- The paper introduces the LRSA model that integrates LLM-generated rationales with SLMs, achieving state-of-the-art performance on MABSA benchmarks.
- It employs a dual cross-attention mechanism to fuse visual and textual features with structured rationales, improving aspect extraction and sentiment prediction.
- Ablation studies confirm that optimized rationale generation and prompt engineering are critical for balancing noise and enhancing model accuracy.
Enhanced Multimodal Aspect-Based Sentiment Analysis by LLM-Generated Rationales: A Technical Summary
Introduction and Context
Multimodal Aspect-Based Sentiment Analysis (MABSA) seeks to extract aspect terms and their associated sentiments from paired image-text data—such as tweets containing both text and images. Despite notable progress in multimodal representation learning, the fine-grained interplay between modalities presents unresolved challenges, particularly in localizing aspect-relevant content, mitigating cross-modal noise, and reasoning about subtle connections across modalities.
Traditional approaches predominantly leverage pre-trained small LLMs (SLMs) with ad hoc modules for multimodal alignment. These methods are fundamentally limited by the SLMs’ restricted capacity for knowledge integration, ultimately impairing their performance when semantics are highly nuanced or contextually ambiguous. Attempts to augment SLMs with simple image captions (e.g., via ClipCap) offer insufficient grounding, as such captions rarely pertain directly to aspect-level sentiment. LLMs excel at sophisticated multimodal reasoning but, when used directly, often underperform relative to specialized, fine-tuned SLMs on ABSA-style tasks due to sub-optimal integration with task-specific signals and an inability to tightly couple fine-grained visual and textual cues.
Proposed Framework: LRSA Architecture
The paper introduces LRSA, an aspect-oriented model that synthesizes the reasoning strengths of LLMs with the efficiency and adaptability of SLMs for the MABSA problem domain. The central innovation lies in using rationales—structured explanations regarding image and text content—generated via a state-of-the-art multimodal LLM (Google Gemini-1.5 Pro), which are then injected as auxiliary features into SLMs during training and inference.
The process involves several key steps:
- Rationale Extraction: Image-text pairs are input to an LLM, which produces natural language rationales for both the image and the text, designed to highlight aspect- and sentiment-relevant information (Figure 1).
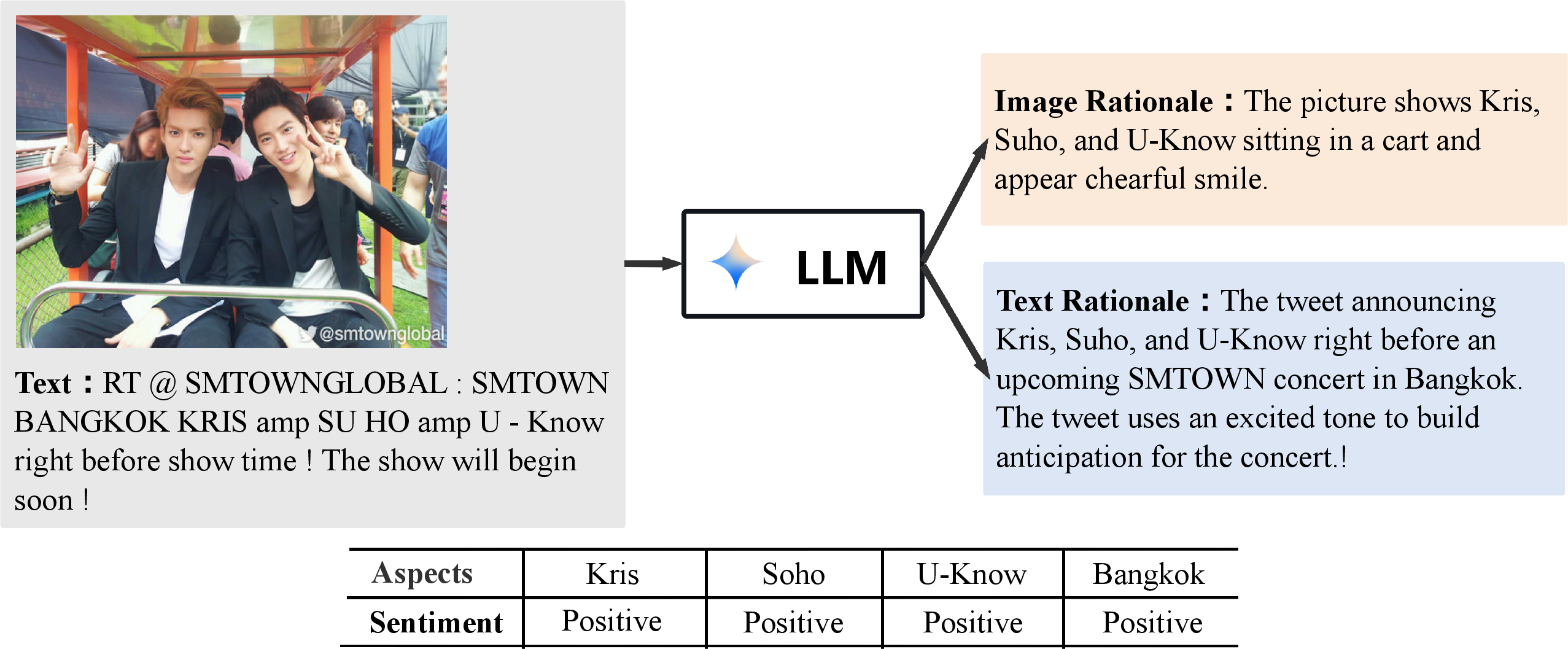
Figure 1: The LLM produces explanatory rationales for both image and text components of an input pair, emphasizing relevant connections for downstream sentiment analysis.
- Multimodal Feature Fusion: The SLM (here, BART-based variants—VLP and AoM) takes as input a concatenation of raw image-text data and LLM-generated rationales. Advanced token types demarcate boundaries of images, text, and rationale subsequences.
- Dual Cross-Attention Module: To address the alignment of rationale with visual and textual streams, a dual cross-attention mechanism integrates image features with image rationales, and textual features with text rationales, capturing intra- and cross-modal dependencies necessary for robust aspect extraction and sentiment inference (Figure 2).
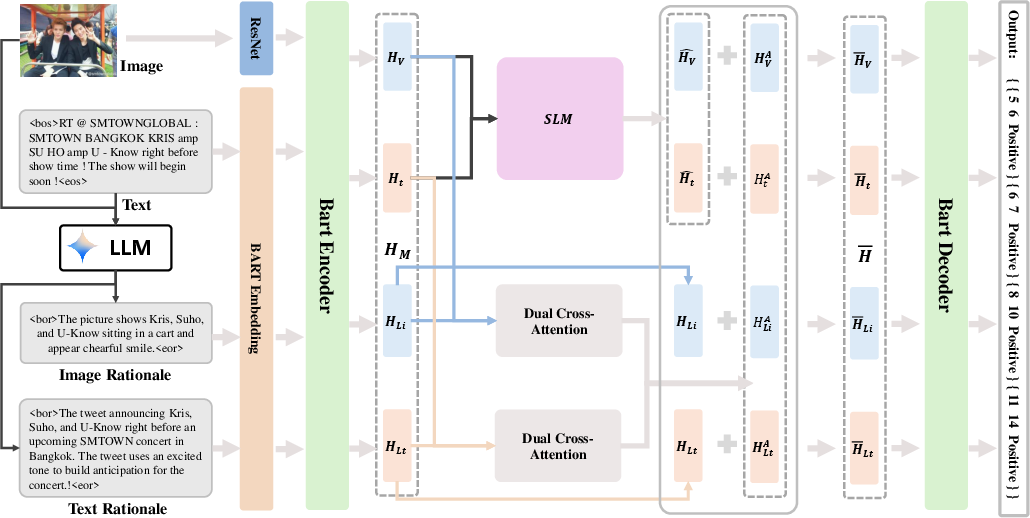
Figure 2: LRSA model architecture showing rationale extraction, dual cross-attention fusion, and decoding for MABSA prediction.
- Decoder Integration: In the final prediction stage, decoded representations are built from a fusion of attended multimodal features and rationales, further informing aspect identification and sentiment judgment.
Experimental Results
LRSA’s efficacy was evaluated on standard MABSA datasets (Twitter2015, Twitter2017) using SLMs (VLP and AoM) as baselines, and against leading state-of-the-art approaches across sub-tasks: MABSA, Multimodal Aspect Term Extraction (MATE), and Multimodal Aspect-based Sentiment Classification (MASC).
Main empirical findings include:
- Superior F1 Performance: LRSA with VLP yields a 1.6% gain in F1 on Twitter2015 and 1.2% on Twitter2017 relative to VLP-MABSA; AoM-based LRSA exhibits similar improvements. These results consistently outperform both unimodal and multimodal baselines across all metrics and settings.
- Ablation Studies: The dual cross-attention mechanism is critical. Removal or reduction in attention results in measurable performance degradation. Exclusion of rationale concatenation at the decoding phase further weakens predictive accuracy, confirming the utility of rationale injection in both representation and prediction stages.
- Prompts and Rationale Generation: Carefully designed prompts in the LLM are essential. Prompts that focus LLM generation on aspect relevance and sentiment, without requiring explicit sentiment classification, result in optimal rationale quality and downstream model performance. Performance peaks when the length of rationales is approximately twice the total length of the text-image inputs; excessive rationale length adds noise and diminishes returns.
Theoretical and Practical Implications
The methodological advancement in LRSA is twofold:
- It demonstrates that the complementary integration of LLM-synthesized rationales—not merely image captions but targeted, task-aware explanations—with SLM prediction chains is an effective strategy for high-precision multimodal aspect-based sentiment analysis.
- The dual cross-attention mechanism provides an efficient, scalable method for aligning external rationale streams with multimodal input spaces, thus enabling SLMs to leverage external world knowledge and structured explanations without introducing spurious correlations or information overload.
Practically, LRSA’s architecture is generalizable to any sequence-to-sequence multimodal model capable of ingesting external rationale streams, and the rationale-generation phase is modular and independent. The modularity readily accommodates advances in both LLM capability and vision-language pretraining paradigms.
Future Directions
This work opens promising avenues for further inquiry:
- LLM Prompt Engineering: Systematic study of rationale quality—e.g., context, specificity, and objectivity—in the context of auxiliary supervision.
- Extensibility to Other Multimodal Tasks: Application to entity recognition, event extraction, and other tasks where LLM explanations can bolster fine-grained reasoning.
- End-to-End Fine-Tuning: Joint optimization of LLM rationale generation and SLM downstream learning, possibly via reinforcement learning or prompt tuning.
- Scaling to Noisy or User-Generated Content: Investigating robustness when image-text pairs are ambiguous, adversarial, or out-of-domain.
Conclusion
This paper provides a rigorous framework for augmenting SLMs with LLM-generated rationales to address the shortcomings of standalone LLMs in fine-grained multimodal sentiment analysis. Through an aspect-oriented, cross-attentive fusion of external explanations and raw data, LRSA achieves state-of-the-art performance on challenging MABSA benchmarks, establishing a blueprint for future systems that seek to combine the explicit reasoning power of LLMs with the efficiency and adaptability of specialized task models (2505.14499).