- The paper introduces a digital RRAM-based compute-in-memory chip that integrates in-situ pruning with dynamic weight optimization.
- It employs a neuro-inspired algorithm-hardware co-design that reduces redundant computations by up to 59.94% on benchmark datasets.
- The system achieves notable improvements in energy efficiency and silicon area reduction while maintaining 100% bit accuracy in in-memory processing.
Reconfigurable Digital RRAM Logic Enables In-Situ Pruning and Learning for Edge AI
This paper presents a novel approach to realizing energy-efficient artificial intelligence on edge devices. The proposed solution consists of an integrated software-hardware co-design that employs a reconfigurable digital RRAM (Resistive Random Access Memory) logic to enable in-situ pruning and learning. The research focuses on bridging the gap between the current von Neumann architecture-based systems and brain-inspired computing paradigms, which inherently optimize synaptic weights and topology to achieve its efficiency.
Brain-Inspired Algorithm-Hardware Co-Design
The research introduces an innovative neuro-inspired method combining algorithmic and hardware components to achieve simultaneous weight and topology optimization. On the algorithmic front, a dynamic weight-pruning strategy is employed. This strategy efficiently monitors weight similarity during training, removing redundant connections without compromising the network accuracy, thereby reducing computational operations on datasets such as MNIST by 26.80% and ModelNet10 by 59.94%. This co-optimization strategy draws inspiration from biological processes such as synaptogenesis, synaptic plasticity, and pruning, as described in the software pipeline presented in Fig.~1a.
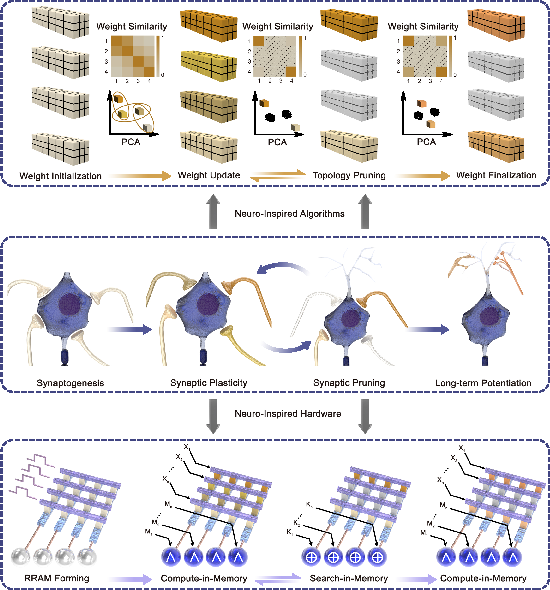
Figure 1: Neuro-inspired algorithm-hardware co-design for simultaneous weight and topology optimization.
On the hardware side, the study features a fully digital, reconfigurable RRAM-based compute-in-memory (CIM) chip that eliminates the von Neumann bottleneck. This digital RRAM CIM chip supports diverse logical operations including NAND, AND, XOR, and OR, as indicated by its architecture (Fig.~1c). The chip demonstrated enhanced efficiency by performing all computations in memory without ADC/DAC overhead, which significantly reduces energy consumption.
Physical and Electrical Characterization of RRAM Array
The physical and electrical evaluation of the RRAM array revealed several significant findings. The RRAM system, as depicted in Fig.~2, consists of 512×32×2 RRAM arrays. The cross-sectional TEM and EDS mappings confirm the successful fabrication of the 1T1R cells with their expected material composition and structural design (Fig.~2c, d).
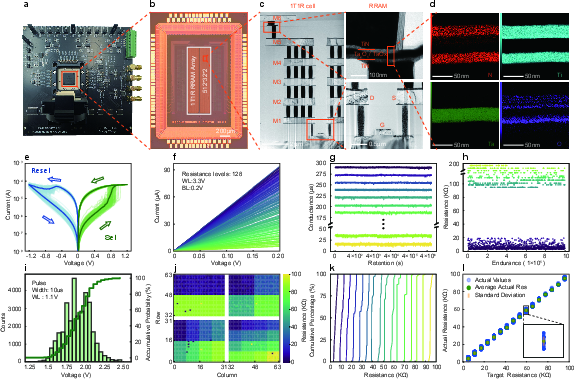
Figure 2: Physical and Electrical Characterization of the RRAM array, showcasing the system board, reconfigurable logic chip, and material analyses.
The electrical performance, analyzed through I-V characteristics, demonstrated robust bipolar resistive switching and substantial multi-level programming capabilities up to 128 distinct resistance states (Fig.~2e, f). These characteristics were verified under retention and endurance testing conditions, illustrated in Fig.~2g, h, affirming the reliability and stability required for edge AI applications. Furthermore, array-level programming accuracy and resistance tuning distributions showcased the promise of leveraging RRAM technology for in-situ learning without significant resource overhead.
The authors have detailed a comprehensive analysis of their proposed chip architecture, as evidenced in Fig.~3a. The system incorporates a Top CIM Controller, driver circuits, and two 512x32 RRAM arrays supporting flexible bitwise operations. This architecture enables dynamic weight and topology co-optimization, crucial for increasing processing efficiency.
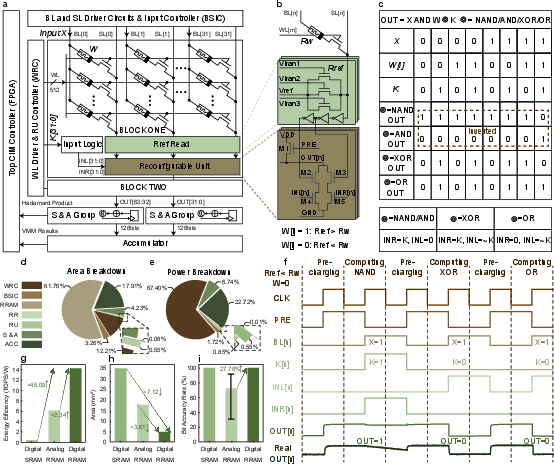
Figure 3: Detailed block diagram of the RRAM-based reconfigurable logic chip and comparisons against existing technologies in terms of power and area efficiency.
The design demonstrates significant improvements over analog implementations, evidenced by a 72.30% reduction in silicon area and a 57.26% improvement in overall energy consumption. The integrated system achieves a 45.09× energy efficiency improvement compared to digital SRAM CIM and maintains a 100% bit accuracy, surpassing the analog alternative's higher error rates (Fig.~3g, h, i).
Dynamic Pruning Methodologies for CNNs and PointNet++
The paper further explores dynamic pruning strategies, applying them to convolutional neural networks for the MNIST dataset (discussed in Fig.~4) and PointNet++ for ModelNet10 classification (explored in Fig.~5).
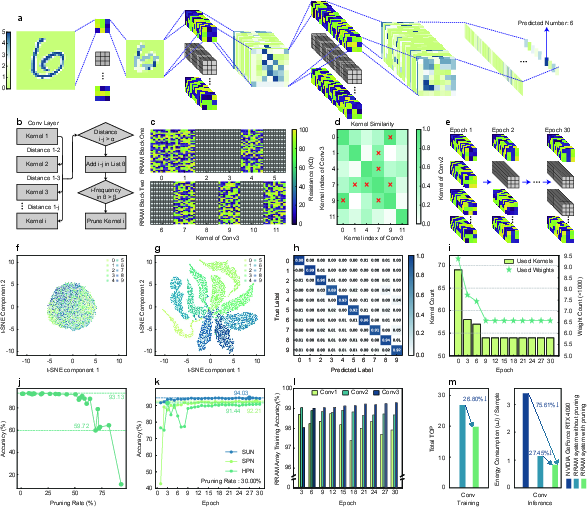
Figure 4: Dynamic CNN kernel pruning for MNIST classification, illustrating network optimization and feature space separability post-training.
For CNNs, dynamic kernel pruning processes progressively reduce active kernels and total weights during training without sacrificing accuracy. The results show stable classification accuracy even with substantial pruning, indicating effective redundancy reduction and network optimization.
In the PointNet++ architecture, filter pruning is executed efficiently through RRAM-based CIM operations. The system demonstrates robust feature separation capabilities while achieving a remarkable energy consumption reduction of 86.53% compared to high-end GPU systems (Fig.~5i).
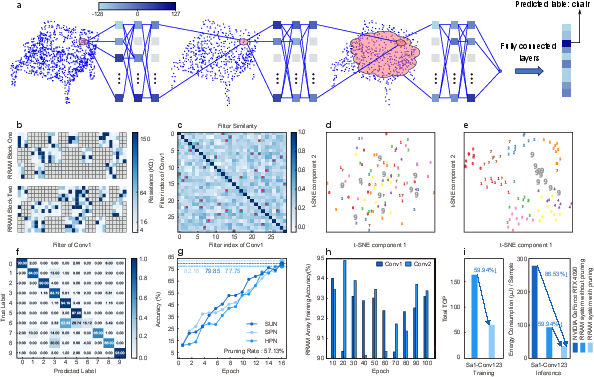
Figure 5: Dynamic convolution filter pruning on PointNet++ for ModelNet10 classification, highlighting pruning impacts on feature distribution and energy efficiency.
Conclusion
The research provides a compelling argument for bridging the computational efficiency gap between brain-inspired models and conventional AI systems. The integration of a real-time weight pruning algorithm with a digital RRAM-based CIM architecture demonstrates promising results in reducing computational and energy overhead without sacrificing inference accuracy. Future work might include scaling this brain-inspired CIM approach to accommodate larger and more intricate architectures, building toward more powerful and efficient edge AI systems. The explorations in logic extension could further enhance the chip's versatility, facilitating broader application domains and more complex AI tasks. This research serves as a precursor for advancing edge AI that mimics the efficiency of biological intelligence.