- The paper introduces Adaptive Mixture of Contexts (MoC) to replace dense self-attention with a dynamic routing mechanism for long video generation.
- MoC selects content-aligned chunks and enforces causality via mandatory anchors, ensuring efficient scaling and robust temporal consistency.
- Experiments demonstrate over 2× speedup and >7× FLOP reduction while maintaining quality in zero-shot and long-context settings.
Mixture of Contexts for Long Video Generation: Technical Summary and Implications
The paper addresses the challenge of long-context video generation, where maintaining memory and consistency over minute-scale or longer sequences is fundamentally limited by the quadratic computational cost of self-attention in Transformer-based diffusion models. The authors recast the problem as an internal information retrieval task, proposing the Adaptive Mixture of Contexts (MoC) as a learnable, sparse attention routing module. MoC enables each query token to dynamically select a small set of informative content-aligned chunks, augmented by mandatory anchors (captions and intra-shot edges), and enforces causality to prevent pathological loop closures.
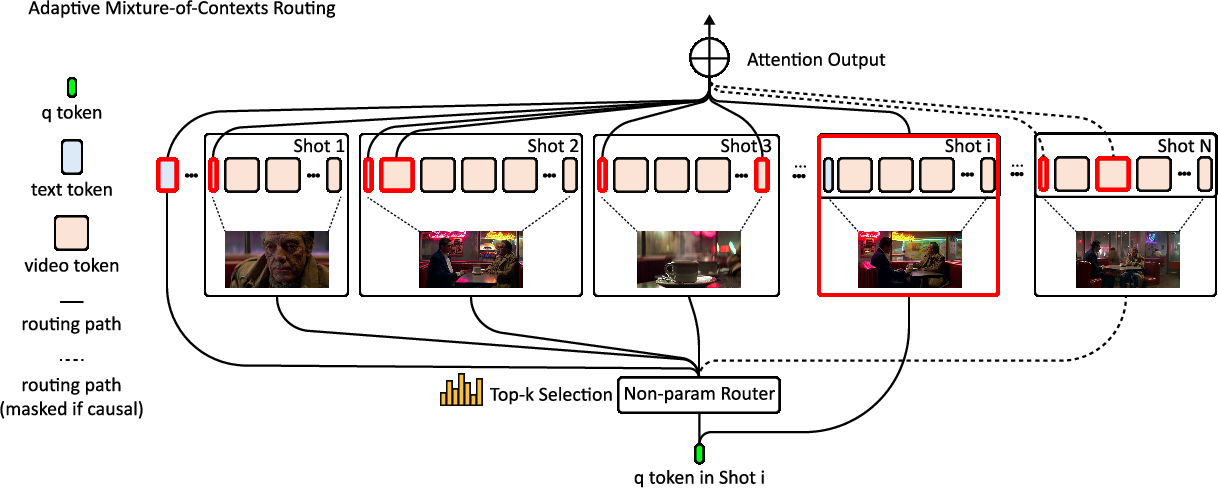
Figure 1: Overview of the Adaptive Mixture of Contexts, illustrating content-aligned chunking, top-k routing, and near-linear compute scaling via selective attention.
Methodology
Sparse Attention via Content-Aligned Routing
MoC replaces dense self-attention in the DiT backbone with a dynamic routing mechanism. The token stream is partitioned into semantically homogeneous chunks along natural video boundaries (frames, shots, captions). Each query token computes dot-product similarities with mean-pooled chunk keys, selects the top-k most relevant chunks, and attends to mandatory anchors. This approach is parameter-free yet trainable, as gradients flow through the selected keys and values, enabling the model to learn discriminative representations for retrieval.
The routing mask enforces causality, transforming the attention graph into a directed acyclic graph and preventing feedback loops that can trap information locally and degrade temporal coherence.

Figure 2: Loop closures without causality, demonstrating how bidirectional routing between chunks can isolate information and stall motion.
Regularization and Forced Links
To avoid underutilization of context (the "dead expert" problem), the authors introduce stochastic context drop-off (removing some top-k chunks) and drop-in (injecting random chunks), promoting robustness and balanced utilization. Forced cross-modal (caption) and intra-shot links ensure that every query attends to global semantic anchors and local continuity, stabilizing training and preserving fidelity.
Efficient Implementation
MoC is implemented with Flash-Attention kernels, leveraging content-aligned chunking and variable-length attention. The approach uses on-the-fly segment reduction for mean pooling, head-major token organization for memory efficiency, and a single var-len Flash-Attention call for kernel fusion. The resulting computational cost scales near-linearly with sequence length, as opposed to the quadratic scaling of dense attention.
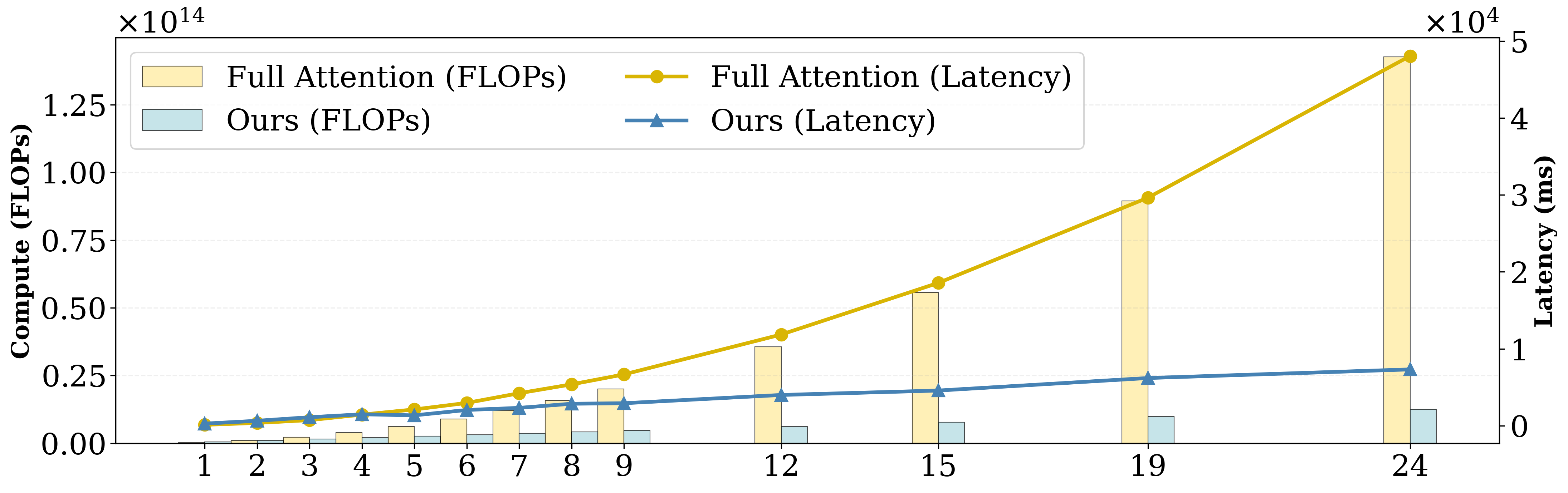
Figure 3: Performance benchmark showing near-linear scaling of MoC with respect to sequence length, compared to full attention.
Experimental Results
Quantitative Evaluation
On both single-shot (6k tokens) and multi-shot (180k tokens) video generation tasks, MoC matches or surpasses dense attention baselines on VBench metrics (subject/background consistency, motion smoothness, dynamic degree, aesthetic/image quality), despite aggressive sparsification (up to 85%). For long sequences, MoC achieves a 2.2× speedup and a >7× reduction in FLOPs, reallocating computation to salient events and improving motion diversity without sacrificing perceptual quality.
Qualitative Evaluation
Visual comparisons demonstrate that MoC maintains or improves fidelity and consistency, even with substantial pruning of attention calculations.

Figure 4: Single-shot video generation qualitative comparison, showing parity or improvement over the base model under aggressive sparsification.

Figure 5: Multi-shot video generation qualitative comparison, with MoC results visually indistinguishable from dense attention baselines.
Zero-Shot and Generalization
MoC can be applied to pretrained DiT models without fine-tuning, preserving subject identity, background layout, and coarse motion at >75% sparsity. This confirms that mean-pooled chunk keys provide a strong retrieval signal even in zero-shot settings.

Figure 6: Zero-shot sparsification, demonstrating retention of key video attributes with MoC applied to a pretrained model.
Ablation and Scaling
Ablation studies reveal that chunk size and top-k selection critically affect motion and consistency. Forced intra-shot and cross-modal links are essential for stable training and high performance. The authors also introduce an outer loop context routing mechanism for extremely long sequences, enabling hierarchical retrieval and maintaining stable positional encodings beyond trained lengths.
Theoretical and Practical Implications
MoC demonstrates that learned, structure-aware sparse attention can serve as a data-driven memory retrieval engine for long video generation. By removing the quadratic bottleneck, the approach enables minute-scale memory and consistency at the cost of short-video generation, without explicit heuristics or fixed selection rules. The method is generalizable to other backbones and robust to zero-shot application.
Practically, MoC provides a blueprint for scalable, controllable, and efficient long-video generative models, with direct implications for animation, simulation, and interactive storytelling. The approach is compatible with hardware-software co-design for further speedups, and its hierarchical routing is invariant to sequence length, avoiding positional embedding degradation.
Limitations and Future Directions
Current experiments are limited to the context lengths supported by LCT. Further scaling to hour-long or multi-million token sequences will require optimized kernels and hardware-aware implementations. Applications to video world models and broader generative tasks remain open for exploration.
Conclusion
Adaptive Mixture of Contexts reframes long-context video generation as an internal retrieval problem, leveraging learned sparse attention routing to achieve efficient, consistent, and scalable synthesis. The method overcomes the practical barriers of quadratic attention, reallocates computation to salient history, and unlocks emergent long-term memory in generative models. Future work should focus on hardware optimization, broader application domains, and responsible deployment strategies.