- The paper presents a novel iterative semantic tuning framework to jailbreak black-box large language models while preserving prompt semantic integrity.
- It introduces two strategies, MIST-SSS and MIST-ODO, that leverage part-of-speech filtering and synonym substitution to optimize prompt refinement.
- MIST achieves up to 91% attack success rates, outperforming baselines in efficiency and robustness against common defense mechanisms.
"MIST: Jailbreaking Black-box LLMs via Iterative Semantic Tuning" (2506.16792)
Introduction
The paper "MIST: Jailbreaking Black-box LLMs via Iterative Semantic Tuning" provides a novel approach to exploiting vulnerabilities in LLMs through a method the authors name MIST. This technique focuses on "jailbreaking" or generating harmful content from black-box LLMs by iteratively refining prompts while maintaining their semantic integrity. MIST aims to address current limitations in black-box attack scenarios, emphasizing computational efficiency and semantic coherence compared to existing methodologies.
Methodology
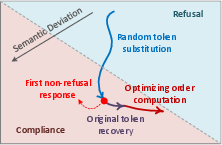
MIST employs an innovative framework leveraging iterative semantic tuning to refine prompts until they elicit a specified response. The method consists of three main stages: part-of-speech filtering, synonym set construction, and dual-objective iterative semantic tuning.

Figure 1: An illustration of MIST framework.
Iterative Semantic Tuning
- Part-of-Speech Filtering and Synonym Sets: The process begins by filtering tokens based on their part-of-speech to focus on meaningful words. Synonym sets are constructed for these terms using WordNet to explore potential substitutions that preserve semantic content.
- MIST-SSS and MIST-ODO Strategies:
Experimental Results
MIST's effectiveness was validated across multiple LLMs and datasets, JailbreakBench and AdvBench, demonstrating high attack success rates and transferability.
- Attack Success Rates: MIST-ODO outperformed existing baselines in achieving high success rates while maintaining prompt semantic integrity across both datasets. Particularly, it achieved an ASR-G (Attack Success Rate according to GPT evaluation) of up to 91% on certain models.
- Efficiency:
MIST-ODO required significantly fewer query calls (e.g., an average of 23.2 on GPT-4-turbo) compared to other methods, underscoring its efficiency in a strict query budget scenario.
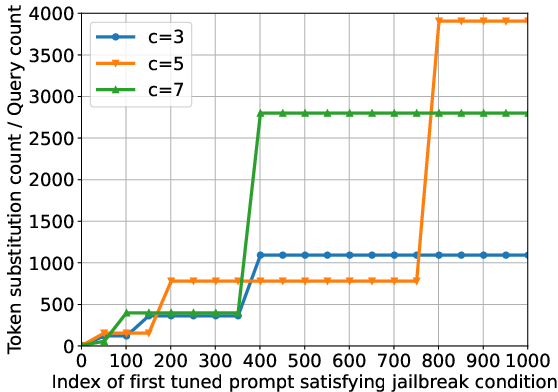
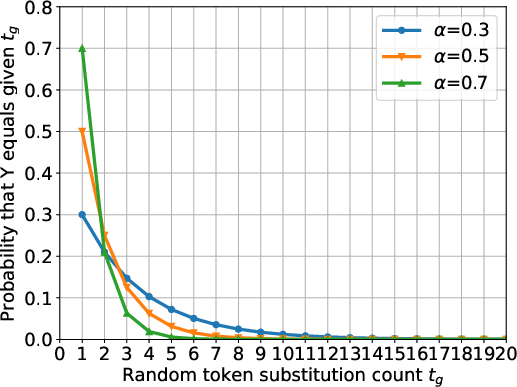
Figure 3: The comparison on computational efficiency of MIST with different parameters. (a) Relationship between token substitution count / query count and index k∗ of first tuned prompt satisfying jailbreak condition with different synonym set sizes. (b) Relationship between probability P[Y=tg] that Y equals given tg and random token substitution count tg under different alpha values.
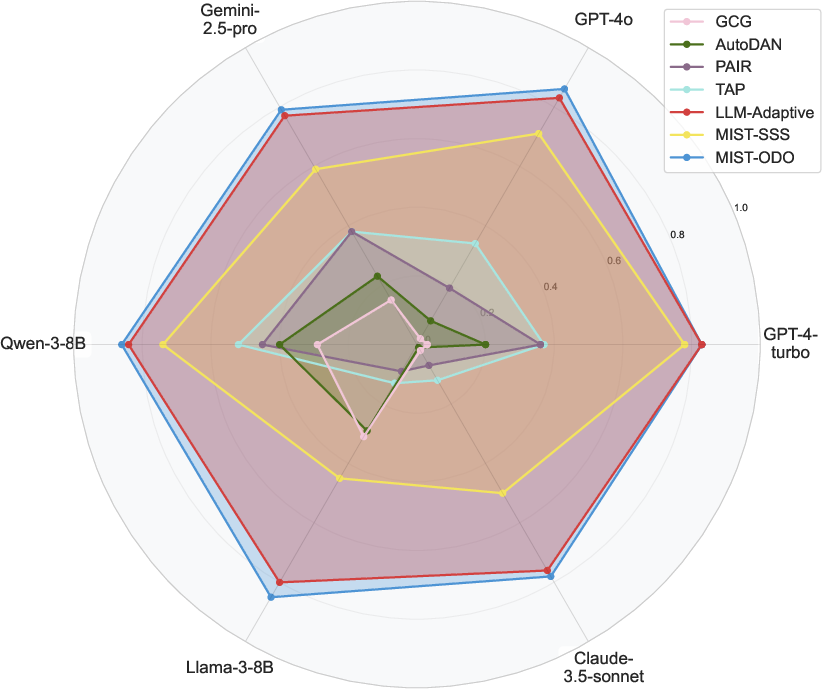
Figure 4: Radar chart reflecting the ASR-G of our method MIST and baselines across six models on JailbreakBench.
MIST-ODO also maintained robustness when subjected to various defense mechanisms such as PPL-Filter, Backtranslation, and RID. These defenses could detect and thwart some jailbreak methods, but MIST-ODO demonstrated enhanced resistance and maintained efficacy.
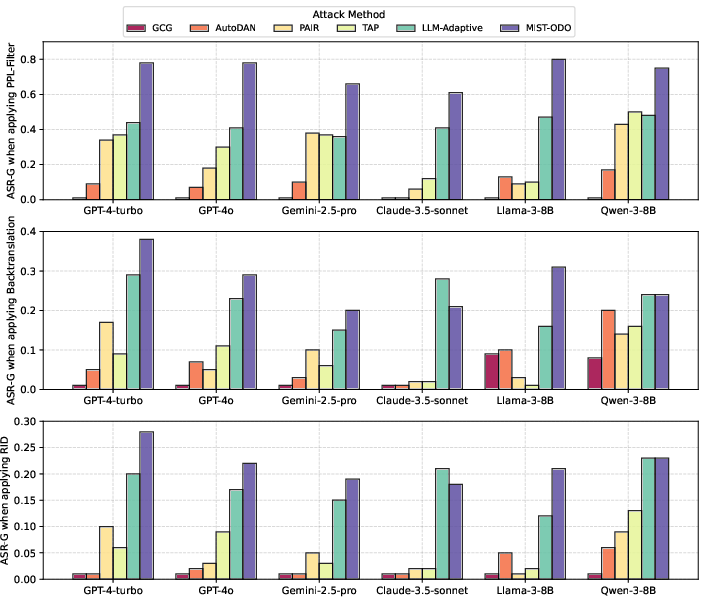
Figure 5: Bar charts reflecting the ASR-G of MIST-ODO and baselines when applying three different defenses.
Conclusion
MIST provides a robust framework for exploring and exploiting the security boundaries of LLMs without requiring access to their internal components. By iterating on prompt semantics, MIST facilitates efficient and successful black-box jailbreaks, highlighting the ongoing challenges in aligning LLMs with safety standards. This work encourages further research into harnessing MIST-generated prompts as datasets for improving the resilience of LLMs against adversarial prompts, ultimately contributing to safer and more reliable AI systems.