- The paper introduces a novel method for measuring unintended memorization in language models using Kolmogorov complexity and information theory.
- It demonstrates that models store between 3.5 and 4 bits per parameter, validated through synthetic and real data experiments.
- The study reveals that exceeding model capacity triggers a double descent effect, complicating membership inference attacks.
Measuring LLM Memorization and Capacity
This paper introduces a novel methodology for quantifying memorization in LLMs, distinguishing between unintended memorization of specific data points and generalization of underlying patterns. It leverages concepts from Kolmogorov complexity and Shannon information theory to provide a practical measure of model capacity and its relationship to dataset size.
Defining and Measuring Memorization
The study addresses the challenge of differentiating memorization from generalization by decomposing it into two components: unintended memorization, which is the information retained about a specific dataset, and generalization, which is the knowledge acquired about the underlying data-generating process. The authors practically measure instance-level memorization using algorithmic definitions of information. They define Kolmogorov memorization as:
memUK(x,θ,θ^)=HK(x∣θ)−HK(x∣(θ,θ^))
where HK denotes Kolmogorov complexity, θ is a reference model, and θ^ is the trained model. This approach allows for the quantification of how much a model "knows" about a specific data point by measuring the compression rate achieved when the model is available.
To estimate Kolmogorov complexity, the authors use arithmetic coding and model likelihoods. Specifically, HK(x∣θ^) is approximated by −log(p(x∣θ^)), where p(x∣θ^) is the likelihood of input x under the target model θ^.
Model Capacity and Synthetic Data Experiments
The paper defines model capacity as the maximum amount of memorization that can be stored in a model across all its parameters. To measure this, the authors train LLMs on datasets of uniformly sampled bitstrings, eliminating the possibility of generalization. By training on synthetic sequences from a uniform distribution, the Shannon information can be computed exactly by H(xi)=NSlog2V, where N is the dataset size, S is the sequence length, and V is the vocabulary size.
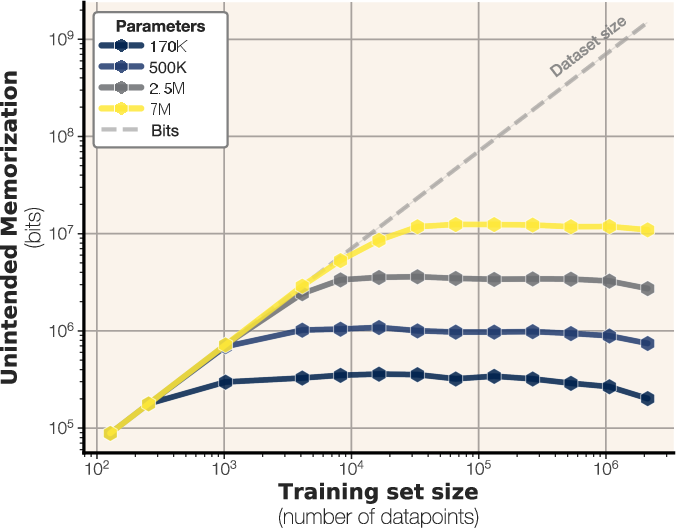
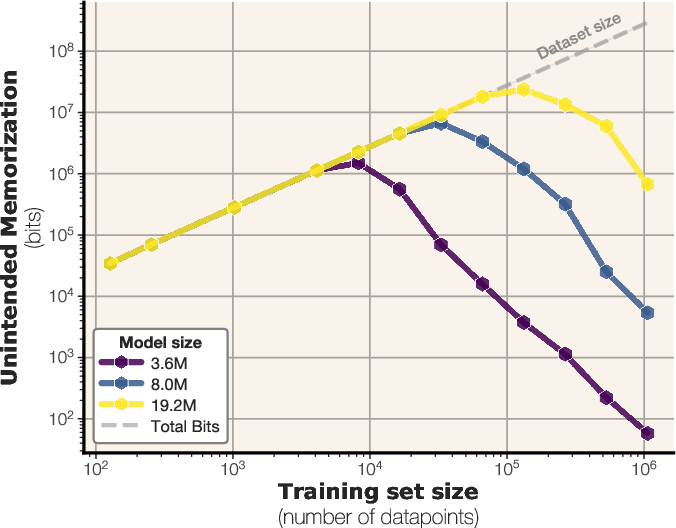
Figure 1: Unintended memorization of uniform random data as a function of dataset size for various model sizes, with a plateau indicating the empirical capacity limit of approximately 3.6 bits-per-parameter.
The experiments reveal that GPT-style transformers can store between 3.5 and 4 bits of information per parameter. This finding corroborates prior work such as \citep{roberts2020knowledgepackparameterslanguage,lu2024scalinglawsfactmemorization}, which noticed that fact storage scales linearly with model capacity. The study also investigates the impact of precision on model capacity, finding that increasing precision from bfloat16 to float32 results in a relatively small increase in capacity, from 3.51 to 3.83 bits per parameter on average.
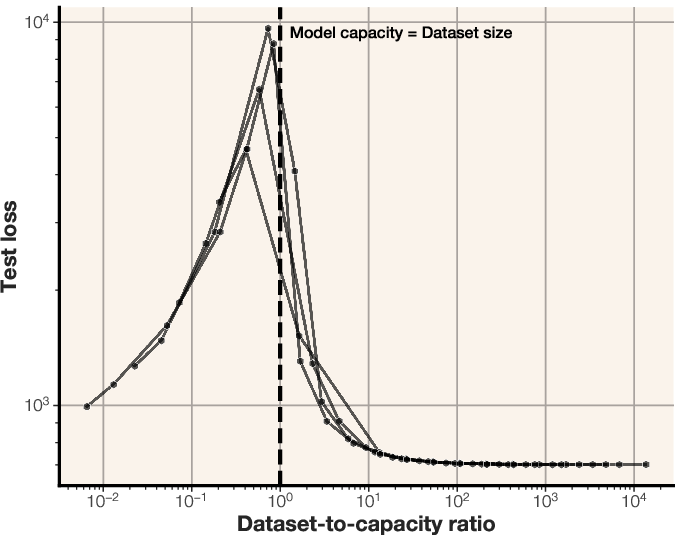
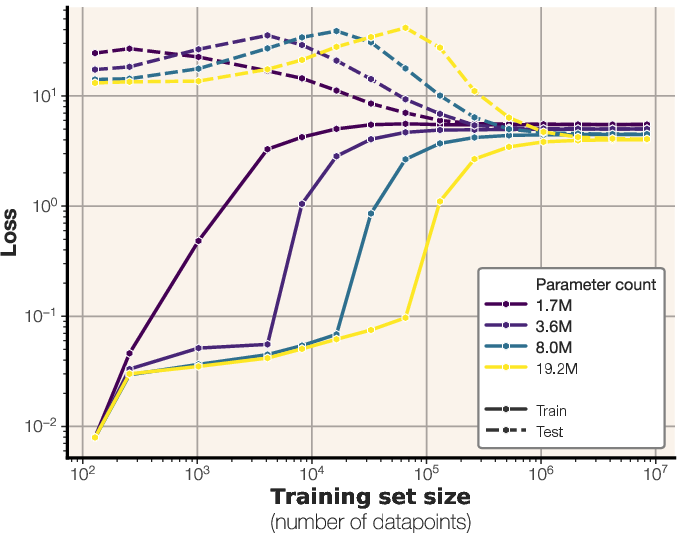
Figure 2: Unintended memorization of text as a function of model and dataset sizes, calculated with respect to a large oracle model.
Memorization, Generalization, and Double Descent
The study extends its analysis to real text data, where both unintended memorization and generalization are possible. The experiments demonstrate that models initially memorize data up to their capacity, after which they begin to generalize. This transition from memorization to generalization coincides with the onset of the double descent phenomenon, which occurs when the dataset size exceeds the model capacity in bits. The dataset-to-capacity ratio accurately predicts the double descent phenomenon [belkin2019biasvariance, nakkiran2019deepdoubledescentbigger]. Double descent begins exactly when the data capacity exceeds the model capacity.
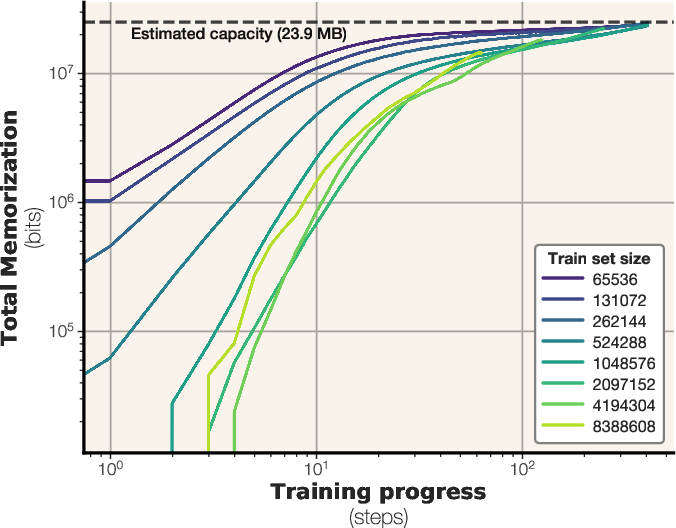
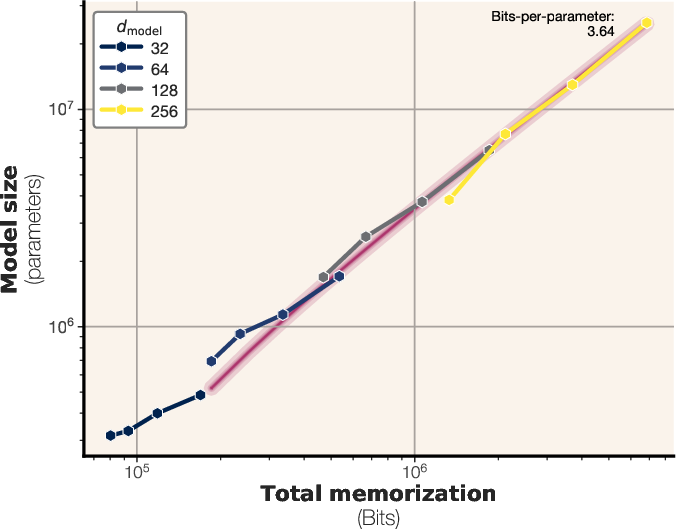
Figure 3: The number of bits memorized across training steps for a GPT-style transformer with 6.86M parameters and a capacity of 23.9 MB.
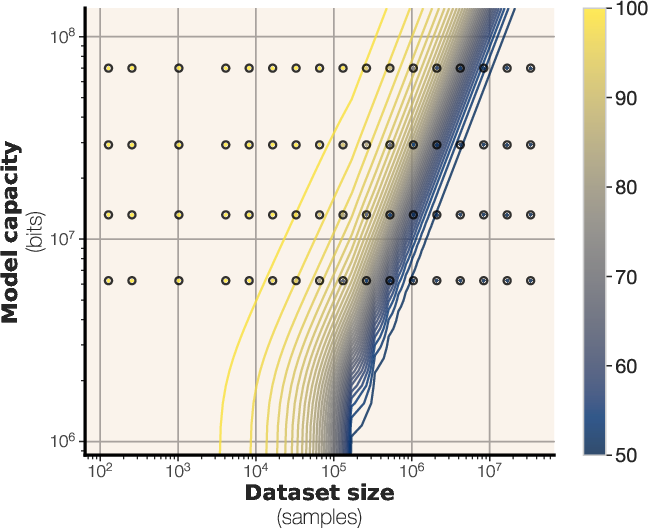
Figure 4: Membership inference scaling laws, showing the F1 score as a function of tokens per parameter, overlaid with empirical data.
Membership Inference and Scaling Laws
The authors derive a scaling law for membership inference performance based on model capacity and dataset size. By fitting a sigmoidal function to empirical data, the study predicts the F1 score of a loss-based membership inference attack. The results suggest that larger models can memorize more samples, while increasing dataset size makes membership inference more challenging. The scaling laws extrapolate to larger models and predict that many modern LLMs are trained on too much data for reliable membership inference on the average data point. The scaling law is expressed as:
MembershipF1(θ,D)=21(1+c1σ(c2(∣D∣Capacity(θ)+c3))
where σ(x)=1+e−x1, and c1,c2,c3 are constants fitted to the data.
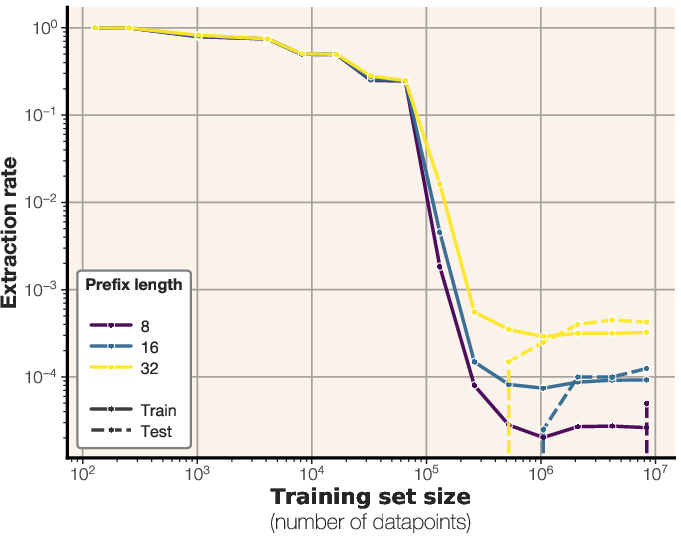
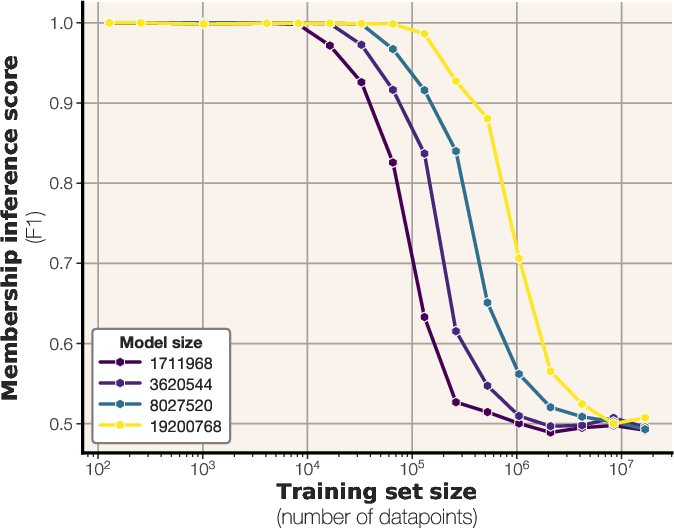
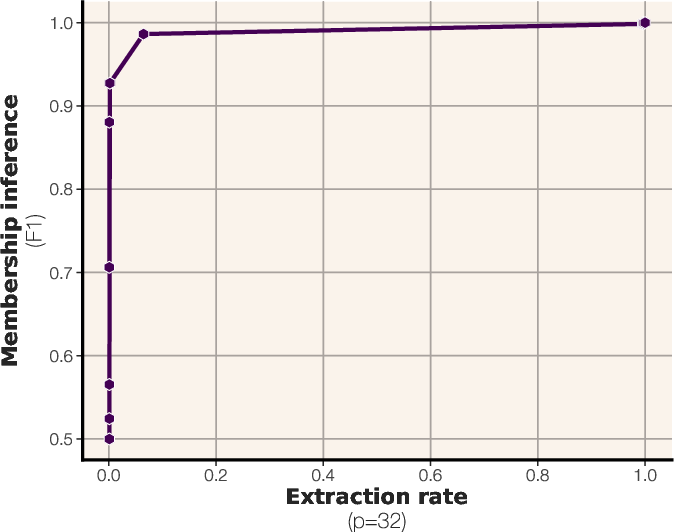
Figure 5: Extraction rates of 64-token training sequences across prefix lengths, for both train and evaluation datasets.
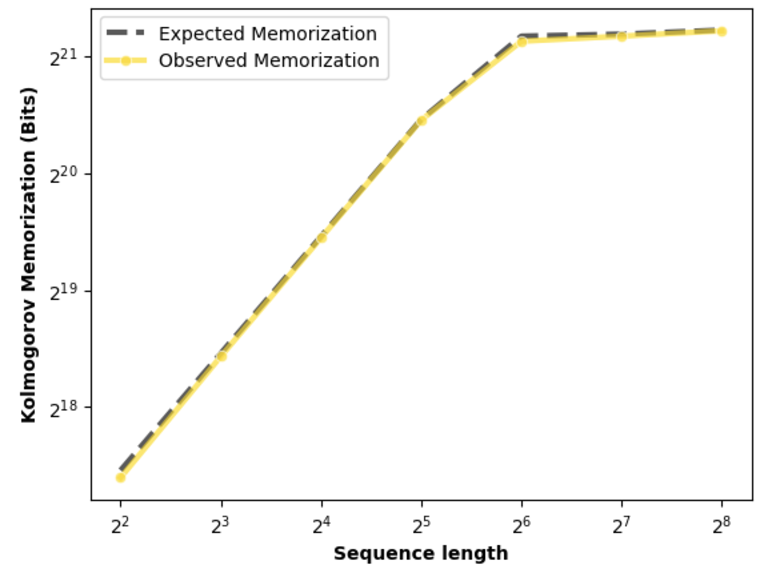
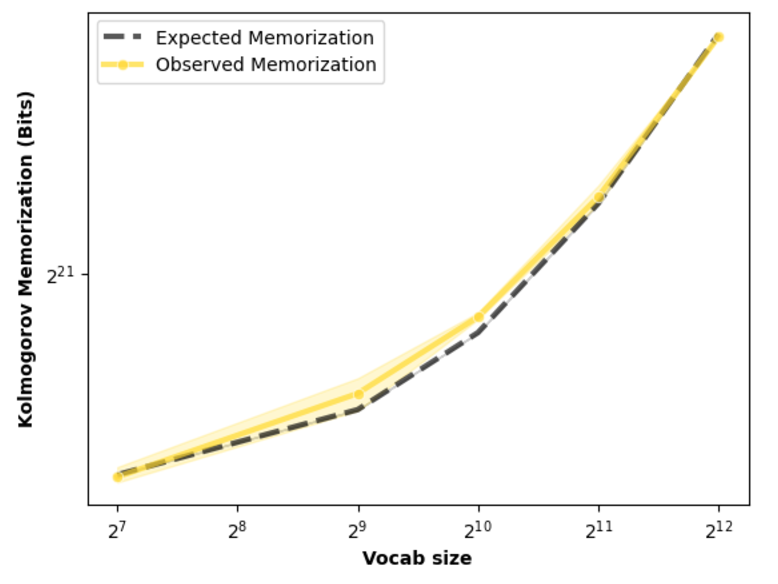
Figure 6: Model memorization across sequence lengths for a fixed-length dataset, demonstrating the accuracy of the total memorization predictions.
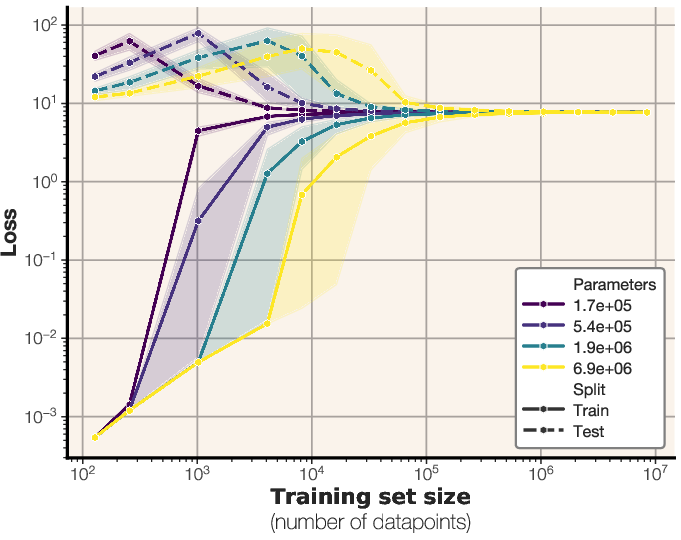
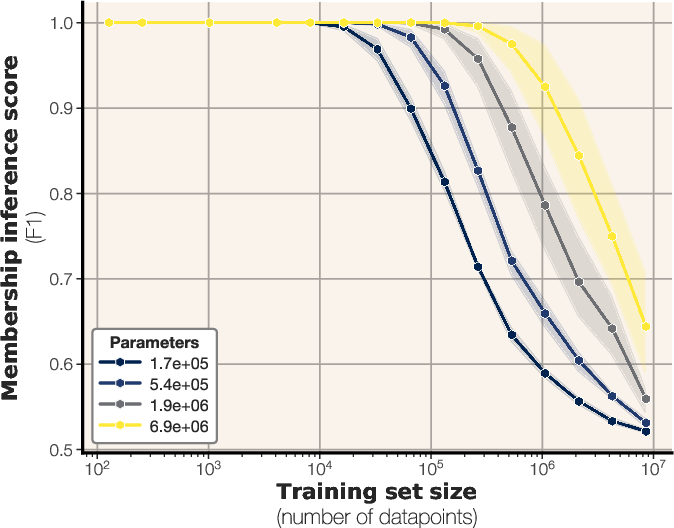
Figure 7: Train and test losses for different-sized LLMs trained on synthetic data, illustrating the relationship between model size, dataset size, and generalization performance.
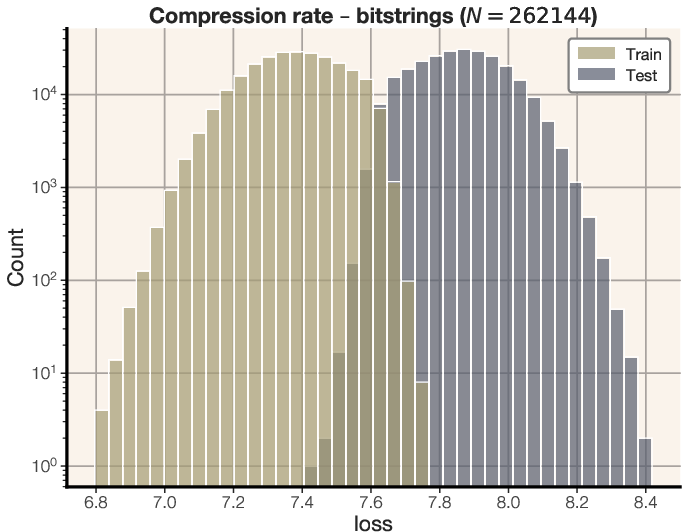
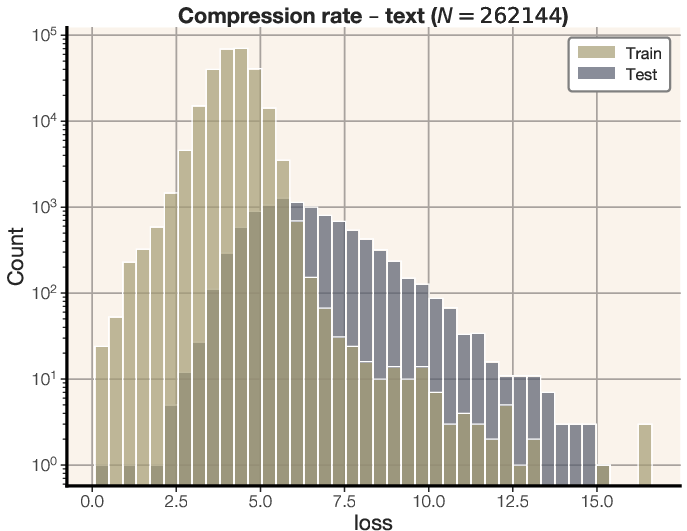
Figure 8: Distribution of compression rates for equal-sized transformers trained on random bitstrings and text.
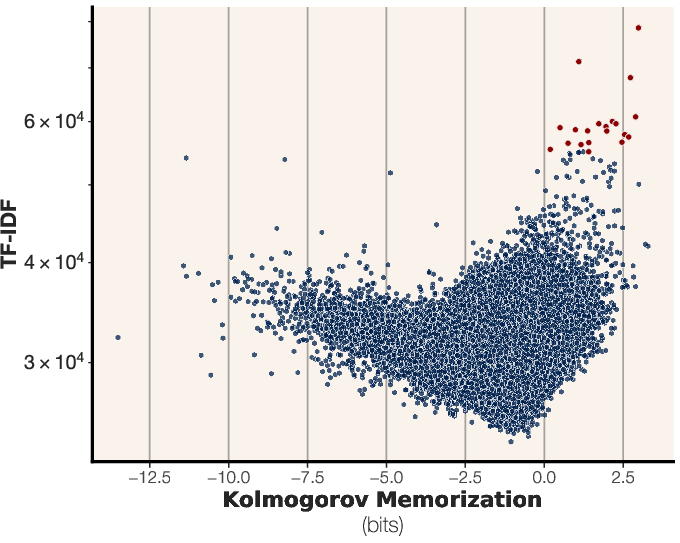
Figure 9: Unintended memorization versus TF-IDF for all training points of a 20M parameter model trained past its capacity on sequences of English text.
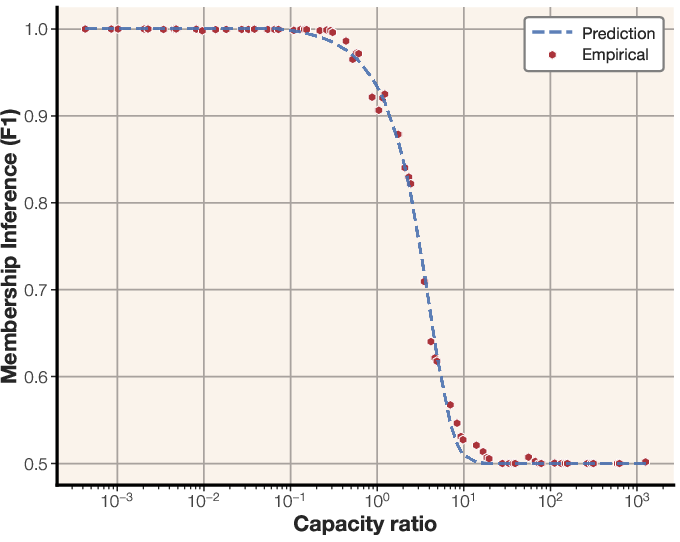
Figure 10: Sigmoidal scaling law for membership inference, fitted to empirical data to predict performance based on tokens per parameter.
Conclusion
This paper offers a comprehensive framework for understanding and measuring memorization in LLMs. By separating unintended memorization from generalization, the study provides insights into model capacity, double descent, and membership inference. The derived scaling laws and experimental results contribute to a deeper understanding of how LLMs learn and retain information across different scales. The findings have implications for privacy, security, and the development of more efficient and generalizable LLMs.