- The paper presents the SiFu learning paradigm, integrating static semantic mapping and dynamic signal propagation to achieve full model interpretability.
- The methodology uses a directed node-edge graph to emulate neural electrophysiological behaviors, enabling context-length independence without increased complexity.
- Experimental results confirm reduced training loss and competitive generative performance with fewer parameters compared to traditional Transformer architectures.
BriLLM: Brain-Inspired LLM
Introduction
The paper "BriLLM: Brain-inspired LLM" presents a novel approach to developing LLMs by drawing inspiration from neurocognitive principles. The research introduces the Signal Fully-connected flowing (SiFu) learning paradigm to tackle the limitations of traditional Transformer-based architectures, primarily focusing on issues of opacity, computational complexity, and context-length dependency.
SiFu Mechanism
SiFu learning adopts two essential features from brain functionality: static semantic mapping and dynamic signal propagation. These features are embodied in a directed graph where nodes correspond to tokens, and edges facilitate bidirectional signal flow. The model achieves full interpretability, arbitrary context-length processing without expanding its structural complexity, and dynamic signaling reminiscent of neural pathways.

Figure 1: The schematic illustration of SiFu mechanism.
The SiFu mechanism ensures that each node in the graph, corresponding to a particular token, remains fully interpretable, akin to the role of cortical regions in the brain. The edges enable signals to propagate dynamically, maximizing energy along paths of least resistance—a process analogous to neuronal electrophysiological activity.
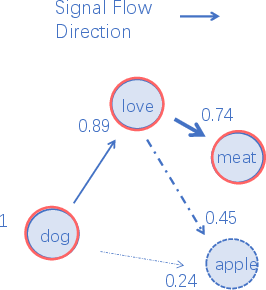
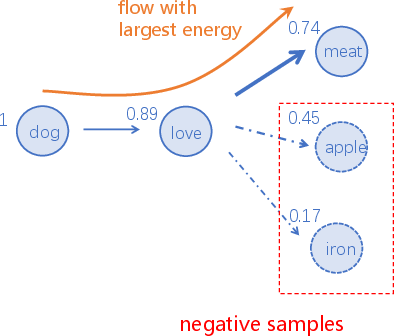
Figure 2: An illustration of SiFu Directed Graph (Numbers by the node denote energy scores).
BriLLM Architecture
BriLLM integrates the SiFu mechanism to create a fully interpretable model, mirroring global-scale brain processing. The architecture comprises GeLU-activated neurons representing tokens and bidirectional edges reflecting neural connectivity. Signal propagation in BriLLM is structured to emulate electrophysiological behavior observed in brain functions.
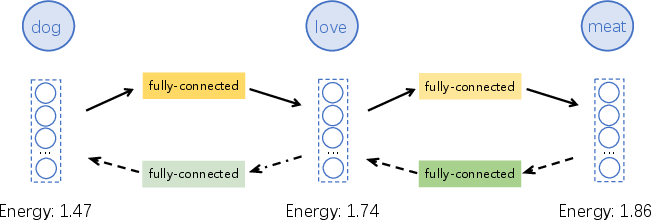
Figure 3: The architecture of BriLLM.
The model leverages a sequence of transformations to predict tokens, utilizing its node-edge framework and a set of learnable parameters to optimize signal propagation—all geared towards recreating dynamic neural responses.
Training and Scalability
BriLLM's architecture allows for efficient scalability while maintaining interpretability and performance. The model exhibits context-length independence, achieved by decoupling sequence length from model size, in contrast to the quadratic complexity of traditional frameworks like Transformers.
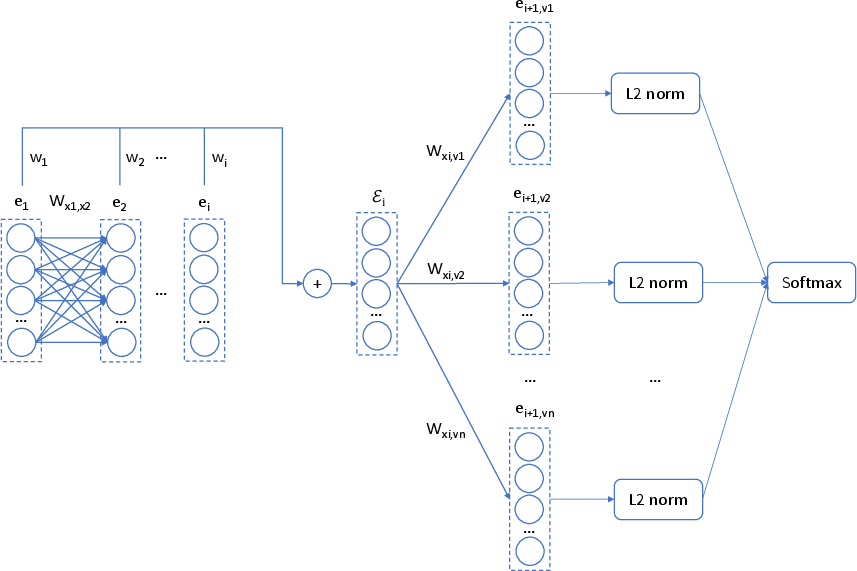
Figure 4: The training network of BriLLM for one training sample.
Training is executed with a sparse parameter approach, wherein low-frequency co-occurrences reduce the model's complexity, mimicking the sparse connectivity observed in biological neural networks. BriLLM achieves significant parameter reduction without sacrificing generative capability, as demonstrated in its stated performance benchmarks and case studies.
Experimental Results
BriLLM effectively matches the generative capacities of earlier LLMs, such as GPT-1, while providing comprehensive learning stability. The results show consistent reductions in training loss, affirming the model's design viability.
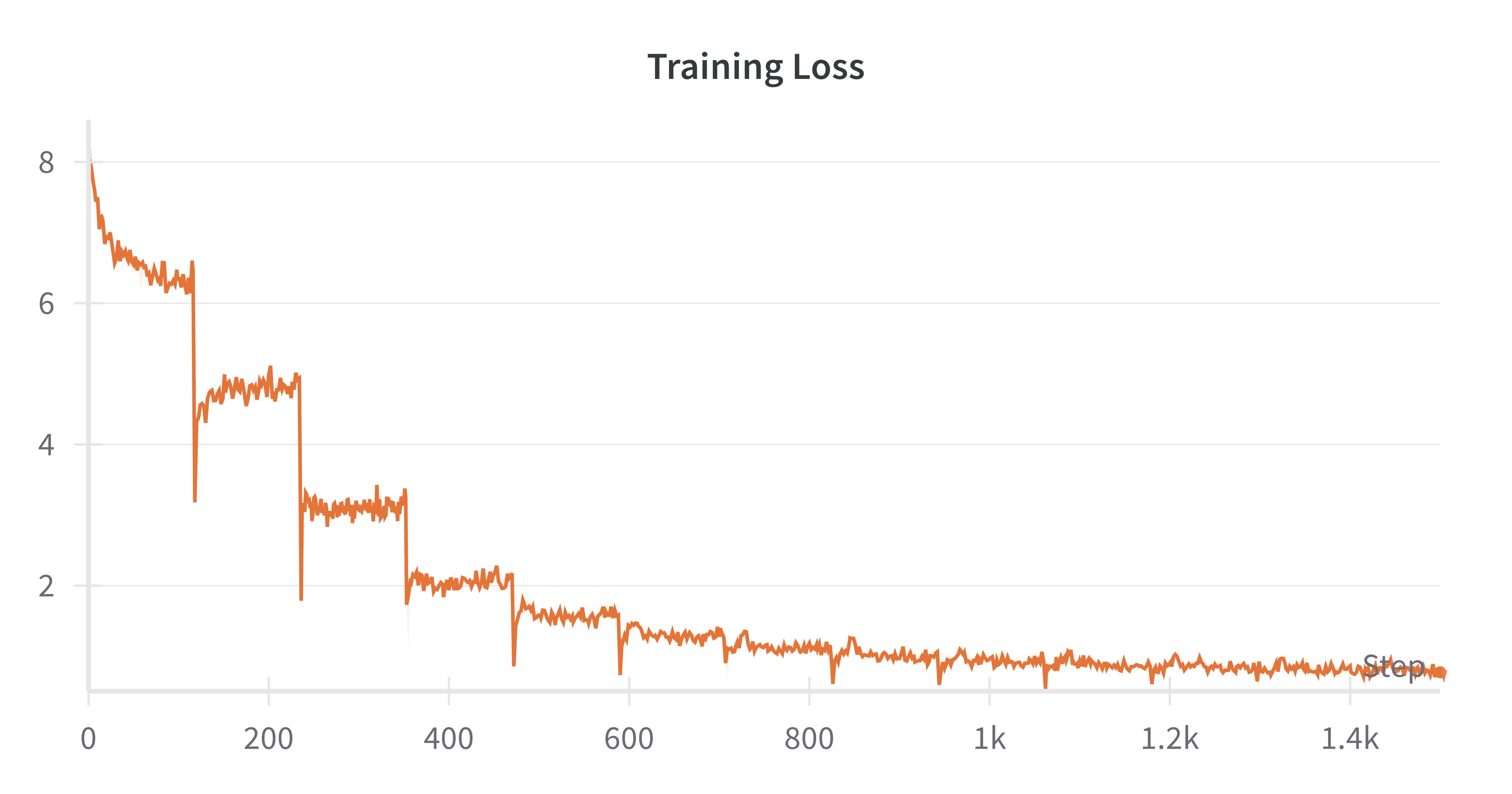
Figure 5: The training loss.
The experiments conducted validate BriLLM's ability to yield contextually appropriate continuations and maintain stable generative performance, even with reduced model sizes due to sparse training techniques.
Conclusion
The study presents a departure from conventional ML/DL paradigms by introducing a brain-inspired framework capable of addressing the core limitations of opacity and complexity. BriLLM provides a scalable and interpretable design that mimetically resembles global brain processing, paving the way for advancements toward AGI. Potential future developments include scaling capabilities, refining signal dynamics for enhanced cognition, and extending the model to multi-modal nodes, thus broadening its applicability and functionality.

