- The paper demonstrates that a BERT-based approach effectively distinguishes between regular and jailbroken prompts using advanced data augmentation.
- The study develops a multi-class classifier that categorizes various jailbreak strategies, highlighting metrics like AUC and false negative rates.
- The work emphasizes the need for continuous updates in security frameworks to counter evolving jailbreak tactics in large language models.
Machine Learning for Detection and Analysis of Novel LLM Jailbreaks
The paper "Machine Learning for Detection and Analysis of Novel LLM Jailbreaks" explores the vulnerabilities present in LLMs that allow for the generation of harmful or biased content through the manipulation of input prompts. Specifically, it examines the potential for using machine learning techniques to effectively identify and categorize jailbreak attempts, paying particular attention to the use of Bidirectional Encoder Representations from Transformers (BERT) as a means of detection.
Introduction to LLM Jailbreaks
LLMs, while powerful, are susceptible to vulnerabilities known as jailbreaks, where maliciously crafted prompts circumvent safety algorithms to produce undesirable outputs. These jailbreaks exploit the dichotomy between the training data that imbues these models with their capabilities and the safety measures imposed during model alignment. The analysis surveys current methodologies for mitigating such threats, including both model fine-tuning and computational detection layers.
Models like GPT-4 face a twofold challenge: addressing known jailbreak patterns while remaining watchful for novel strategies, which can be combinations of existing prompt variants or entirely new constructs devised to trick the LLM into bypassing safety controls.
Methodology
The study leverages a diverse set of data from multiple known sources, encompassing both jailbreak and non-jailbreak prompts to construct a training dataset conducive to model training. Data augmentation techniques such as back translation and synonym substitution enhance the robustness of training by increasing linguistic diversity:
These augmented datasets support the development of models that can more effectively generalize across different prompt constructions, improving jailbreaking detection.
Framework for Jailbreak Detection
The research employs BERT, crucially due to its proven discriminative capacity in language understanding tasks. The detection framework is defined by its ability to classify both known and novel jailbreak prompts:
- Jailbreak Identification: BERT models undergo fine-tuning to distinguish between regular prompts and those indicative of a jailbreak.
- Prompt Categorization: A classifier is developed to recognize various strategies within prompts. Each strategy forms a label within a multi-class classification framework.
In experiments simulating novel jailbreak detection, specific prompt types are withheld during training to test model efficacy on unexposed categories. This iterative exclusion allows for an objective assessment of classifier robustness against novel manipulations.
Results
The BERT-based classifiers achieved high accuracy in discriminating between jailbreak and non-jailbreak prompts, with a notable mean AUC score surpassing other models. When tasked with novel jailbreaks, performance metrics such as false negative rates (FNR) are critical to ensure resilient detection. Results indicate varying susceptibility based on prompt novelty and semantic congruence with known types.
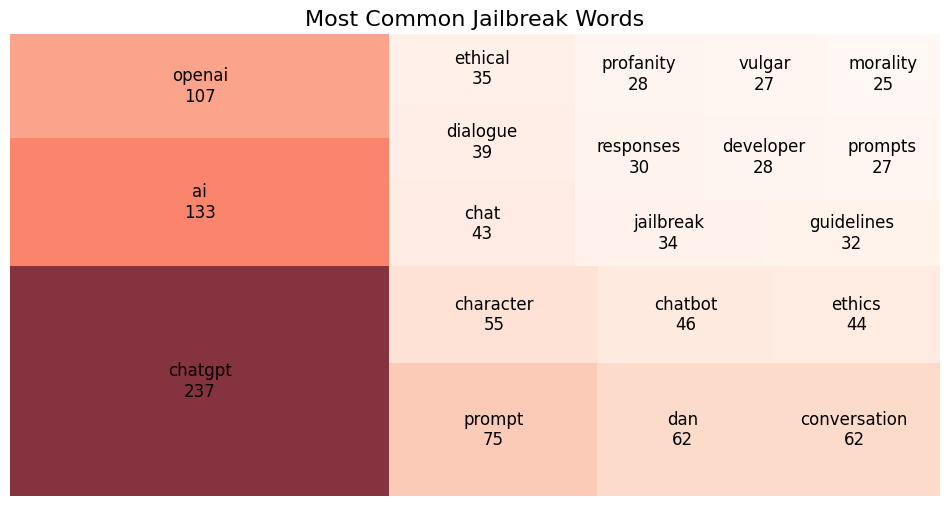
Figure 2: Frequent Words used in Jailbreak Prompts
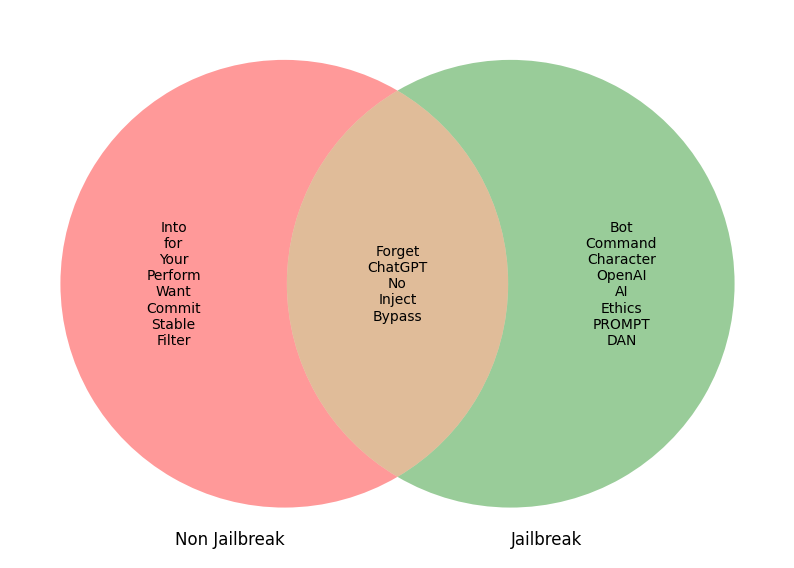
Figure 3: Jailbreak Vs. Non-Jailbreak Keywords
These figures reveal underlying semantic elements, aiding in the identification of linguistic patterns characteristic of jailbreak prompts. Such insights highlight the reflexivity in jailbreak strategies regarding corporate policy and ethical constraints, reinforcing the need to focus on self-referential language elements as key signals.
Discussion
Analysis underscores the effectiveness of BERT in both known and novel jailbreak mitigation, reaffirming machine learning's potential within security frameworks for LLM systems. However, the evolving nature of threat vectors—evident from novel jailbreak forms—necessitates continuous development of adaptable, computationally efficient detection methodologies.
The semantic insights into jailbreak construction point toward future ventures in crafting sophisticated linguistic feature sets that can bolster prompt classification systems.
Conclusion
This research presents a comprehensive look at leveraging machine learning for effective jailbreak detection in LLMs, confirming the utility of BERT models across a broad spectrum of prompt manipulations. By emphasizing linguistic feature refinement, this study paves the way for ongoing improvements in LLM security, ensuring agile responses to the dynamic landscape of AI vulnerabilities.


