference on Machine Learning, ICML ’08, pp. 1192–1199, New York, NY, USA, 2008. Association for Computing Machinery. ISBN 9781605582054.
- Examining the inter-consistency of large language models: An in-depth analysis via debate, May 01, 2023 2023.
- Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs. arXiv e-prints, art. arXiv:2306.13063, June 2023.
- React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=WE_vluYUL-X.
- Nisp: Pruning networks using neuron importance score propagation. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9194–9203, 2018.
- Cumulative reasoning with large language models, August 01, 2023 2023.
- Progressive-hint prompting improves reasoning in large language models, April 01, 2023 2023. Tech Report.
- LLM As DBA. arXiv e-prints, art. arXiv:2308.05481, August 2023.
- Ghost in the Minecraft: Generally Capable Agents for Open-World Environments via Large Language Models with Text-based Knowledge and Memory. arXiv e-prints, art. arXiv:2305.17144, May 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.