- The paper introduces a self-verification method that utilizes backward verification to reduce cumulative reasoning errors in large language models.
- It employs condition masking and sampling-based candidate generation to enhance performance in arithmetic, commonsense, and logical tasks.
- Experimental results demonstrate significant accuracy improvements across datasets, highlighting the method's robustness and scalability in data-scarce scenarios.
LLMs Are Better Reasoners with Self-Verification
Introduction
The paper investigates the reasoning capabilities of LLMs when equipped with self-verification mechanisms. Models like GPT-3 have leveraged chain of thought (CoT) prompting to perform reasoning tasks, yet are susceptible to cumulative errors due to their sensitivity to minor mistakes. This research introduces a novel self-verification strategy, paralleling human cognitive practices where individuals re-evaluate their conclusions to mitigate errors. The proposed method incorporates backward verification of solutions derived from CoT, enhancing the models' reasoning reliability without the need for additional verifiers.
Methodology
Forward Reasoning
Forward reasoning involves standard CoT prompting, where LLMs are tasked to solve a problem by generating a sequence of intermediate steps leading to a final answer. This process generates multiple candidate answers via sampling decoding, promoting diversity and enhancing robustness against prediction errors.

Figure 1: The answer of a question can be verified by masking and predicting the conditions of the original contexts. To mimic the self-verification ability of human, we predict the accuracy of fC.
Backward Verification
The verification process follows forward reasoning, focusing on assessing and validating each candidate answer's correctness. The process entails rewriting each candidate conclusion as a declarative statement and utilizing methods such as Condition Mask Verification (CMV) or True-False Item Verification (TFV) to ascertain consistency. These verifications involve masking certain conditions and re-predicting them, subsequently comparing the predicted conditions with the original values to calculate verification scores.
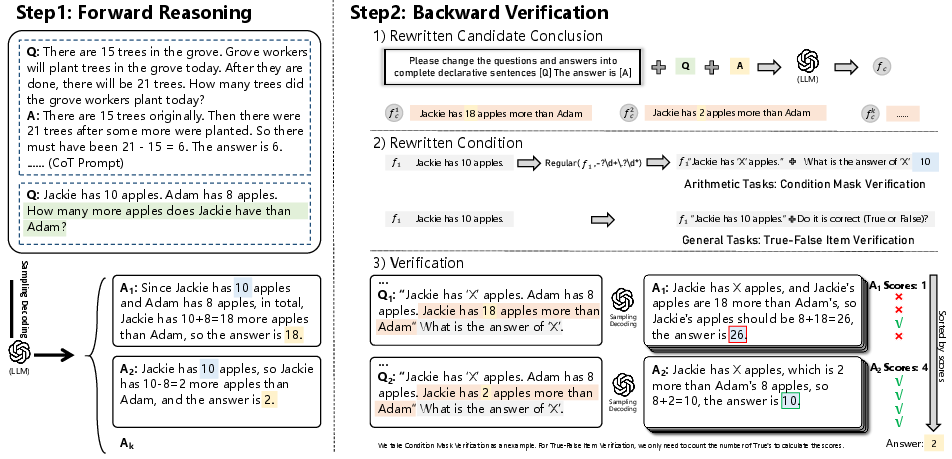
Figure 2: Example of self-verification. In step one, LLM generates candidate answers and forms different conclusions. Then, in step two, LLM verifies these conclusions in turn and computes the verification score.
Experimental Results
Extensive experiments conducted on various reasoning datasets demonstrated significant performance improvements when integrating self-verification. The model's accuracy in solving arithmetic, commonsense, and logical tasks noticeably increased as evidenced by comparison against traditional CoT and other forward reasoning methods.
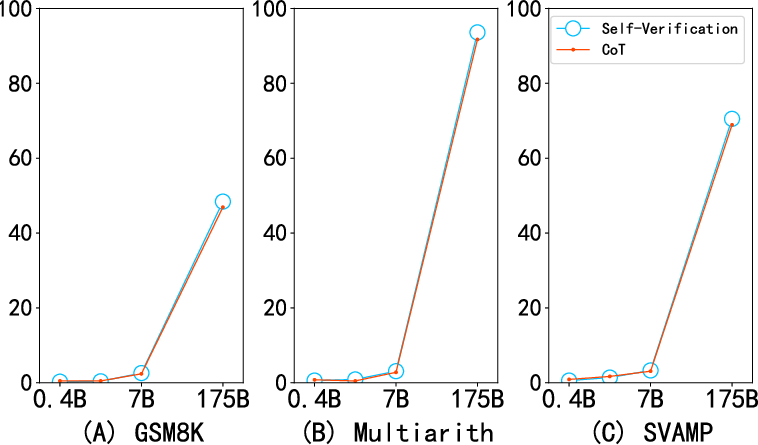
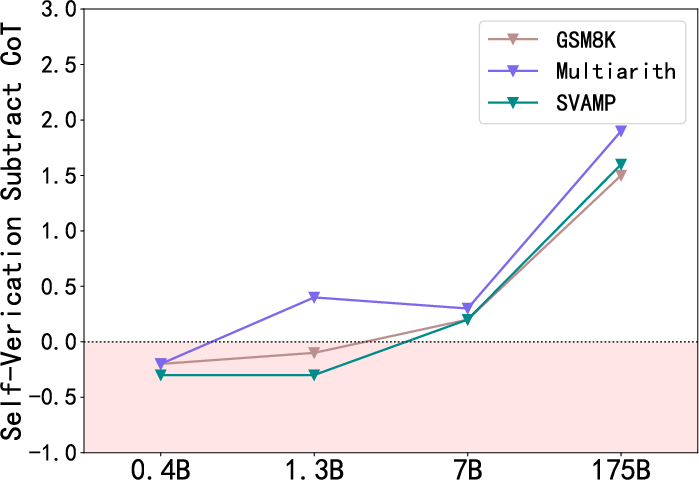
Figure 3: The self-verification ability of models with different sizes.
Discussion
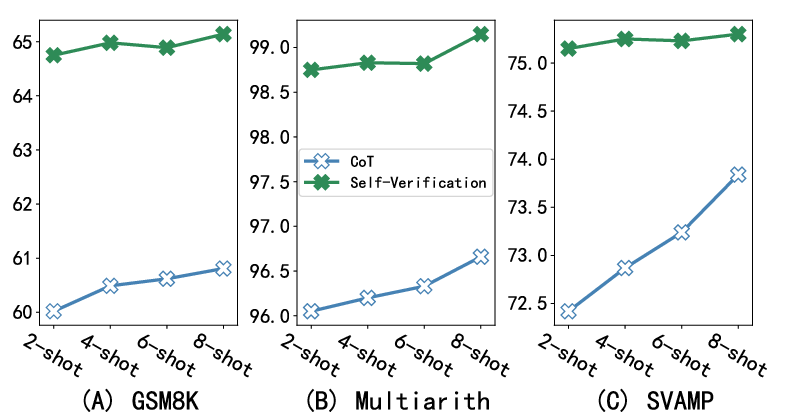
The introduction of self-verification without additional training data or verifiers positions this method as a scalable solution viable across multiple domains. The empirical results indicate that larger models, characterized by superior reasoning capabilities, benefit more significantly from self-verification. Interestingly, the robustness of the approach with limited data, such as low-shot scenarios, underscores its utility in data-constrained environments.
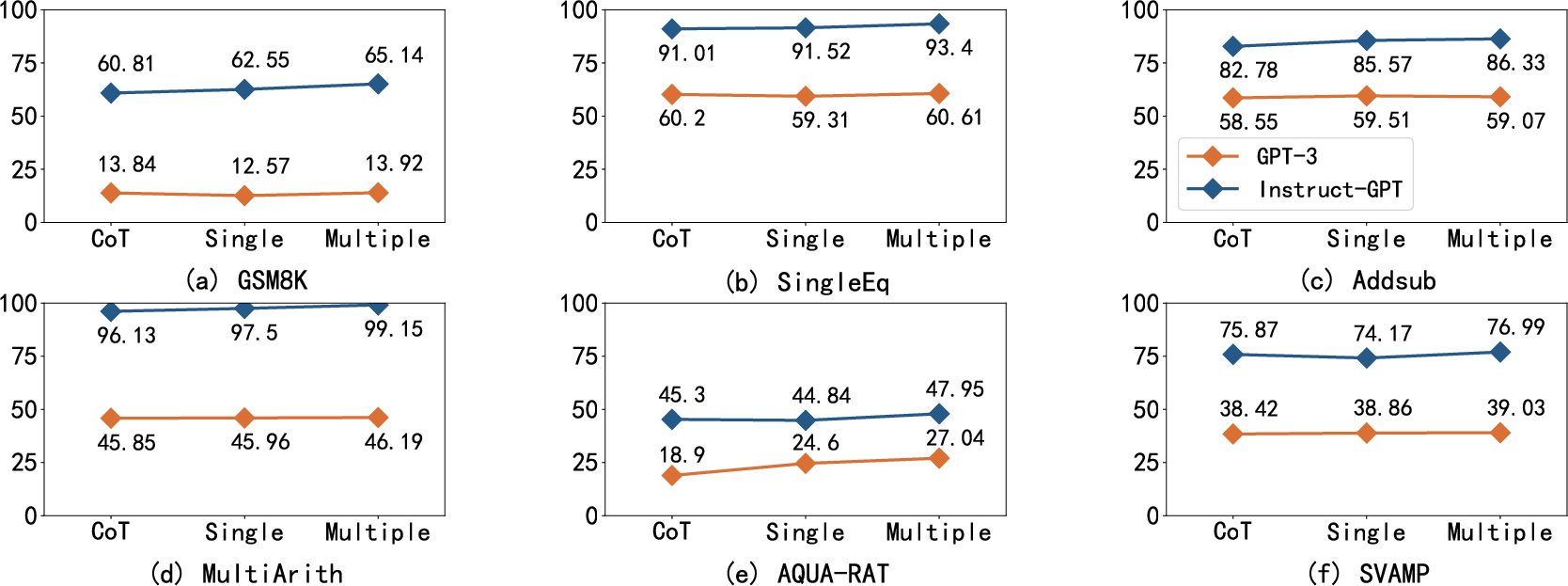
Figure 5: Comparison of problem solve rate (\%) between single-condition verification and multiple-condition verification.
Conclusion
The research asserts that LLMs equipped with self-verification mechanisms exhibit enhanced reasoning capabilities. By utilizing backward verification, these models can efficiently self-assess and validate their predictions, thus improving the accuracy and reliability of reasoning tasks. Future explorations could focus on optimizing backward verification for diverse reasoning challenges and further honing LLM reasoning by integrating advanced self-verification strategies.