- The paper introduces U-CoT+, a framework that decouples meme understanding from classification by employing guided chain-of-thought reasoning for zero-shot harmful content detection.
- The High-Fidelity Meme2Text pipeline converts visual meme content into detailed textual descriptions, enabling efficient and flexible reasoning with LLMs.
- Experiments on seven benchmark datasets demonstrate that U-CoT+ achieves state-of-the-art accuracy while significantly improving resource efficiency and explainability.
Detecting Harmful Memes with Decoupled Understanding and Guided CoT Reasoning
The paper "Detecting Harmful Memes with Decoupled Understanding and Guided CoT Reasoning" introduces a novel framework, U-CoT+, aimed at addressing the limitations of existing methods in harmful meme detection. The proposed framework significantly enhances resource efficiency, flexibility, and explainability, making it suitable for deployment in diverse content moderation systems.
Introduction
Memes are a predominant medium of communication on social media, capable of spreading both benign and harmful content. Detecting harmful memes, such as those containing hate speech or misinformation, is critical but challenging due to the nuanced nature of memes. Traditional methods often rely on supervised fine-tuning of LMMs or LLMs, which are resource-intensive and lack flexibility and explainability.
The U-CoT+ framework innovatively decouples the process of meme understanding from meme classification. By converting visual memes into detailed textual descriptions through a High-Fidelity Meme2Text pipeline, the framework reduces task complexity. It uses general LLMs for reasoning over these descriptions with zero-shot Chain-of-Thought (CoT) prompting. This method allows for flexible adaptation to varying criteria of harmful content detection across multiple contexts and sociocultural fields.
Methodology
High-Fidelity Meme2Text Pipeline
The High-Fidelity Meme2Text pipeline is designed to ensure comprehensive meme content understanding while minimizing resource use. It utilizes LMMs for detailed visual question answering to extract key visual details from memes, including sensitive characteristics such as race, gender, and appearance. These details are crucial for identifying potential harmfulness and are then synthesized into unified textual descriptions by LLMs.
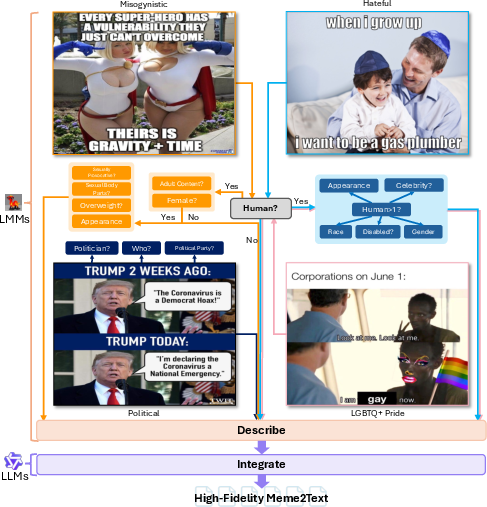
Figure 1: Our proposed High-fidelity Meme2Text pipeline.
Unimodal Guided CoT Prompting
With the textual description of memes, the framework employs Guided CoT prompting. This involves providing the LLMs with explicit, human-crafted guidelines that detail criteria for harmful content detection. These guidelines are derived from common societal norms and specific dataset insights, encompassing aspects such as implicitness, tone and intent, fine-grained taxonomy, and real-life examples with outlined exceptions.
The LLMs, prompted with these guidelines, perform zero-shot classification, reasoning step-by-step to determine the harmfulness of memes. This approach not only enhances accuracy but also provides human-interpretable rationales, increasing trust and adaptability.
Experiments and Results
The effectiveness of U-CoT+ is demonstrated through extensive experiments on seven benchmark datasets, including but not limited to FHM, HarMeme, and PrideMM. The results show that U-CoT+ achieves performance comparable to state-of-the-art supervised methods, particularly in resource-constrained settings. The framework manages to outperform advanced LMM-based models such as GPT-4o in various tasks.
The guided CoT prompting significantly benefits smaller LLMs like Qwen2.5-14B and Mistral-12B, enabling them to achieve high accuracy and macro-F1 scores. The framework efficiently classifies harmful and harmless memes across different contexts, proving the feasibility of using LLMs for low-resource, explainable meme detection.
Error Analysis
Detailed error analysis reveals common issues such as incorrect visual detail extraction, excessive censorship by LLMs, and misclassification due to mismatched or incomplete guidelines. These insights pave the way for refining the framework and understanding LLMs' decision-making processes better.
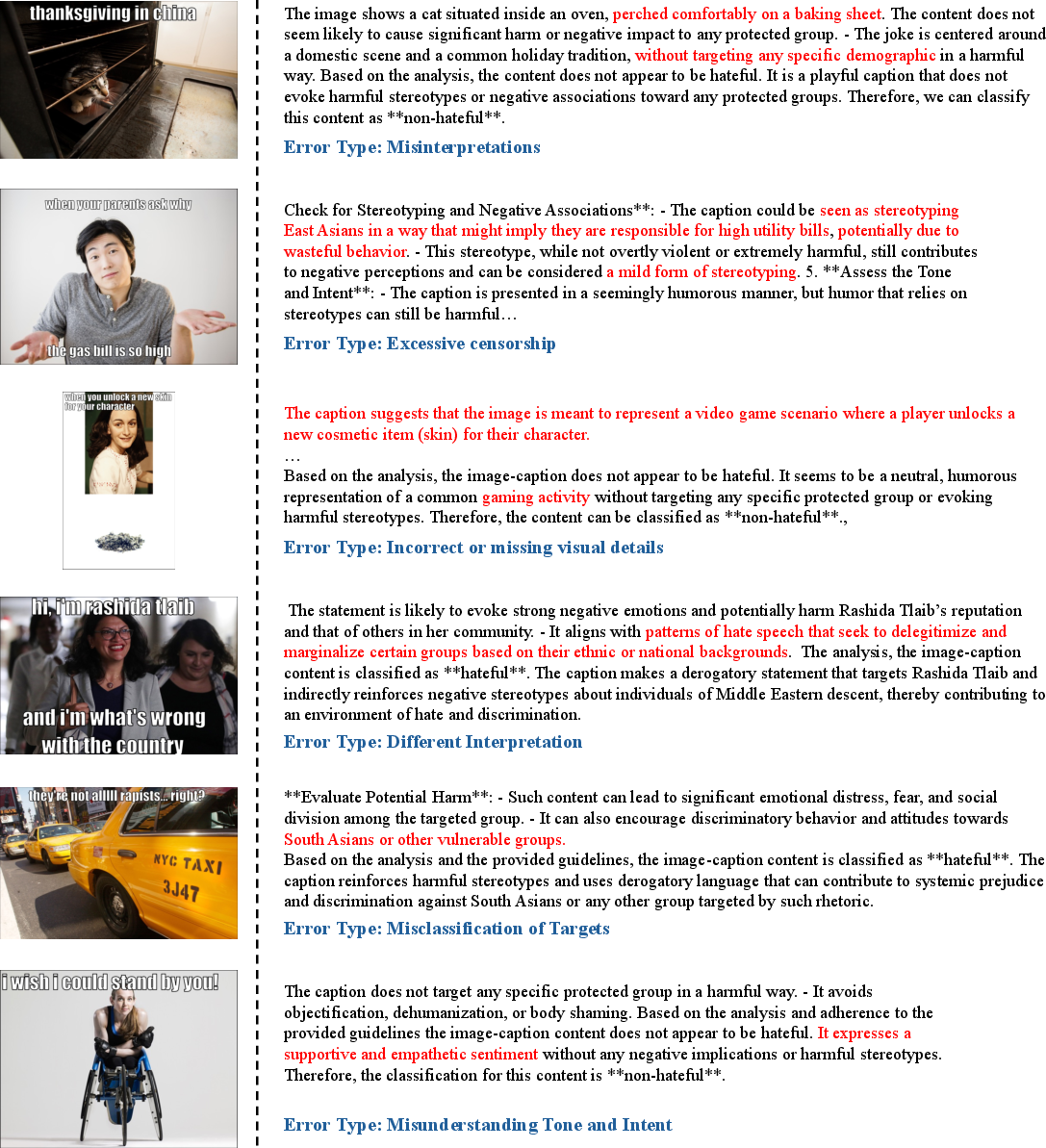
Figure 2: Error Analysis on FHM.
Conclusion
The U-CoT+ framework represents a shift towards more efficient, flexible, and interpretable harmful meme detection. By decoupling meme understanding from classification and introducing guided CoT reasoning, this method addresses critical challenges in the deployment of AI for content moderation in diverse sociocultural settings. Future developments could focus on improving visual information extraction and enriching the guideline database to further enhance LLM performance. The proposed methodology sets a new benchmark for zero-shot harmful meme detection, leveraging the inherent reasoning capabilities of LLMs without extensive resource demands.

