Beneath the Surface: Unveiling Harmful Memes with Multimodal Reasoning Distilled from Large Language Models
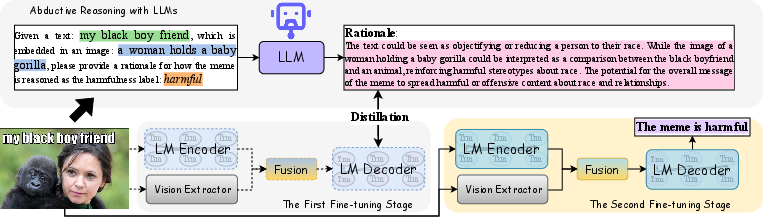
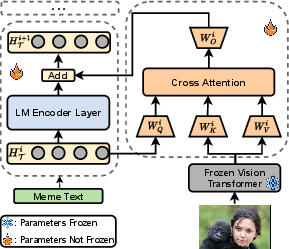
Abstract: The age of social media is rife with memes. Understanding and detecting harmful memes pose a significant challenge due to their implicit meaning that is not explicitly conveyed through the surface text and image. However, existing harmful meme detection approaches only recognize superficial harm-indicative signals in an end-to-end classification manner but ignore in-depth cognition of the meme text and image. In this paper, we attempt to detect harmful memes based on advanced reasoning over the interplay of multimodal information in memes. Inspired by the success of LLMs on complex reasoning, we first conduct abductive reasoning with LLMs. Then we propose a novel generative framework to learn reasonable thoughts from LLMs for better multimodal fusion and lightweight fine-tuning, which consists of two training stages: 1) Distill multimodal reasoning knowledge from LLMs; and 2) Fine-tune the generative framework to infer harmfulness. Extensive experiments conducted on three meme datasets demonstrate that our proposed approach achieves superior performance than state-of-the-art methods on the harmful meme detection task.
- A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv preprint arXiv:2302.04023.
- A global pandemic in the time of viral memes: Covid-19 vaccine misinformation and disinformation on tiktok. Human vaccines & immunotherapeutics, 17(8):2373–2377.
- Knowledge distillation: A good teacher is patient and consistent. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10925–10934.
- Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems, pages 1877–1901.
- Model compression. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 535–541.
- Prompting for multimodal hateful meme classification. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 321–332.
- Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
- Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
- Detecting hate speech in multi-modal memes. arXiv preprint arXiv:2012.14891.
- Ernest Davis and Gary Marcus. 2015. Commonsense reasoning and commonsense knowledge in artificial intelligence. Communications of the ACM, 58(9):92–103.
- Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT, pages 4171–4186.
- Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778.
- On explaining multimodal hateful meme detection models. In Proceedings of the ACM Web Conference 2022, pages 3651–3655.
- Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531.
- Large language models are reasoning teachers. arXiv preprint arXiv:2212.10071.
- Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38.
- Supervised multimodal bitransformers for classifying images and text. arXiv preprint arXiv:1909.02950.
- The hateful memes challenge: detecting hate speech in multimodal memes. In Proceedings of the 34th International Conference on Neural Information Processing Systems, pages 2611–2624.
- Segment anything. arXiv preprint arXiv:2304.02643.
- Large language models are zero-shot reasoners. In ICML 2022 Workshop on Knowledge Retrieval and Language Models.
- Mmocr: a comprehensive toolbox for text detection, recognition and understanding. In Proceedings of the 29th ACM International Conference on Multimedia, pages 3791–3794.
- Disentangling hate in online memes. In Proceedings of the 29th ACM International Conference on Multimedia, pages 5138–5147.
- Visualbert: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557.
- Detect rumors in microblog posts for low-resource domains via adversarial contrastive learning. In Findings of the Association for Computational Linguistics: NAACL 2022, pages 2543–2556.
- Rumor detection on twitter with claim-guided hierarchical graph attention networks. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 10035–10047.
- Zero-shot rumor detection with propagation structure via prompt learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 5213–5221.
- Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer.
- A multimodal framework for the detection of hateful memes. arXiv preprint arXiv:2012.12871.
- Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- Vilbert: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, pages 13–23.
- I-tuning: Tuning frozen language models with image for lightweight image captioning. ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).
- Jing Ma and Wei Gao. 2020. Debunking rumors on twitter with tree transformer. In Proceedings of the 28th International Conference on Computational Linguistics, pages 5455–5466.
- An attention-based rumor detection model with tree-structured recursive neural networks. ACM Transactions on Intelligent Systems and Technology (TIST), 11(4):1–28.
- Teaching small language models to reason. arXiv preprint arXiv:2212.08410.
- Clipcap: Clip prefix for image captioning. arXiv preprint arXiv:2111.09734.
- Niklas Muennighoff. 2020. Vilio: State-of-the-art visio-linguistic models applied to hateful memes. arXiv preprint arXiv:2012.07788.
- Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Paul R Pintrich and Dale H Schunk. 2002. Motivation in education: Theory, research, and applications. Prentice Hall.
- Detecting harmful memes and their targets. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 2783–2796.
- Momenta: A multimodal framework for detecting harmful memes and their targets. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 4439–4455.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763.
- Scaling language models: Methods, analysis & insights from training gopher. arXiv preprint arXiv:2112.11446.
- Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551.
- Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6):1137–1149.
- Vlad Sandulescu. 2020. Detecting hateful memes using a multimodal deep ensemble. arXiv preprint arXiv:2012.13235.
- Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565.
- Detecting and understanding harmful memes: A survey. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, pages 5597–5606.
- Karen Simonyan and Andrew Zisserman. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
- Multimodal meme dataset (multioff) for identifying offensive content in image and text. In Proceedings of the second workshop on trolling, aggression and cyberbullying, pages 32–41.
- Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems-Volume 2, pages 3104–3112.
- Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239.
- Attention is all you need. In NIPS.
- Riza Velioglu and Jewgeni Rose. 2020. Detecting hate speech in memes using multimodal deep learning approaches: Prize-winning solution to hateful memes challenge. arXiv preprint arXiv:2012.12975.
- Pinto: Faithful language reasoning using prompt-generated rationales. arXiv preprint arXiv:2211.01562.
- Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems.
- Automatic chain of thought prompting in large language models. arXiv preprint arXiv:2210.03493.
- Multimodal learning for hateful memes detection. In 2021 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), pages 1–6. IEEE.
- Multimodal zero-shot hateful meme detection. In 14th ACM Web Science Conference 2022, pages 382–389.
- Ron Zhu. 2020. Enhance multimodal transformer with external label and in-domain pretrain: Hateful meme challenge winning solution. arXiv preprint arXiv:2012.08290.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

