- The paper introduces a scalable training method using vanilla PPO and GAE to enhance language model reasoning while reducing training steps.
- It employs simplified reward functions and omits KL regularization, leading to improved stability and computational efficiency.
- Key findings show superior performance on benchmarks like AIME2024 and GPQA Diamond, demonstrating effective scaling across model sizes.
An Expert Analysis of "Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model"
"Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model" (2503.24290) provides a comprehensive, empirical framework for scaling large-scale reasoning-oriented reinforcement learning (RL) directly on base models, a method referred to as Reasoner-Zero training. This paper puts forward a minimalist yet robust approach to achieve significant performance improvements in LLM reasoning capabilities, leveraging Proximal Policy Optimization (PPO) with Generalized Advantage Estimation (GAE).
Introduction to Reasoner-Zero Training
Open-Reasoner-Zero (ORZ) introduces a method to directly apply RL scaling methodologies on LLMs without fine-tuning, emphasizing scalability and simplicity. The study aims to enhance reasoning abilities across diverse domains like arithmetic, logic, and coding by utilizing straightforward reward functions and avoiding complex regularization techniques such as KL divergence penalties.
ORZ employs the same base model, Qwen2.5-32B, as seen in DeepSeek-R1-Zero, achieving superior performance on benchmarks like AIME2024 and GPQA Diamond, while only requiring a tenth of the training steps. The researchers argue that using a combination of vanilla PPO and GAE (with λ=1 and γ=1) allows for efficient scaling and robust management of training stability.
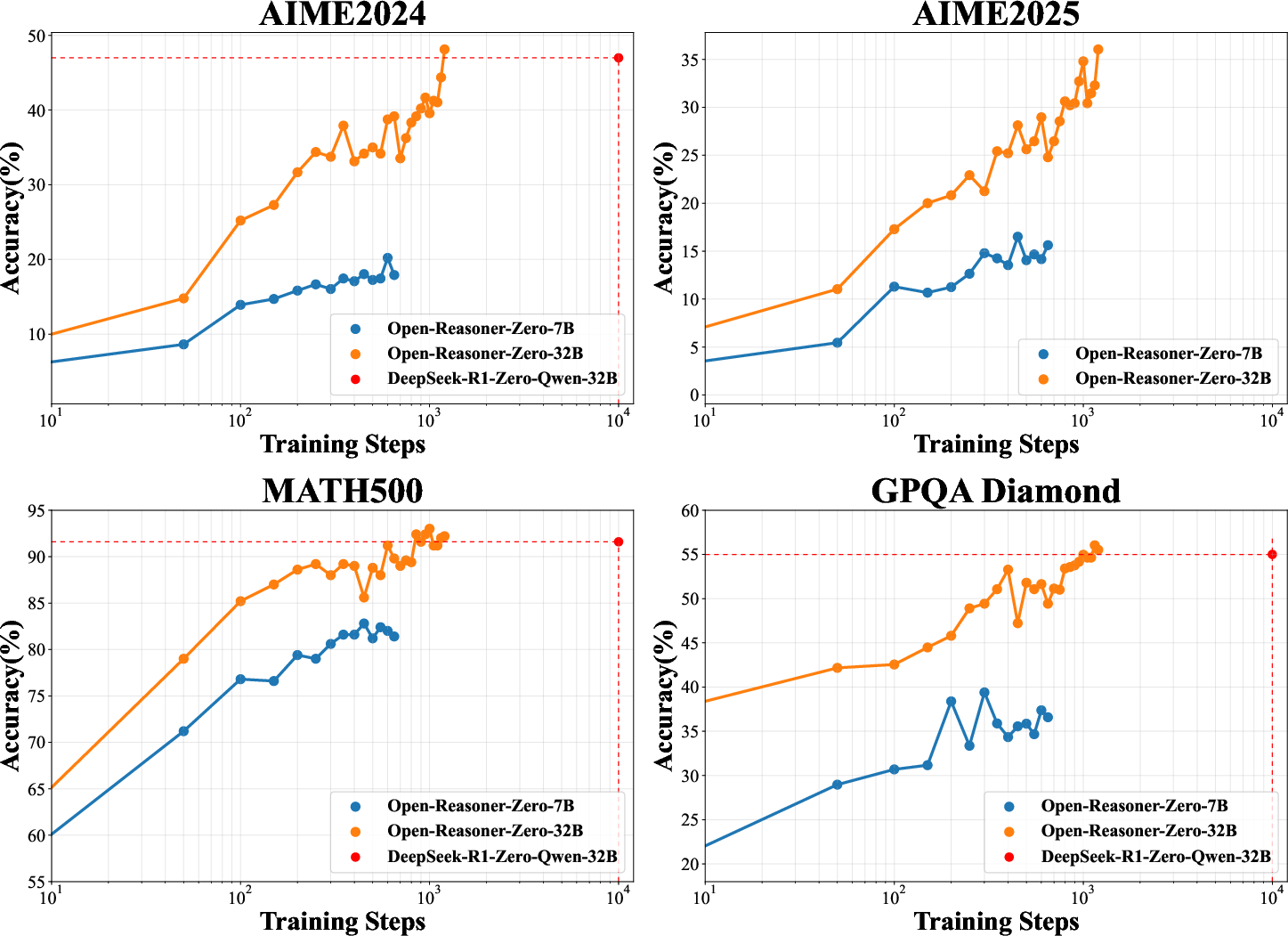
Figure 1: Evaluation of Open-Reasoner-Zero-{7B, 32B} on benchmarks, demonstrating superior performance over fewer training steps.
Scaling Strategies and RL Techniques
The backbone of the ORZ approach lies in applying PPO as the core RL algorithm. The study emphasizes PPO's learned critic's ability to robustly estimate value functions, guiding the training process by effectively identifying and diminishing repetitive sequences that weaken model performance.
- Algorithmic Choices: The use of vanilla PPO offers stability across varied model scales, supported by evidence from ablation studies. The bias-free advantage of GAE with γ=1 and λ=1 is highlighted, directly influencing effective sequence length without complicating hyperparameter spaces with KL penalties.
- Simplification through Minimal Reward Functions: ORZ demonstrates that simplified rule-based reward structures (focusing solely on response correctness) are as effective as complex structured patterns used in alternatives like DeepSeek R1, without elements that facilitate reward hacking.
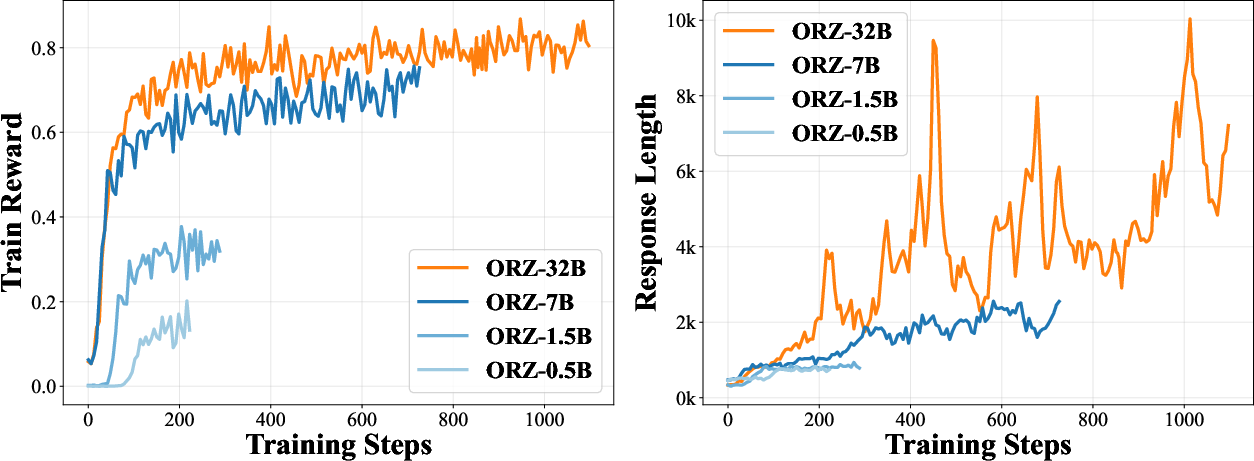
Figure 2: Train-time Scale up on Train Reward and Response Length of Open-Reasoner-Zero (ORZ) - {0.5B, 1.5B, 7B, 32B}, demonstrating consistent scalability.
Key Findings and Comparative Advantage
ORZ offers several insights pivotal for stable, scalable RL:
- Selection of PPO over GRPO: PPO's learned critic, equipped for critical advantage estimations, fosters training stability by penalizing repetitive patterns effectively and supports robust credit assignment.
- Elimination of KL Regularization: The exclusion of KL constraints aids simplification, reduces computational overhead, and lessens hyperparameter tuning burdens, aligning with ORZ's goal of broad accessibility.
- Data Handling: The choice to scale training datasets both in quantity and diversity underscores the necessity of such expansions for achieving remarkable performance improvements, as evidenced by training results.
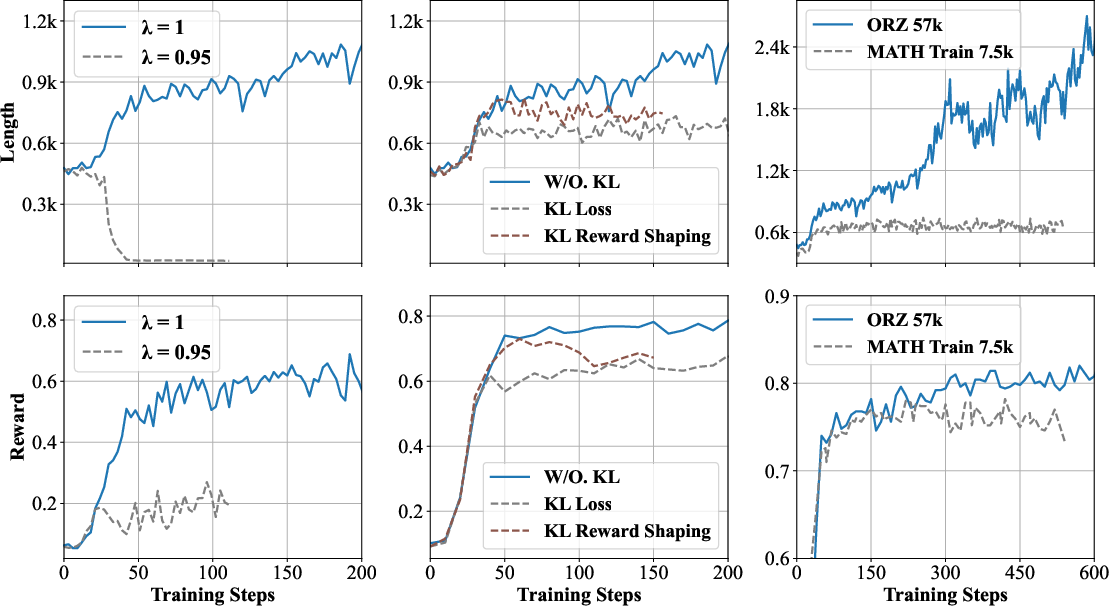
Figure 3: Ablation studies for key design choices in ORZ, informing an effective training recipe.
The performance evaluation of ORZ models, across a gamut of benchmarks and model sizes, attests to its effectiveness. ORZ models demonstrate superior generalization on tasks without additional instructional tuning, consistently outperforming other models like Qwen2.5-Instruct-32B.
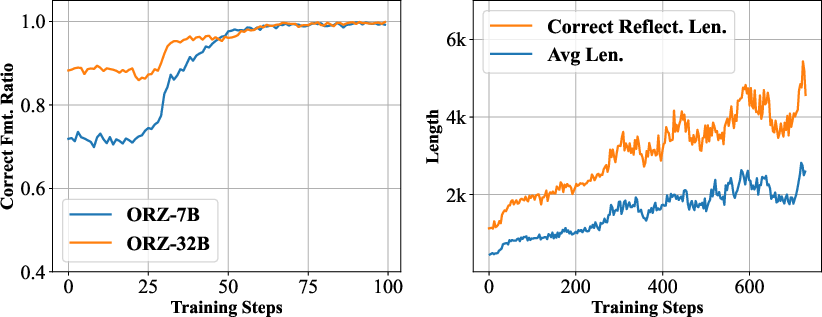
Figure 4: Evaluation performance of Open-Reasoner-Zero-{0.5B, 1.5B} showing strong scaling properties.
Conclusion
The establishment of Open-Reasoner-Zero marks a significant step in open-source AI research, simplifying large-scale RL implementations while encouraging further extensions and exploration from the academic community. By focusing on minimalist strategies and robust training dynamics, this work lays a foundation for subsequent advances in reinforcing LLM reasoning abilities. As ORZ resources are extensively shared, the broader research arena stands poised for deeper inquiry into scalable reasoning RL. Future research can likely benefit from adaptable data scales, improved model dimensions, and expanded application scenarios, building upon the robust framework introduced by ORZ.