- The paper presents a novel framework that augments multimodal sentiment analysis by integrating contextual world knowledge with a training-free mechanism.
- It leverages large vision-language models and prompt templates to generate and fuse relevant context, improving performance on benchmarks like Twitter2015 and Twitter2017.
- Experimental results demonstrate nearly 2% F1 score improvements, highlighting the framework's robustness and adaptability across diverse sentiment analysis tasks.
WisdoM: Improving Multimodal Sentiment Analysis by Fusing Contextual World Knowledge
Introduction
The development of multimodal sentiment analysis (MSA) has traditionally relied on surface-level data extracted from text and images. However, these methods often overlook the importance of contextual world knowledge, which can enrich sentiment analysis by providing deeper insights beyond the immediate content of the input data. "WisdoM: Improving Multimodal Sentiment Analysis by Fusing Contextual World Knowledge" proposes a novel approach that leverages large vision-LLMs (LVLMs) to incorporate such contextual knowledge, thus improving the performance of MSA tasks.
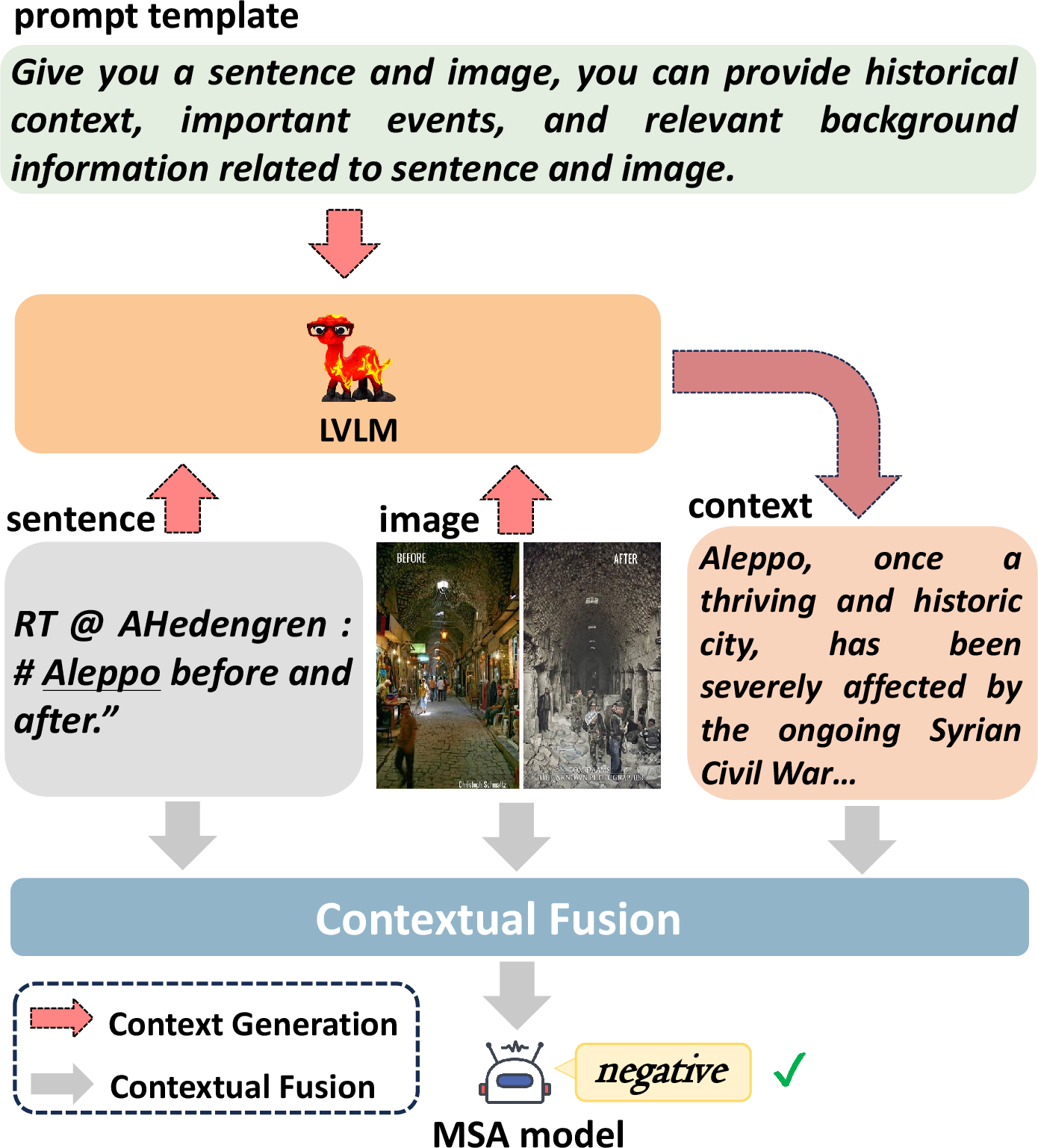
Figure 1: The simple schematic of our method. The sentiment polarity of Aleppo is negative, which existing methods fail to predict accurately without incorporating context.
Methodology
The WisdoM framework is a plug-in solution designed to enhance MSA by integrating contextual world knowledge through a series of structured stages:
- Prompt Templates Generation: Leveraging LLMs like ChatGPT to generate prompts that guide LVLMs in generating relevant context.
- Context Generation: Utilizing LVLMs to produce contextual information that complements the input data by providing background knowledge.
- Contextual Fusion: Implementing a training-free mechanism that selectively incorporates context into the analysis, reducing noise and enhancing accuracy.
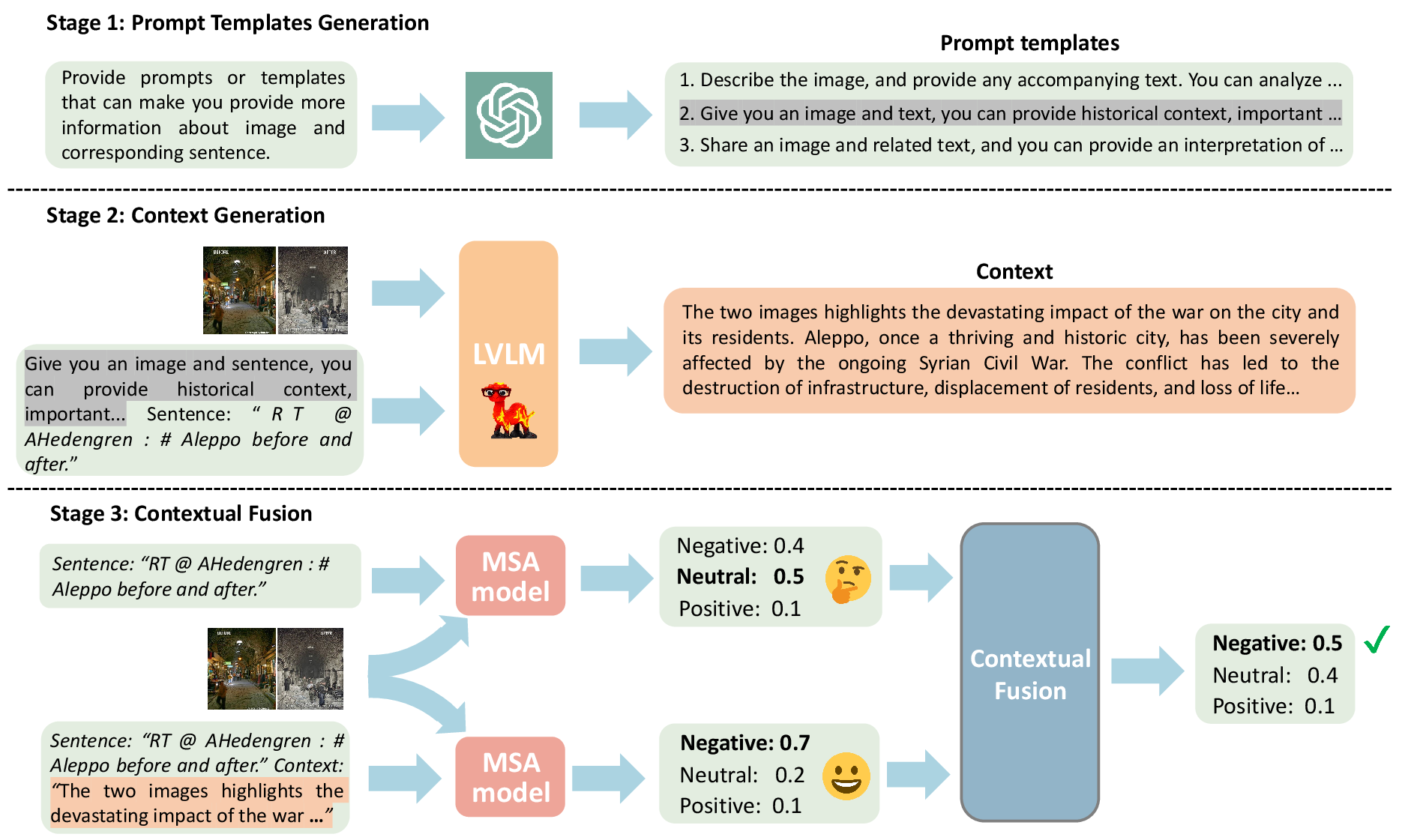
Figure 2: Detailed illustration of our proposed schema with a running example.
Experimental Analysis
The proposed methodology was rigorously tested against multiple benchmarks, such as Twitter2015, Twitter2017, and MSED, demonstrating an average improvement of +1.96% in F1 scores compared to state-of-the-art methods.
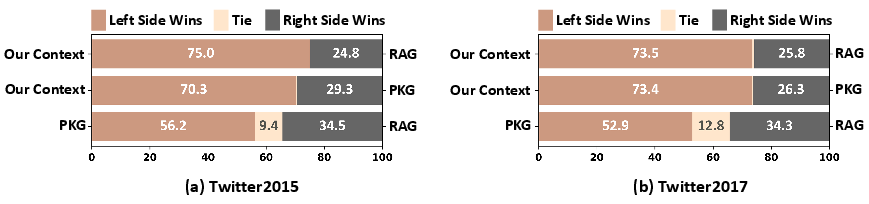
Figure 3: Comparative winning rates of Our Context v.s. RAG-based methods on Twitter2015 and Twitter2017 benchmarks.
Results and Discussion
WisdoM shows significant enhancements in sentiment analysis performance, particularly in scenarios requiring deep context comprehension. The use of historical and cultural knowledge stands out as particularly beneficial when addressing sentiment-laden subjects embedded in broader narratives.
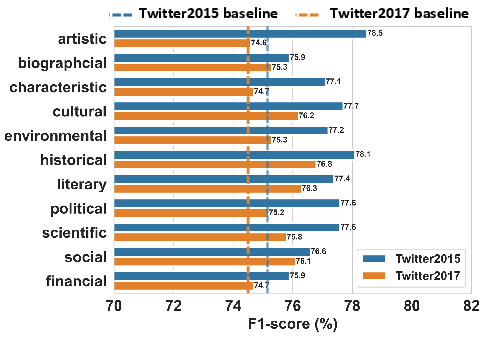
Figure 4: Effects of different types of world knowledge on the F1-score by applying WisdoM to AoM.
Performance improvements were consistent across different model architectures, indicating the robustness and adaptability of WisdoM. The integration of context not only increased sentiment classification accuracy but also demonstrated effective disambiguation in challenging samples previously considered hard by state-of-the-art models.
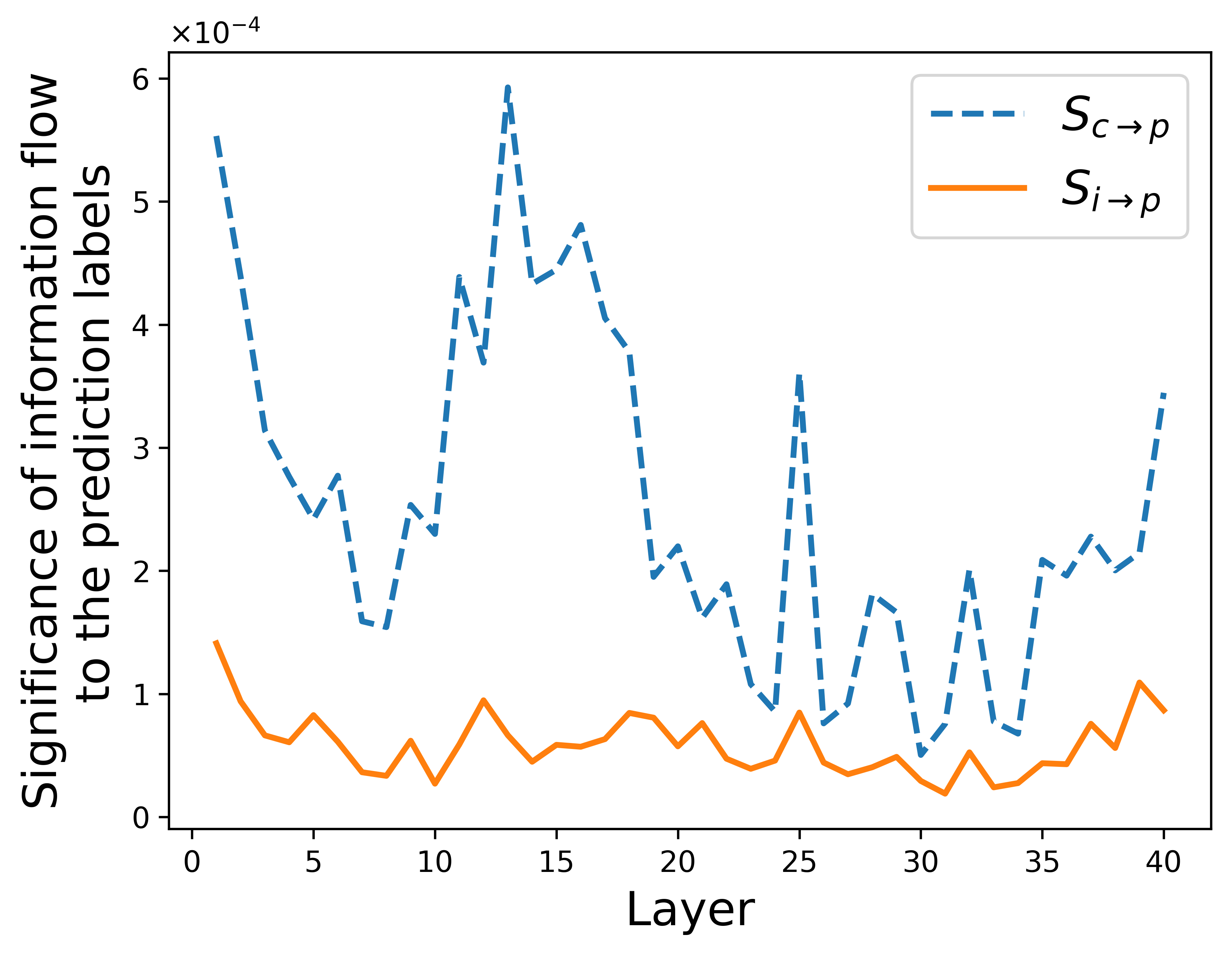
Figure 5: Comparison of context (Sc→p) and input's (Si→p) correlation to final predictions across layers.
Conclusion
WisdoM exemplifies the potential for enhanced MSA by utilizing contextual world knowledge, demonstrating notable improvements in both aspect-level and sentence-level sentiment analysis tasks. As AI continues to evolve, methodologies like WisdoM pave the way for more nuanced and contextually aware systems capable of deeper understanding and more accurate sentiment evaluation.
By incorporating nuanced context, WisdoM addresses limitations present in traditional MSA frameworks, providing an efficient, scalable, and adaptable solution that enhances sentiment analysis capabilities across diverse datasets.