- The paper investigates failure modes in automated defect repair tools by analyzing the performance of OpenHands, Tools Claude, and Agentless across 500 issues.
- It reveals that task complexity and flawed reasoning cause significant performance drops and distinct failure patterns in different tool architectures.
- The paper introduces a collaborative Expert-Executor framework, improving issue resolution by achieving a 22.2% success rate on previously failed cases.
An Empirical Study on Failures in Automated Issue Solving
The paper "An Empirical Study on Failures in Automated Issue Solving" (2509.13941) investigates the challenges and failure modes encountered by automated tools designed to autonomously identify and repair defective code snippets. Through a structured analysis of tools evaluated on the SWE-Bench-Verified benchmark, the authors aim to uncover the underlying causes of these failures and propose an innovative framework to improve issue solving capabilities.
Introduction to Automated Issue Solving
Automated issue solving is a pivotal challenge in software engineering, aiming to autonomously identify and repair defects in codebases. Although tools leveraging LLMs have shown promise, they often fail on substantial portions of tasks. SWE-Bench has established itself as a standard for evaluating progress in this area. This paper focuses on understanding these failures more deeply by examining the performance of three tools—OpenHands, Tools Claude, and Agentless—and constructing a taxonomy of their failure modes.
The paper evaluates three representative tools across 500 issues from SWE-Bench-Verified: OpenHands, Tools Claude, and Agentless. Results indicate similar overall issue-solving rates (49-53%). However, the tools exhibit distinct strengths across problem types, suggesting potential benefits from ensemble methods.
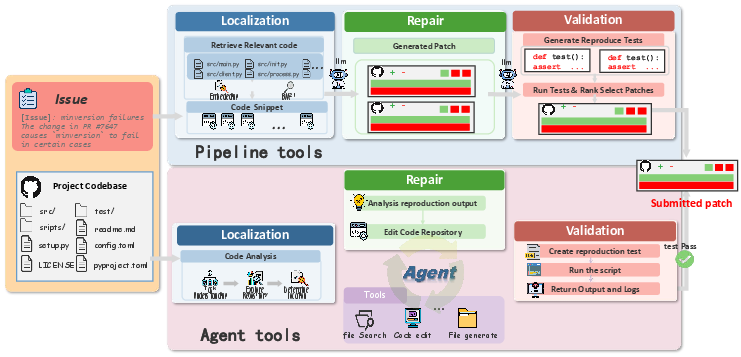
Figure 1: Workflow of the pipeline-based and agent-based tools.
Task complexity significantly impacts performance. Issue-solving rates degrade notably as task complexity increases, particularly regarding multi-file coordination. OpenHands demonstrates resilience in complex scenarios, whereas Agentless struggles more, underscoring architectural design needs for handling intricate tasks.
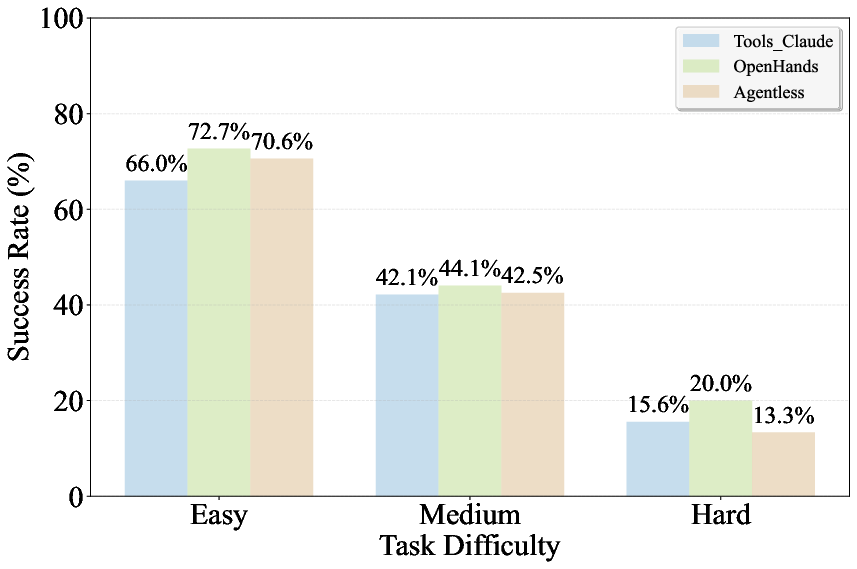
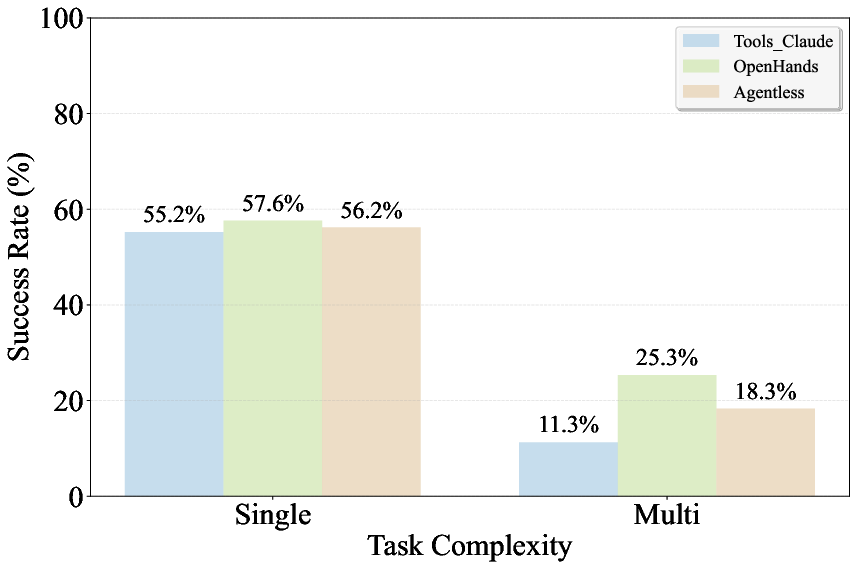
Figure 2: Issue solving rates across different difficulty levels.
Interaction Efficiency
Interaction efficiency analysis reveals diminishing returns for agent-based processes. Most successes occur within the first 25 rounds. Beyond this point, attempts to solve tasks often lead to extended failures, highlighting inefficiencies in tool design.
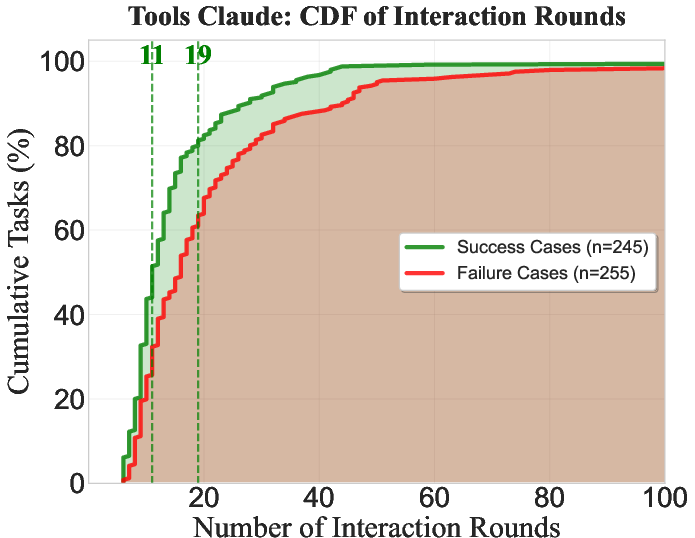
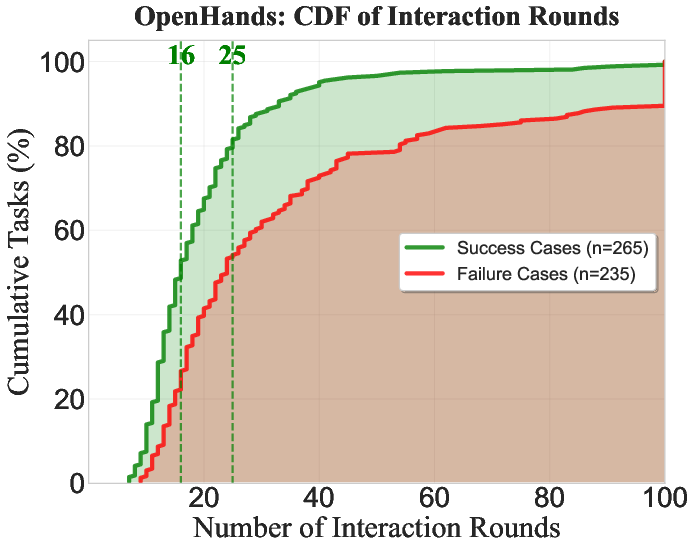
Figure 3: Interaction rounds for Tools Claude.
Taxonomy of Failure Modes in Automated Issue Solving
The authors develop a taxonomy encompassing three stages of the issue-solving process: Localization, Repair, and Iterative Validation. This structured analysis reveals distinct failure types, such as issue misleading and superficial information matching during localization, and flawed reasoning leading to cognitive deadlocks in iterative validation.
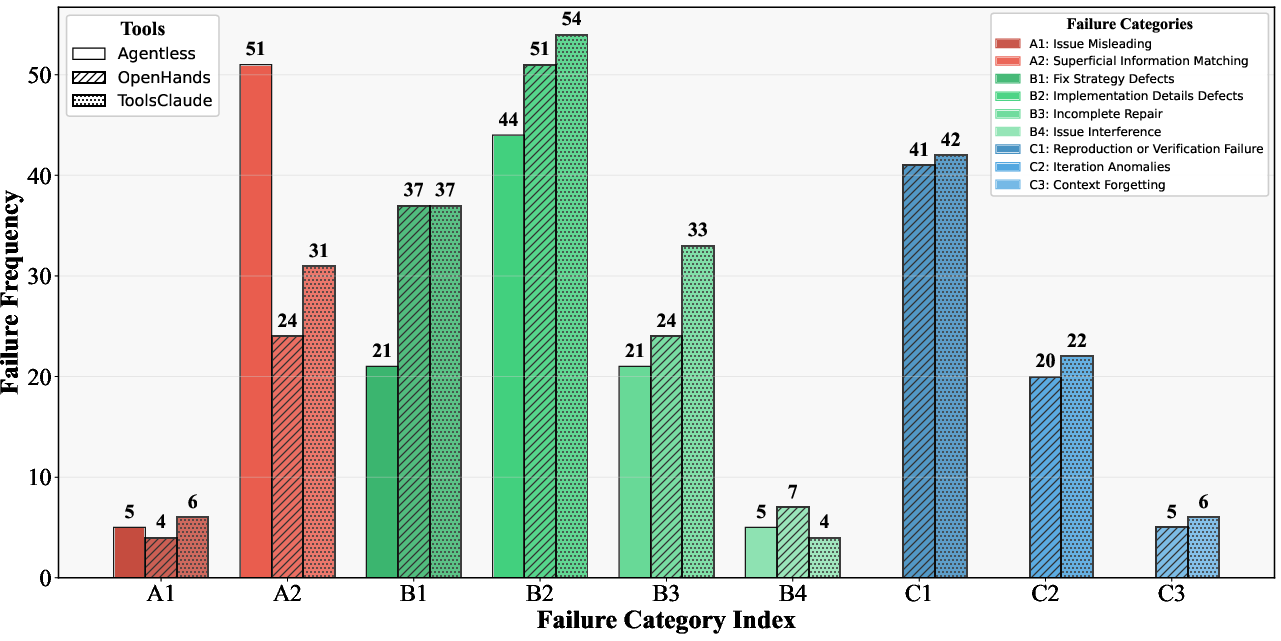
Figure 4: Distribution of failures across different tools.
Analysis of Failure Modes
Distinct patterns emerge across different tool architectures. Pipeline-based tools often fail during localization, while agent-based tools encounter more iteration anomalies due to flawed reasoning. As tasks grow more complex, failure shifts toward iterative validation, driven by errors requiring deep cognitive ability.
Mitigation Exploration with a Collaborative Architecture
Given that flawed reasoning is a major cause of failure, the authors propose a collaborative Expert-Executor framework. This system emulates human peer review, addressing strategic oversight and providing corrective guidance. Evaluation on previously failed cases demonstrated a 22.2% success rate, evidencing the framework's effectiveness in mitigating reasoning deadlocks.
Conclusion
This empirical paper provides valuable insights into why automation in issue resolution fails, identifying clear architecture-specific vulnerabilities. The proposed Expert-Executor framework showcases the potential improvement through collaboration, thus paving the way for more robust automated issue solving tools. The comprehensive taxonomy and strategic oversight mechanisms presented in the paper highlight the need for tools designed to diagnose, collaborate, and adaptively reason beyond mere scale.