- The paper introduces DiffEmbed, a diffusion-based method that leverages bidirectional attention for superior text embeddings compared to autoregressive LMs.
- The evaluation shows that DiffEmbed significantly outperforms traditional LLM-based models in long-document and reasoning-intensive retrieval tasks.
- The study underscores the value of architectural alignment in embedding tasks and highlights opportunities for future research in bidirectional model architectures.
Diffusion vs. Autoregressive LLMs: A Text Embedding Perspective
Introduction
The paper "Diffusion vs. Autoregressive LLMs: A Text Embedding Perspective" (2505.15045) introduces a novel approach to text embeddings using diffusion LMs. Traditional models like BERT and T5 employ bidirectional architectures, whereas LLMs use unidirectional autoregressive pre-training, misaligning with embedding tasks requiring bidirectional context understanding. Diffusion LMs address this through both forward and reverse attention mechanisms, surpassing LLM-based models in long-document and reasoning-intensive retrieval tasks by substantial margins.
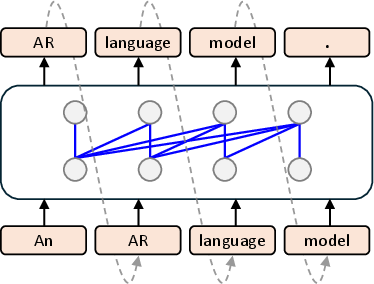
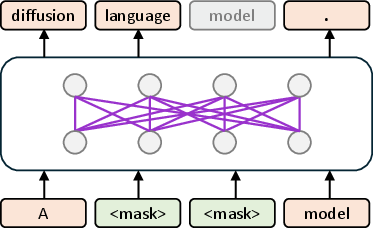
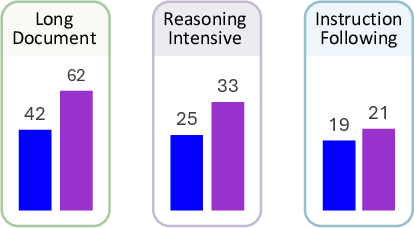
Figure 1: Autoregressive Modelling.
Background
Text Embedding Models
Text embedding models create low-dimensional representations of text, essential for tasks like document retrieval and clustering. Traditional models rely on contextual embeddings generated by bidirectional models such as BERT, fine-tuned through contrastive learning to enhance semantic similarity.
Diffusion LLMs
Diffusion models excel in generative tasks by iteratively refining noisy inputs, a method translatable to text via bidirectional attention mechanisms. Traditionally used in image generation, these models outperform autoregressive approaches by better capturing bidirectional semantics. The paper's diffusion LM leverages a discrete diffusion process, refining text embeddings through masking and unmasking steps.
Figure 2: Overview of DiffEmbed. Final-layer token representations from the backbone diffusion LM are mean-pooled to obtain text embeddings.
Diffusion Embedding Model
DiffEmbed applies diffusion processes to text embedding, inherently supporting bidirectional context. Unlike LLM embeddings, which rely on causal attention, DiffEmbed uses a denoising objective to refine token representations. This makes it more adept at encoding global context, especially in long and complex documents.
Evaluating Text Embedding Models
The paper evaluates DiffEmbed against LLM-based models across various retrieval tasks:
Long-Document Retrieval
DiffEmbed demonstrates superior performance in encoding long documents due to its ability to capture global context through bidirectional attention.
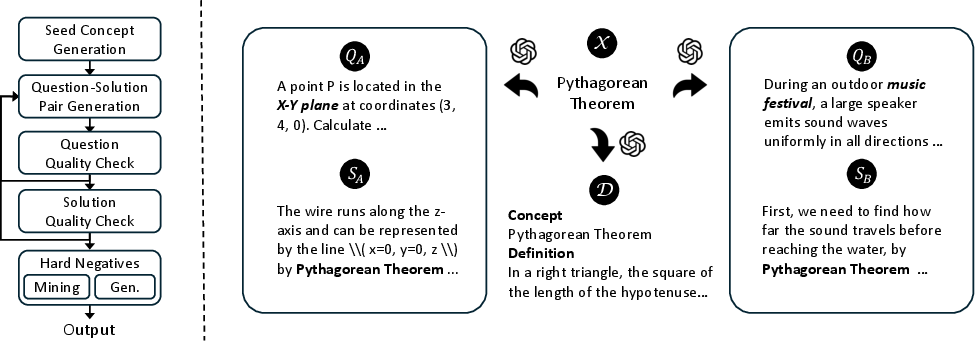
Figure 3: Left: data augmentation pipeline. Right: qualitative examples of seed concepts, their definitions, and associated question–solution pairs.
Reasoning-Intensive Retrieval
During reasoning-intensive retrieval tasks, DiffEmbed outperforms competitors by leveraging the bidirectional architecture to better process logical relationships and complex theorems.
Instruction-Following Retrieval
DiffEmbed's architecture also enhances instruction-following tasks by aligning model understanding with contextual cues, achieving comparable performance to leading models.
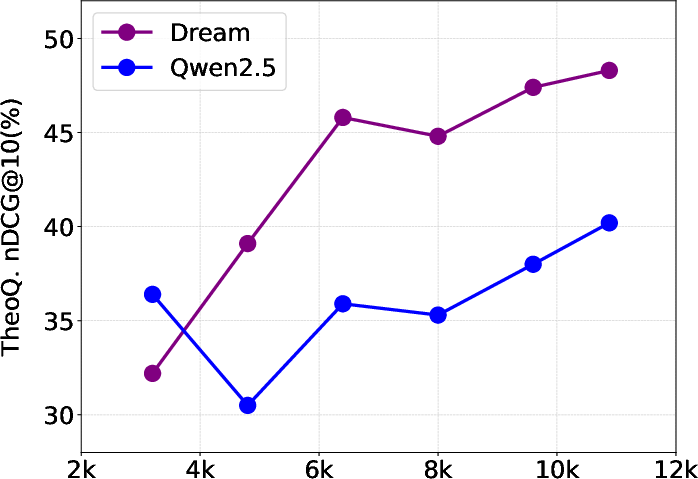
Figure 4: Retrieval performance on TheoQ. for Dream and Qwen2.5 models trained with varying amounts of ReasonAug data.
General Text Embedding Tasks
Despite minimal improvements in traditional tasks, DiffEmbed maintains competitive performance due to its effective bidirectional processing.
Discussion and Insights
DiffEmbed's success underscores the importance of architectural alignment with task requirements, particularly in capturing global context. The evaluation reveals that bidirectional attention is crucial for achieving high performance across diverse embedding tasks.
Conclusion
This research highlights diffusion LLMs' potential in transforming text embedding strategies, offering enhanced bidirectional contextual understanding. By evaluating DiffEmbed's performance across varied tasks, the paper provides valuable insights into the advantages of diffusion-based embeddings over traditional LLM-based approaches.

Figure 5: E5-Mistral without ReasonAug fine-tuning.
Figure 6: The concept color mapping for \Cref{fig:t-sne}.
Through leveraging diffusion processes, DiffEmbed can efficiently improve text embedding tasks, laying groundwork for future exploration in bidirectional LM architectures.