SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Abstract: DeepSeek-R1 has shown that long chain-of-thought (CoT) reasoning can naturally emerge through a simple reinforcement learning (RL) framework with rule-based rewards, where the training may directly start from the base models-a paradigm referred to as zero RL training. Most recent efforts to reproduce zero RL training have primarily focused on the Qwen2.5 model series, which may not be representative as we find the base models already exhibit strong instruction-following and self-reflection abilities. In this work, we investigate zero RL training across 10 diverse base models, spanning different families and sizes including LLama3-8B, Mistral-7B/24B, DeepSeek-Math-7B, Qwen2.5-math-7B, and all Qwen2.5 models from 0.5B to 32B. Leveraging several key design strategies-such as adjusting format reward and controlling query difficulty-we achieve substantial improvements in both reasoning accuracy and response length across most settings. However, by carefully monitoring the training dynamics, we observe that different base models exhibit distinct patterns during training. For instance, the increased response length does not always correlate with the emergence of certain cognitive behaviors such as verification (i.e., the "aha moment"). Notably, we observe the "aha moment" for the first time in small models not from the Qwen family. We share the key designs that enable successful zero RL training, along with our findings and practices. To facilitate further research, we open-source the code, models, and analysis tools.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, framed concretely to guide future research.
- Limited domain scope: RL training and most evaluations are math-centric; it remains unclear whether zero RL yields similar emergent reasoning in non-math domains (coding, logical puzzles, legal/medical reasoning, multi-hop QA).
- Tool-use and multi-modal reasoning: No exploration of zero RL with calculators, symbolic solvers, search tools, or multimodal tasks (e.g., diagrams in Olympiad problems); the impact on reasoning emergence is unknown.
- Single RL algorithm: Only GRPO is used; comparative studies with PPO, REINFORCE variants, RLAIF/RLHF, off-policy methods, or hybrid process-/outcome-reward RL are missing.
- Reward design rigidity: Final-answer-only, binary rewards (+1/0) are used; the effects of partial credit, step-wise/process rewards, error-aware shaping, or curriculum-based reward schedules are not assessed.
- Format reward ablation breadth: The paper shows strict penalties (−1) hurt exploration, but does not test softer/gradual format rewards, adaptive schedules, or verifiability-preserving extraction without harsh penalties.
- Answer extraction reliability: With no format constraints, robustness of answer parsing (e.g., extracting the final answer amid long CoT) and its failure modes are not quantified across models/benchmarks.
- Reward hacking diagnostics: Potential spurious strategies (e.g., gaming the correctness check, recurring templates) under rule-based rewards are not audited or mitigated.
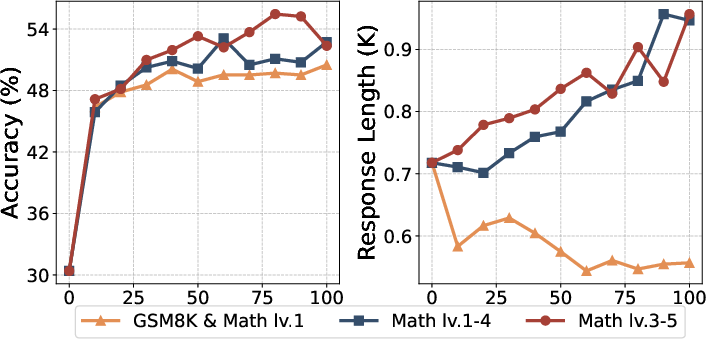
- Data difficulty alignment: While alignment between dataset difficulty and base-model capability is emphasized, no automated curriculum (dynamic difficulty sampling, capability estimation, or adaptive scheduling) is proposed or evaluated.
- Data scale and diversity: Training uses ~8k problems per difficulty tier; scaling laws, returns to additional data, synthetic augmentation strategies, or cross-domain mixes (e.g., coding + math) are not studied.
- Prompt design sensitivity: Simpler prompts stabilize weaker models, but there is no systematic prompt ablation (prompt complexity levels, scaffolding strategies, or staged prompt curricula) or generalizable guidance.
- Decoding confounds: Baselines use greedy decoding while RL models use sampling (temperature=1.0, top-p=0.95); matched decoding settings to isolate training effects are missing for all benchmarks.
- Pass@k generality: Deep analysis of pass@k gains is provided mainly for Mistral-24B; broader replication across families/sizes and decoding settings (e.g., beam search vs sampling) is not reported.
- Seed variance and training stability: The paper does not report across-seed variance, failure rates, or sensitivity to initialization and rollout parameters; reproducibility under differing seeds remains unclear.
- Hyperparameter sensitivity: A uniform hyperparameter recipe is applied; which parameters are most sensitive (rollout count k, learning rates, KL penalties, temperature/top-p) is not mapped via controlled ablations.
- Collapse prediction and mitigation: Metrics like clip ratio and stopped length are monitored, but no early-warning thresholds, intervention strategies (reset, curriculum shift), or stabilization techniques are evaluated.
- Mechanisms behind “aha moment”: Emergent behaviors (verification, backtracking) are detected, but causal drivers (data, reward, decoding, model internals) and mechanistic interpretability (circuits, activations) are not explored.
- Behavior annotation reliability: Reasoning behavior labels rely on GPT-4o; robustness across annotators/models, annotation drift, false positives/negatives, and cross-dataset validation are only partially addressed.
- Linking behaviors to accuracy: Correlation/causality between growth in specific behaviors (e.g., verification frequency) and accuracy gains is not quantified across models/datasets.
- Negative transfer and forgetting: Mixed generalization trends (e.g., GPQA changes) are not analyzed for causes (catastrophic forgetting, overfitting to math, distribution shift) or mitigated.
- Qwen-2.5-Math-7B anomaly: The lack of response-length increase for this model is noted but not investigated (pretraining differences, instruction-following strength, decoding behaviors).
- SFT cold-start alternatives: The paper shows short-CoT SFT hurts exploration, but does not test long-CoT SFT, diversity-preserving SFT, or exploration-preserving objectives as improved cold-start strategies.
- Post-RL pipelines: Effects of post-RL SFT, distillation (to shorter CoT), or RL + SFT alternation cycles on both accuracy and reasoning behaviors are not studied.
- Efficiency/latency trade-offs: Increased CoT length raises inference cost; there is no analysis of accuracy vs token budget, length-aware rewards, or techniques to control “thinking time” without hurting accuracy.
- Data contamination checks: RL uses GSM8K/MATH training sets; contamination risks in pretraining (overlap with test sets, synthetic variants) and their impact on reported gains are not audited.
- Safety and robustness: Robustness to adversarial prompts, spurious correlations, multilingual stability (given observed gibberish), and safety considerations under zero RL are not evaluated.
- Scaling to larger models: Experiments cap at 32B (except Mistral-24B); behavior on 70B+ open models, and compute/data scaling dynamics at larger scales, remain unexplored.
- Tool-based verification rewards: Integrating external verifiers (symbolic math, program checkers) as process or outcome rewards is not tested and could clarify how verification behavior emerges.
- Mixture and scheduling of difficulties: The mix of easy/medium/hard is static; optimal curricula (start easy, ramp hard), or interleaving strategies to balance exploration and stability are not investigated.
- Benchmark coverage and fairness: Beyond math-centric sets, broader reasoning suites (e.g., Big-Bench Hard, HumanEval/MBPP for code, multilingual tasks) under matched decoding are needed to assess generality.
- Compute and resource reporting: Detailed training costs (GPU-hours per model, memory footprints, rollout sampling costs) and cost-effectiveness comparisons are not provided, limiting practical adoption.
Practical Applications
Immediate Applications
Below are applications that can be deployed now by leveraging the paper’s zero-RL recipe (SimpleRL-Zoo), reward design choices, monitoring metrics, and data difficulty alignment.
- Zero-RL upgrades for open base models (7B–24B) to improve reasoning
- Sectors: software, education, enterprise IT
- What: Apply the paper’s minimal RL recipe (GRPO, ~8k verifiable tasks, +1/0 correctness reward, no format penalty) to boost reasoning and instruction-following in open models (Llama/Mistral/Qwen/DeepSeek-Math).
- Tools/workflows: SimpleRL-Zoo codebase; small curated datasets with programmatic verifiers; temperature/top-p sampling for training; pass@k evaluation.
- Assumptions/dependencies: Access to base model weights; modest compute for RL; availability of domain tasks with automatic correctness checks.
- Verifiability-first reward design in domain-specific RL
- Sectors: software (code generation), data/analytics (SQL), finance (spreadsheet modeling), education (math)
- What: Replace format rewards (e.g., boxed final answers) with checkers that evaluate correctness (unit tests for code, SQL result diffs, numeric answer matchers).
- Tools/workflows: Test harnesses, DB sandboxes, numeric/regex evaluators; reward interfaces that score correctness only.
- Assumptions/dependencies: Reliable, inexpensive checkers for the target task; sandboxed execution for code/SQL.
- Curriculum and difficulty alignment for stable RL
- Sectors: MLOps, AI engineering
- What: Match RL training data difficulty (Easy/Medium/Hard) to model exploration capacity to avoid collapse and maximize CoT growth.
- Tools/workflows: Difficulty-tagged datasets; curriculum scheduler that adapts difficulty by observed pass@k/clip ratio.
- Assumptions/dependencies: Accurate difficulty labels or heuristics; telemetry for training dynamics.
- Behavioral telemetry for training health and reasoning quality
- Sectors: MLOps, safety/quality assurance
- What: Monitor “clip ratio,” “average stopped length,” and reasoning behavior ratios (verification, backtracking, subgoal-setting, enumeration) to distinguish healthy CoT growth from degenerate verbosity.
- Tools/workflows: Training dashboards; automated behavior labeling (e.g., via a reference model or in-house classifier); alerts for collapse patterns.
- Assumptions/dependencies: Access to a labeling model or rules; logging infrastructure; thresholds calibrated to domain.
- Pass@k-based improvement gating for RL loops
- Sectors: software (coding copilots), evaluation/benchmarking
- What: Track widening gaps between pass@1 and pass@k to verify genuine capability gains (vs. reranking), and to decide when to allocate more sampling budget or update policies.
- Tools/workflows: Pass@k runners; sampling sweeps; decision rules for training continuation/stopping.
- Assumptions/dependencies: Task suites supporting multiple samples per prompt; cost budget for sampling.
- Training policy update: reduce heavy short-CoT SFT before RL
- Sectors: AI labs, enterprise model teams
- What: Adjust pipelines to avoid extensive short-CoT SFT before RL, which the paper shows can suppress exploration and limit later reasoning emergence.
- Tools/workflows: Pipeline templates prioritizing zero-RL or diversity-preserving SFT; change management for training playbooks.
- Assumptions/dependencies: Organizational willingness to modify legacy SFT-first workflows; alternative cold-start data or exploration-preserving SFT methods.
- Cost-effective reasoning enhancement for enterprise assistants
- Sectors: enterprise IT, customer support, internal tooling
- What: Apply math/logic-heavy zero-RL to general assistants to yield measurable gains in instruction-following (IFEVAL) and knowledge tasks (MMLU, GPQA) without broad SFT.
- Tools/workflows: Small verifiable corpora (logic/math, form-filling, rule checks); post-RL A/B testing with enterprise prompts.
- Assumptions/dependencies: Representative verifiable tasks that transfer to enterprise use; evaluation harnesses.
- Education: deploy math tutors with transparent verification behavior
- Sectors: education/EdTech
- What: Fine-tune small open models via zero-RL to induce verification/backtracking and subgoal-setting that can be surfaced to students for metacognitive teaching.
- Tools/workflows: Tutor UIs that highlight verification steps and backtracking moments; exercise banks with answer checkers.
- Assumptions/dependencies: Guardrails to prevent hallucinated math; alignment with curricula; educator oversight.
- Spreadsheet, SQL, and analytics copilot with correctness-based RL
- Sectors: finance, operations, BI/analytics
- What: RL-train models to generate formulas/queries whose outputs match ground-truth tables or known numeric results; avoid strict output formats.
- Tools/workflows: Sandbox evaluators for spreadsheets/SQL; reward function adapters; telemetry for failure modes.
- Assumptions/dependencies: Safe data sandboxes; reliable canonical outputs; privacy/PII compliance.
- Safer RL training through collapse detection and mitigation
- Sectors: safety/alignment, MLOps
- What: Use clip ratio spikes and incoherent-length growth as early warnings to adjust sampling temperature, learning rate, or curriculum difficulty.
- Tools/workflows: Automated training controllers reacting to telemetry; rollback checkpoints.
- Assumptions/dependencies: Robust monitoring; policy to auto-tune hyperparameters; well-managed checkpoints.
- Academic replication and benchmarking across base models
- Sectors: academia, open-source communities
- What: Use SimpleRL-Zoo to systematically study zero-RL across families/sizes, compare reward designs, and publish standardized pass@k/behavior-ratio results.
- Tools/workflows: Shared leaderboards; reproducible configs; dataset splits (GSM8K/MATH).
- Assumptions/dependencies: Compute access; consistent evaluation seeds/protocols.
- Product UX features that increase trust: “show my checks”
- Sectors: productivity tools, developer tools, EdTech
- What: Expose verification/backtracking snippets from RL-enhanced models as an optional “check my reasoning” view to improve user trust and teach process.
- Tools/workflows: UI component for rationale segments; toggle between final answer and reasoning snapshots.
- Assumptions/dependencies: Clear communication that rationales may be imperfect; legal review for how reasoning is presented.
Long-Term Applications
These opportunities require additional research, scaling, domain validation, or systems integration beyond what the paper demonstrates.
- Generalized zero-RL across domains with programmatic verifiers
- Sectors: software, data, scientific computing
- What: Extend the correctness-only reward paradigm to chemistry (reaction balancing), physics (unit/constraint checks), legal (rule consistency), and beyond.
- Tools/products: Domain “verifiability engines” (pluggable checkers); unified RL interface for multiple domains.
- Assumptions/dependencies: High-coverage, low-noise checkers; domain simulators; careful safety review.
- Automated curriculum systems that adapt to exploration capacity
- Sectors: MLOps, AI platforms
- What: Dynamic schedulers that auto-tune data difficulty, sampling temperature, and rollouts based on real-time pass@k, behavior ratios, and collapse signals.
- Tools/products: “Curriculum-as-a-service” modules integrated into training stacks.
- Assumptions/dependencies: Reliable capability estimation; robust streaming telemetry; sample-efficient controllers.
- Standardized behavior-based auditing and certification
- Sectors: policy/regulation, procurement, enterprise governance
- What: Incorporate verification/backtracking/subgoal-setting ratios and collapse metrics into model quality standards for regulated deployments.
- Tools/products: Audit reports, compliance checklists, reference test suites.
- Assumptions/dependencies: Consensus on metric definitions; third-party auditors; reproducible measurement protocols.
- Exploration-preserving cold-start strategies
- Sectors: AI labs, platform vendors
- What: Develop SFT methods and long-CoT pretraining that preserve diversity and exploration (vs. traditional short-CoT SFT), improving downstream RL emergence.
- Tools/products: Diversity-preserving SFT toolkits; long-CoT data pipelines.
- Assumptions/dependencies: High-quality long-CoT data; empirical validation across tasks.
- Budgeted reasoning controllers guided by “aha” signals
- Sectors: software, productivity, agents
- What: Use behavior-ratio shifts to dynamically allocate more “thinking time” (token budget) only when verification/backtracking is beneficial.
- Tools/products: Runtime controllers; policies that trigger deeper CoT when needed.
- Assumptions/dependencies: Accurate real-time behavior detection; latency/compute budgets.
- Small-model parity for on-device reasoning
- Sectors: mobile/edge, industrial field tools
- What: Push verification and reflective reasoning into compact models (≤8B) for offline calculators, diagnostics, and engineering assistants.
- Tools/products: On-device RL-distilled models; tiny verifiability modules.
- Assumptions/dependencies: Efficient training/distillation; careful domain guardrails.
- Advanced EdTech tutors teaching metacognition
- Sectors: education
- What: Tutors that model and coach subgoal-setting, verification, and backtracking, adapting difficulty in real time and assessing student reasoning patterns.
- Tools/products: Metacognitive coaching UIs; analytics for student behavior ratios.
- Assumptions/dependencies: Pedagogical validation; bias/fairness checks; integration with LMSs.
- Healthcare decision support with verifiable reasoning
- Sectors: healthcare
- What: Clinical reasoning assistants that apply rule-based verifiers (dosage calculators, guideline conformance, contraindication checks) with transparent verification/backtracking steps.
- Tools/products: Clinical checker libraries; explainable suggestion modules.
- Assumptions/dependencies: Rigorous clinical validation; regulatory approval (e.g., FDA/CE); privacy/security compliance.
- Finance and compliance copilots with auditable chains of reasoning
- Sectors: finance, legal/compliance
- What: Systems that must satisfy constraints step-by-step (policy limits, risk controls) and provide verifiable, auditable rationales.
- Tools/products: Conformance checkers; audit trail generators; reasoning dashboards.
- Assumptions/dependencies: Accurate rule codification; regulator acceptance; strong controls against hallucinations.
- Multi-modal/multi-agent planning with simulation-based rewards
- Sectors: robotics, logistics, energy
- What: Train language planners via pass/fail rewards from simulators (task success, constraint satisfaction) to induce verification/backtracking/planning behavior.
- Tools/products: Simulator integrations; plan validators; agent orchestration frameworks.
- Assumptions/dependencies: High-fidelity simulators; safe sim-to-real transfer; robust planning benchmarks.
- Safety and reliability frameworks anchored in behavior telemetry
- Sectors: alignment/safety, platform governance
- What: Use behavior metrics as early-warning signals for overthinking, collapse, or brittle reasoning; define intervention policies and red-teaming protocols.
- Tools/products: Safety monitors; auto-mitigation playbooks; red-team harnesses.
- Assumptions/dependencies: Agreed thresholds; human oversight; comprehensive evaluation suites.
Glossary
- Aha moment: An emergent, reflection-like behavior where the model recognizes and corrects its own mistakes during reasoning. "This RL training paradigm starting from base models is often referred to as zero RL training."
- AIME24: The American Invitational Mathematics Examination 2024 benchmark used to evaluate mathematical reasoning. "AIME24 (Pass@1)"
- AMC23: The American Mathematics Competitions 2023 benchmark for assessing problem-solving ability. "AMC23"
- Avg@32: An evaluation setting where the average score is computed over 32 sampled runs. "AIME24 (Avg@32)"
- Average Stopped Length: A metric tracking the average length of responses that end normally without truncation. "Average Stopped Length:"
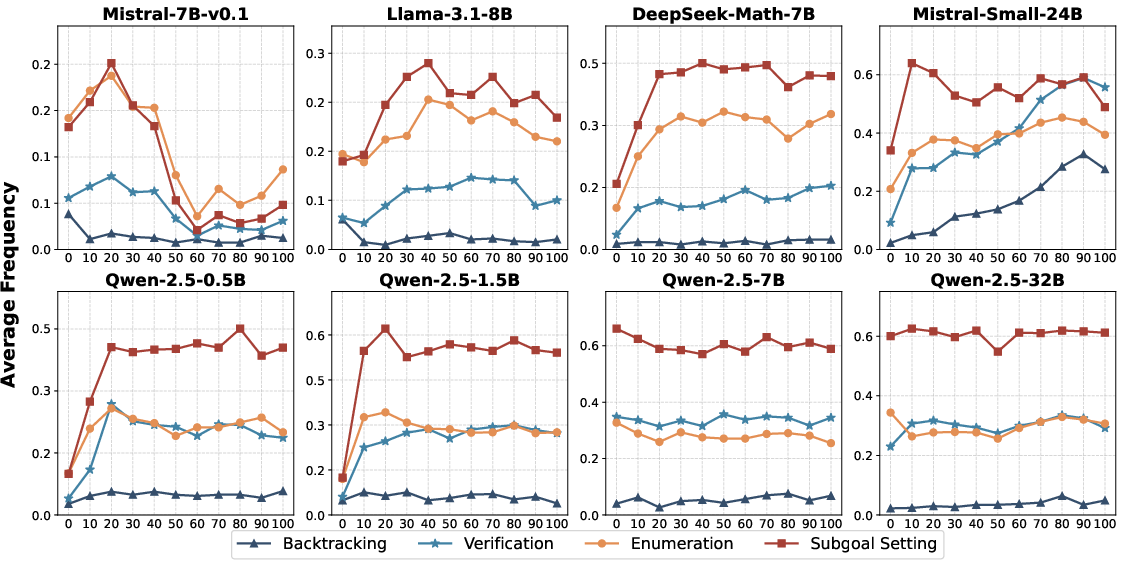
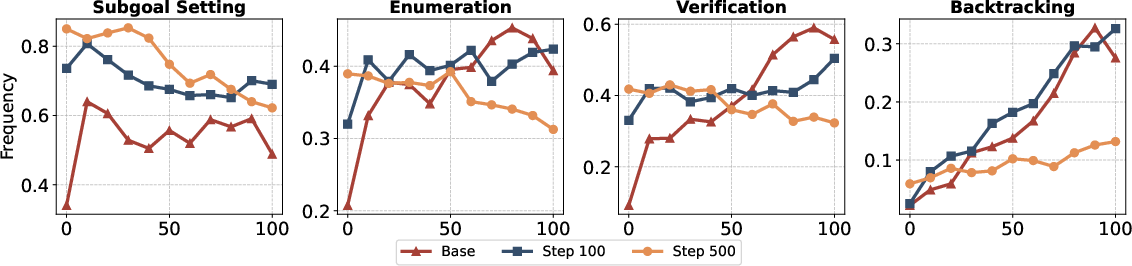
- Backtracking: A cognitive reasoning behavior where the model revisits prior steps or alternative paths after detecting an error. "reflection-oriented behaviors such as
Verification" andBacktracking" increase dramatically" - Base models: Pretrained models without task-specific supervised fine-tuning, serving as the starting point for RL. "starting from pretrained models (i.e., base models)"
- Chain-of-Thought (CoT): Long, explicit reasoning traces generated by a model to solve complex tasks. "long Chains-of-Thought (CoT) responses"
- Clip Ratio: The proportion of generated outputs that are truncated due to exceeding the maximum context length. "we define the proportion of truncated outputs as the ``Clip Ratio''"
- Cold start: A preparatory training stage (often SFT) to improve instruction adherence before RL. "a simple SFT stage as a cold start may be helpful"
- Cognitive behavior framework: A taxonomy for identifying and tracking reasoning behaviors in model outputs. "we adopt the cognitive behavior framework"
- Context length: The maximum number of tokens a model can process in its input and output buffer. "the model has a fixed maximum context length"
- DeepSeek-R1: A large reasoning model demonstrating emergent CoT and self-reflection via simple RL with rule-based rewards. "DeepSeek-R1 has shown that long chain-of-thought (CoT) reasoning can naturally emerge through a simple reinforcement learning (RL) framework with rule-based rewards"
- Enumeration: A reasoning behavior where the model systematically lists possible cases or options. "including
Backtracking",Verification",Subgoal Setting", andEnumeration"" - Exploration: The process of trying diverse reasoning trajectories or outputs during RL to discover correct solutions. "significantly penalizes exploration"
- Format reward: A reward that enforces strict answer formatting (e.g., LaTeX boxes), which may hinder exploration. "Enforcing rigid format reward (e.g., enclosing answers within boxes) ... penalizes exploration"
- GPQA-Diamond: A challenging benchmark testing domain-specific expertise in chemistry, physics, and biology. "GPQA-Diamond is a challenging benchmark that tests domain-specific expertise in chemistry, physics, and biology"
- GRPO: A reinforcement learning algorithm used to train reasoning models directly from base models. "Using GRPO as the RL algorithm, combined with several critical factors"
- Greedy decoding: A generation strategy that selects the most probable token at each step without sampling. "baselines use greedy decoding"
- GSM8K: A grade-school math word problem dataset commonly used for training and evaluation. "averaged on GSM8K, MATH500, Minerva Math, OlympiadBench, AIME24, and AMC23"
- IFEVAL: A benchmark that measures a model’s instruction-following capability. "IFEVAL measures instruction-following capability"
- Instruction-following: The ability of a model to adhere to given prompts and task specifications. "already exhibit instruction-following abilities"
- MATH500: A 500-problem subset from the MATH dataset used for evaluation. "averaged on GSM8K, MATH500, Minerva Math, OlympiadBench, AIME24, and AMC23"
- Minerva Math: A quantitative reasoning benchmark focusing on mathematical problem solving. "Minerva Math"
- MMLU: A benchmark assessing a model’s broad general knowledge across many subjects. "MMLU assesses the model's mastery of general knowledge"
- OlympiadBench: A benchmark of olympiad-level scientific problems for evaluating advanced reasoning. "OlympiadBench"
- Overthinking: A behavior where the model produces excessively long or redundant reasoning that may degrade performance. "often induces overthinking behaviors"
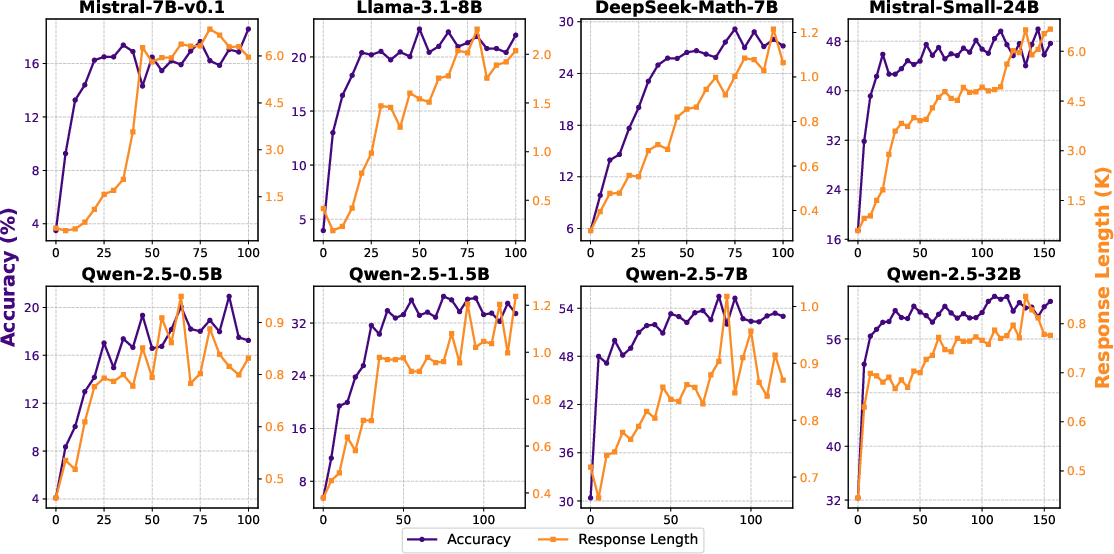
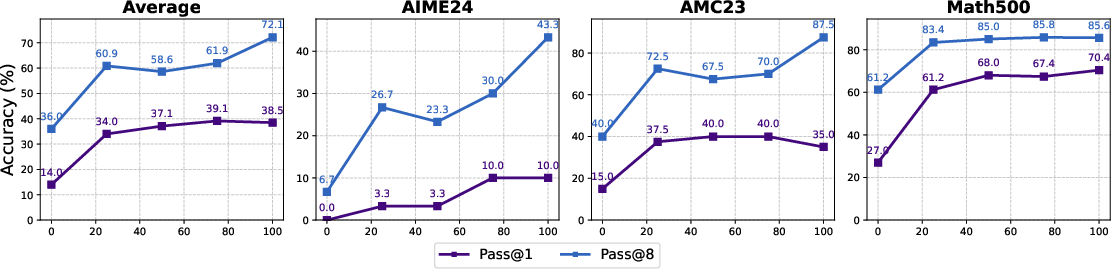
- Pass@k: The probability of obtaining a correct answer when sampling k independent generations. "zero RL training lifts pass@k accuracy by 10-30 absolute points"
- Reranking: Reordering candidate outputs without fundamentally changing the underlying distribution or reasoning ability. "not just reranking"
- Reward function: The mapping from generated responses to scalar signals used to guide RL (e.g., +1 for correct). "We use a rule-based reward function that assigns +1 for correct answers and 0 for incorrect ones"
- Rule-based reward: A deterministic reward scheme based on predefined rules, often correctness checking. "pure reinforcement learning (RL) with rule-based reward"
- SFT (Supervised Fine-Tuning): Training a model on labeled data to imitate desired outputs before or instead of RL. "without any prior supervised fine-tuning (SFT)"
- Subgoal Setting: A reasoning behavior where the model identifies intermediate targets to reach the final solution. "Smaller models ... prioritize learning the "Subgoal Setting" behavior"
- Temperature: A sampling parameter controlling randomness in generation; higher values increase diversity. "temperature=1.0"
- Top-p: Nucleus sampling threshold that restricts sampling to a subset of the probability mass. "top-p=0.95"
- Training collapse: A failure mode where training becomes unstable and model outputs degrade or become nonsensical. "often referred to as training collapse"
- Verification: A reasoning behavior where the model checks whether its steps or final answer satisfy the problem constraints. "``Verification""
- Zero RL training: Applying reinforcement learning directly to base models without prior SFT to induce reasoning. "This RL training paradigm starting from base models is often referred to as zero RL training"
Collections
Sign up for free to add this paper to one or more collections.