- The paper introduces DiffuRNN, a novel architecture that unifies diffusion processes with local nonlinear updates to efficiently capture global sequence dependencies.
- It integrates learnable diffusion kernels and scalable linear attention to enable full parallelization and effective temporal information propagation.
- Experimental evaluations on benchmarks like ImageNet, CIFAR-10, and GLUE demonstrate DiffuRNN’s superior accuracy and reduced computational cost compared to traditional models.
DiffuRNN: Harnessing Diffusion Processes for Sequential Data
Introduction to DiffuRNN
DiffuRNN introduces an innovative recurrent architecture for sequence modeling, which adapts diffusion processes to capture global interactions more efficiently than traditional models. DiffuRNN incorporates diffusion kernels for global dependencies, local nonlinear updates, and a novel diffusion-inspired attention mechanism. This allows full parallelization across time steps while maintaining temporal resolution. Unlike conventional RNNs that struggle with long-range dependencies due to their sequential nature, or transformer models that incur high computational costs, DiffuRNN offers an efficient alternative by reinterpreting sequence data processing as a unified diffusion process.
DiffuRNN Architecture
The core of DiffuRNN lies in its integration of diffusion modules with localized updates and linear attention mechanisms, forming a unified architecture.
Diffusion Module:
Allows gradual propagation of information across time steps. The diffusion kernel captures temporal causality and locality, where the kernel's parameters are learnable and guide information flow based on temporal relationships.
Local Update:
Ensures fine-grained temporal dynamics aren't lost amidst global interactions by incorporating a nonlinear function to adjust token information locally.
Linear Attention Module:
Unlike conventional self-attention mechanisms, the linear approach provides scalable attention capabilities without incurring quadratic complexity, achieving efficient information aggregation across sequences.
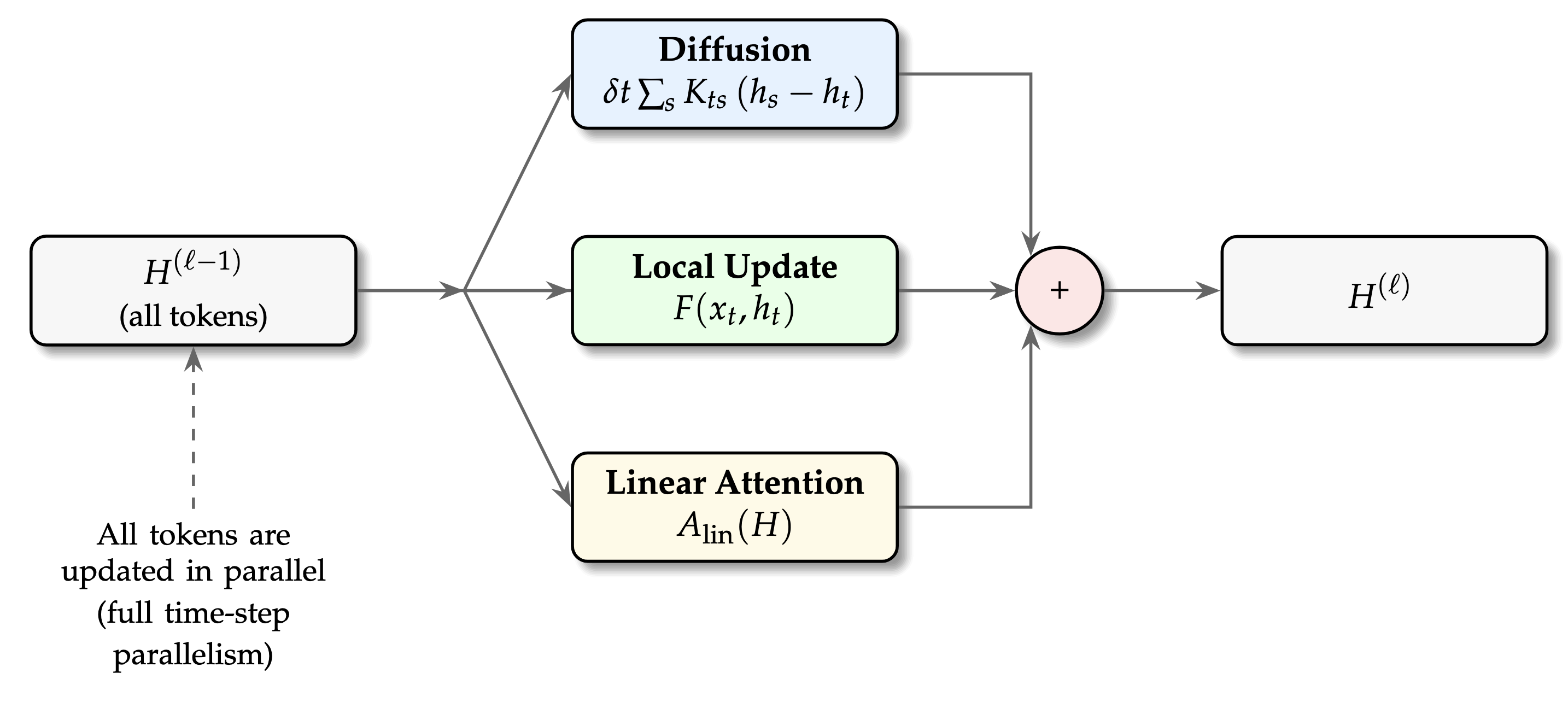
Figure 1: DiffuRNN: A unified architecture that integrates diffusion, local updates, and linear attention for parallel token processing.
Theoretical Foundation
DiffuRNN is underpinned by rigorous theoretical analysis ensuring that diffusion processes inherently capture global dependencies. Given the conditions that the diffusion kernel is non-negative and the underlying graph structure is strongly connected, every output token in the sequence is influenced by all input tokens after numerous diffusion iterations. This guarantees comprehensive interaction across the sequence irrespective of distance in time.
Experimental Evaluation
DiffuRNN was evaluated across various benchmarks, demonstrating clear advancements over traditional models.
ImageNet:
DiffuRNN achieves superior Top-1 and Top-5 accuracies compared to Vision Transformer (ViT) models across all scales with fewer parameters and reduced computational cost.
CIFAR-10:
DiffuRNN shows faster convergence and higher test accuracy, outperforming ViT. This success is attributed to the diffusion mechanism efficiently capturing sequential variations.
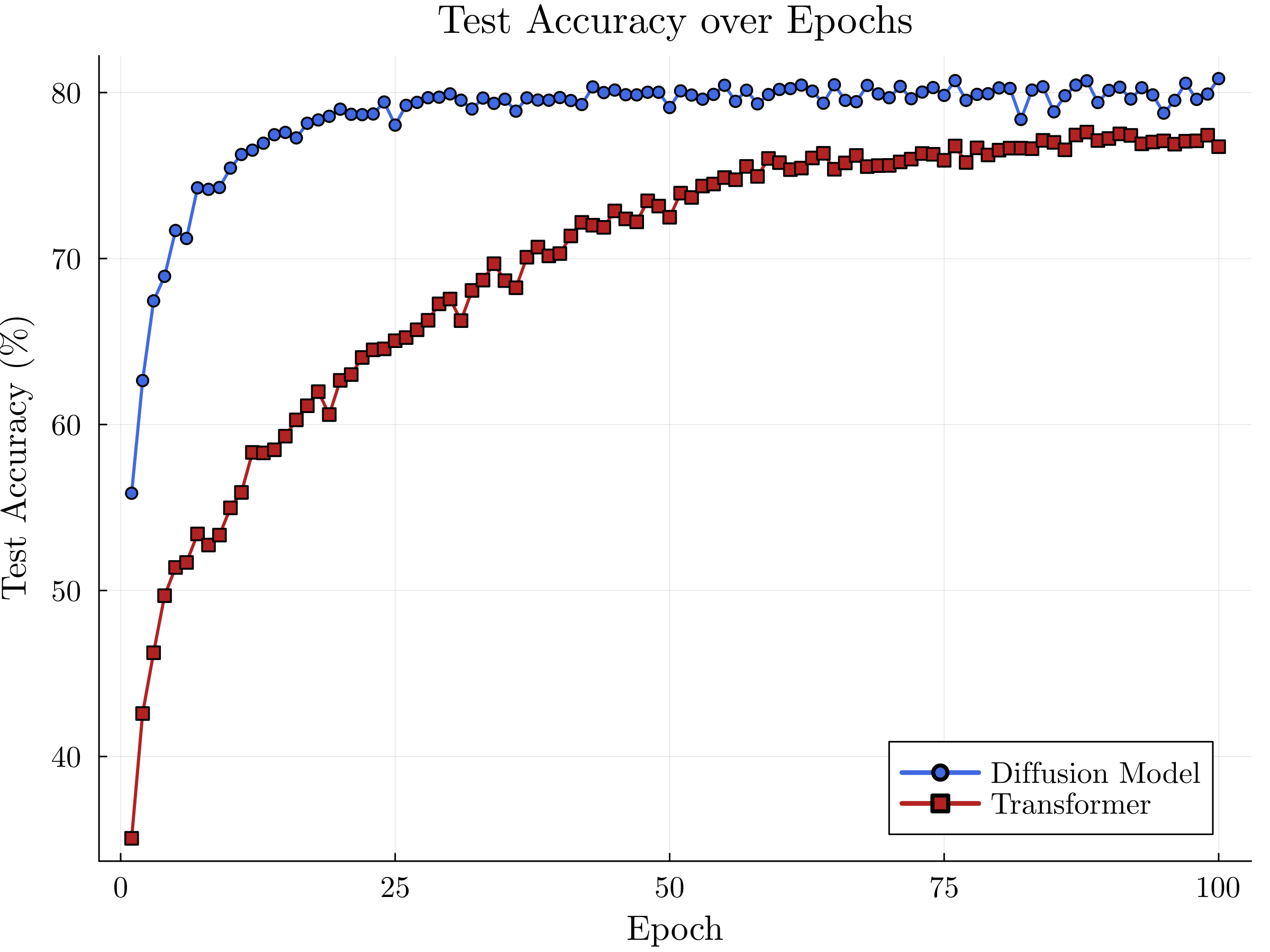
Figure 2: Training accuracy comparison between ViT and DiffuRNN on CIFAR-10.
GLUE Benchmark:
In natural language tasks, DiffuRNN holds competitive ground with models like BERT and RoBERTa, reflecting its versatility beyond visual tasks.
Practical Implications and Future Work
DiffuRNN’s diffusion-based framework presents significant practical value by balancing computational efficiency with effective representation learning. It opens avenues for extending sequential architectures with enhanced non-linear attention mechanisms. Future research should explore larger datasets for further validation and refine the diffusion kernel parameters.
Conclusion
DiffuRNN represents a strategic shift in sequence modeling by leveraging diffusion processes to enable efficient global interaction combined with local detail retention. The empirical success demonstrated on benchmarks and the theoretical rigour behind global dependency capture make it a promising approach for advancing both vision and language processing tasks, offering a framework adaptable to diverse application demands.

