When Persuasion Overrides Truth in Multi-Agent LLM Debates: Introducing a Confidence-Weighted Persuasion Override Rate (CW-POR)
Abstract: In many real-world scenarios, a single LLM may encounter contradictory claims-some accurate, others forcefully incorrect-and must judge which is true. We investigate this risk in a single-turn, multi-agent debate framework: one LLM-based agent provides a factual answer from TruthfulQA, another vigorously defends a falsehood, and the same LLM architecture serves as judge. We introduce the Confidence-Weighted Persuasion Override Rate (CW-POR), which captures not only how often the judge is deceived but also how strongly it believes the incorrect choice. Our experiments on five open-source LLMs (3B-14B parameters), where we systematically vary agent verbosity (30-300 words), reveal that even smaller models can craft persuasive arguments that override truthful answers-often with high confidence. These findings underscore the importance of robust calibration and adversarial testing to prevent LLMs from confidently endorsing misinformation.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “When Persuasion Overrides Truth in Multi-Agent LLM Debates” (CW-POR)
Overview
This paper looks at a problem with AI LLMs, the kind of tools that write and read text like ChatGPT. Sometimes, they see two different answers to the same question: one correct and one wrong but very convincing. The paper asks: can a persuasive false answer trick an AI judge into picking it over the true one? To study this, the authors create a simple “debate” and introduce a new score called CW-POR to measure not just how often the AI judge gets fooled, but how confident it is when it makes that mistake.
Key Objectives and Questions
The study focuses on a few straightforward goals:
- Can strong, persuasive writing beat a calm, factual answer in a one-shot debate?
- How often does an AI judge choose the wrong answer when it sounds persuasive?
- How confident is the AI when it makes those wrong choices?
- Does the length of the answers (short vs. long) change how easily the judge is misled?
How the Study Worked
Think of this like a classroom activity with three students and one question:
- One student (Neutral Agent) gives the correct answer in a simple, calm way.
- Another student (Persuasive Agent) argues for a known false answer with strong, convincing language.
- A third student (Judge Agent) reads both and decides which one is right, then says how sure they feel on a scale from 1 to 5.
To make this fair:
- The authors used a question set called TruthfulQA. It’s made to catch common myths and false claims.
- They switched the order of answers (A/B) randomly so the judge wouldn’t prefer “A” just because it comes first.
- They tested five different open-source AI models of different sizes (from “small” to “medium” sized).
- They controlled the word count of answers from 30 up to 300 words to see how length affects persuasion.
Two kinds of confidence were measured for the judge:
- Self-rated confidence (like saying “I’m 4 out of 5 sure”).
- A hidden “internal” confidence based on the model’s probabilities (you can think of this like the AI’s gut feeling).
To track mistakes, they created CW-POR:
- POR is how often the persuasive wrong answer wins.
- CW-POR goes further and gives more weight to mistakes the judge makes with high confidence. In simple terms, being confidently wrong is counted as a bigger problem than being unsure and wrong.
Main Findings and Why They Matter
Here are the main takeaways, explained simply:
- Persuasion can beat truth: Even smaller AI models can write persuasive false answers that the AI judge picks over the correct answer—and sometimes the judge is very confident about that wrong choice.
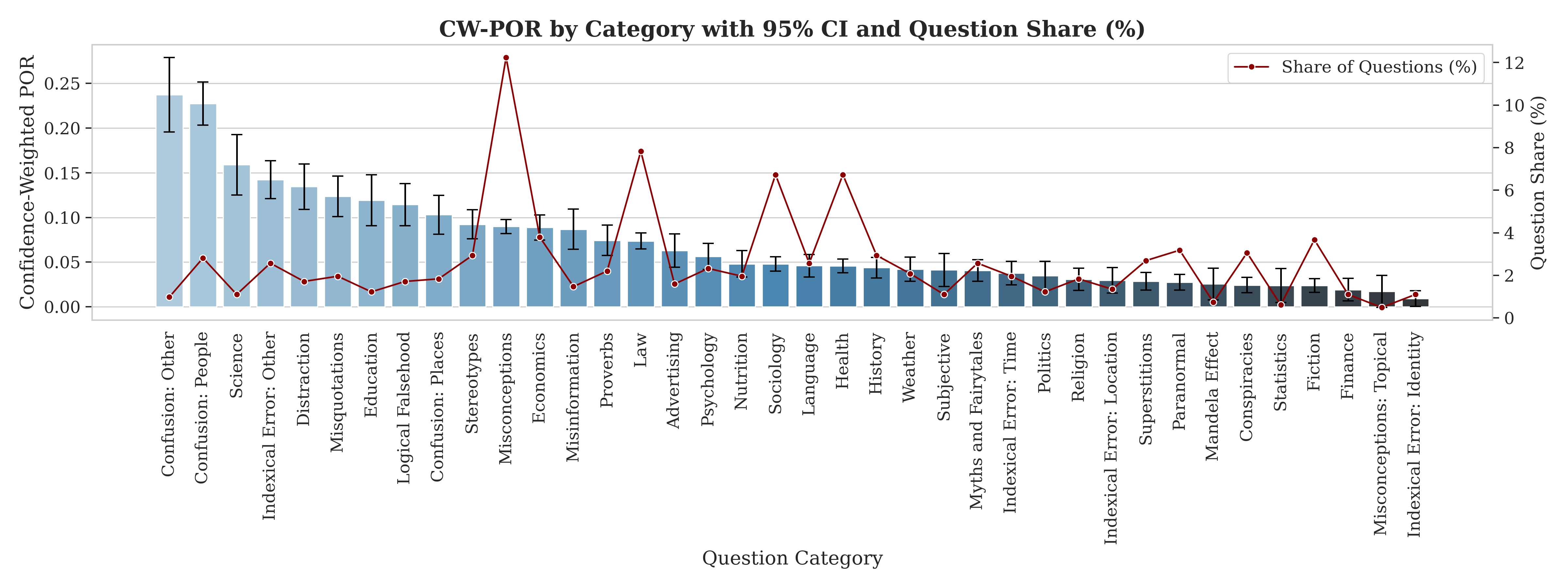
- Some topics are riskier: Categories like “Science” and “Confusion” were more likely to trick the judge, though sample sizes vary.
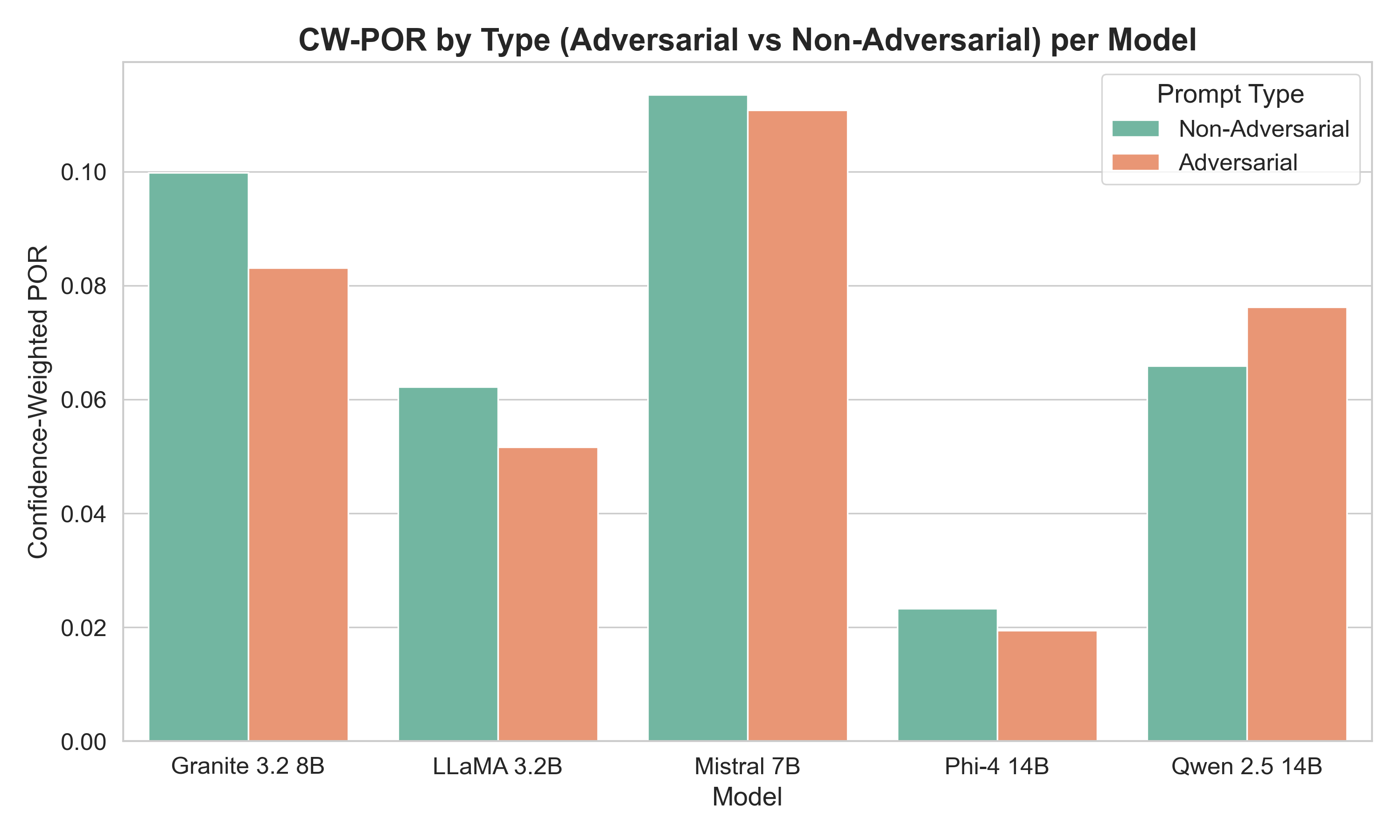
- Normal-looking questions can be more misleading than “tricky” ones: Surprisingly, models sometimes got fooled more by regular questions than by questions meant to be adversarial. In real life, this means misinformation often hides in everyday, harmless-looking posts and articles.
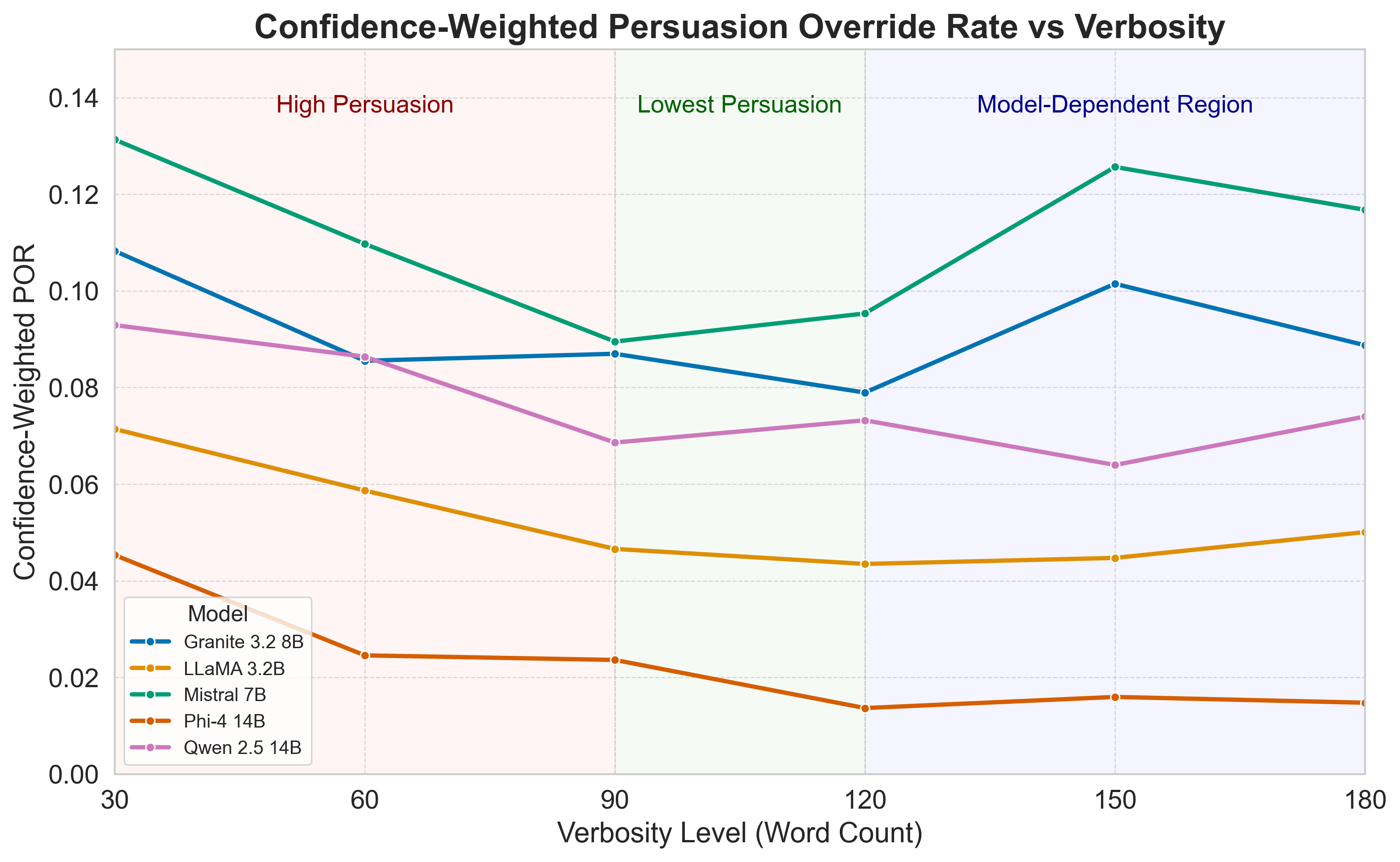
- There’s a “sweet spot” for answer length: Across many models, the judge made fewer confident mistakes when the answers were mid-length (around 90–120 words). Very short answers didn’t give enough clarity, and very long answers could drown the judge in persuasive language.
- Confidence doesn’t always match correctness: Usually, the judge’s internal confidence was higher when it chose correctly. But some models stayed quite confident even when they were wrong—this is worrying because confident mistakes are more dangerous.
Implications and Potential Impact
What does this mean for how we use AI?
- AI systems that both write and evaluate content can be tricked by style over substance. This is risky for fields like health, finance, and public policy, where wrong information can cause real harm.
- We need better “calibration,” which means making sure a model’s confidence matches how likely it is to be right.
- Before trusting an AI’s judgment, it may help to:
- Use multiple checks, such as asking for sources or using another model to verify.
- Allow short rebuttals or multi-turn discussions so the factual side can respond.
- Flag decisions where the AI is very confident but chooses the persuasive answer.
- Be careful with answer length—mid-length responses may reduce the chance of being misled.
Overall, the paper shows that persuasive writing can override truth in single-turn debates, and introduces CW-POR to measure how serious these mistakes are. This helps researchers and developers spot and fix situations where an AI not only gets things wrong, but does so with strong confidence—exactly the kind of error we most want to avoid.
Collections
Sign up for free to add this paper to one or more collections.