- The paper reveals that reference benchmark selection can drastically alter agreement scores and impact evaluation conclusions.
- The methodology demonstrates that model subset size and sampling strategy significantly affect the stability and reliability of BAT outcomes.
- The paper introduces BenchBench, a Python framework that aggregates benchmarks and uses data-driven metrics to standardize LLM evaluations.
Methodological Foundations and Implications of Benchmark Agreement Testing (BAT) in LLM Evaluation
Introduction
The proliferation of LLM benchmarks in recent years has introduced significant methodological ambiguity regarding how these benchmarks should be validated, compared, and selected for model evaluation. The paper "Do These LLM Benchmarks Agree? Fixing Benchmark Evaluation with BenchBench" (2407.13696) scrutinizes the landscape of Benchmark Agreement Testing (BAT), providing a rigorous analysis of over 40 prominent benchmarks and proposing standardized practices to enhance robustness and reproducibility in LLM evaluation procedures. The authors further introduce the BenchBench Python package and leaderboard, operationalizing their recommendations for systematic BAT.
Analysis of Methodological Choices in BAT
Reference Benchmark Selection
The validity of BAT outcomes is acutely sensitive to the choice of reference benchmark. The authors provide empirical evidence that different (even plausibly similar) reference benchmarks produce widely divergent agreement scores for the same target benchmark. For instance, when Alpaca V2 is correlated against MT-Bench and LMSys Arena, the Kendall-tau agreement scores vary dramatically, undermining any conclusions derived from single-benchmark comparisons.
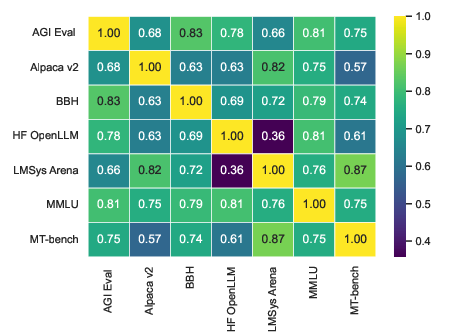
Figure 1: Agreement scores across benchmark pairs reveal substantial variability, highlighting the impact of reference benchmark selection on BAT outcomes.
The recommended mitigation is aggregation over multiple reference benchmarks, thereby constructing a higher-fidelity measure of construct validity via averaged model win-rates. This approach is rooted in convergent validity frameworks, ensuring statistical stability and greater resilience against idiosyncratic benchmark behaviors.
Model Selection and Sampling
The choice and sampling strategy for model subsets represent another major source of variance. BAT results computed over small or non-representative model subsets are shown to be unreliable, with substantial fluctuations in agreement metrics as the subset size and selection granularity change. Notably, correlation scores decrease when BAT is conducted over closely ranked (adjacent) models—those whose performance differences, and thus rank stabilities, are minimal.
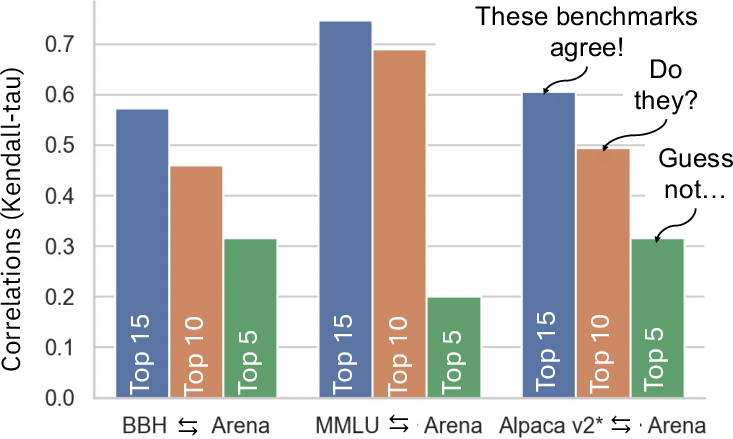
Figure 2: Benchmark agreement is highly sensitive to the number and rank proximity of models considered in the analysis.
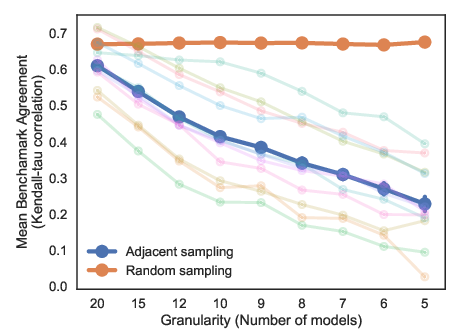
Figure 3: Average correlation scores diminish for contiguous (adjacent) subsets versus random sampling, emphasizing the necessity of diverse, sizeable model pools for robust BAT.
Empirically, the authors demonstrate that using at least 10 randomly sampled models—and reporting granular results across several resolutions—significantly reduces BAT result variance, improving interpretability and practical relevance.
Correlation Metric Choice and Thresholding
The lack of consensus on which correlation metric (Kendall-tau for rank, Pearson for scores) and threshold should define "agreement" further clouds BAT practice. The paper shows a strong linear relationship between the two metrics (Pearson vs. Kendall-tau), but a consistent bias necessitates data-driven, benchmark-specific thresholding approaches.
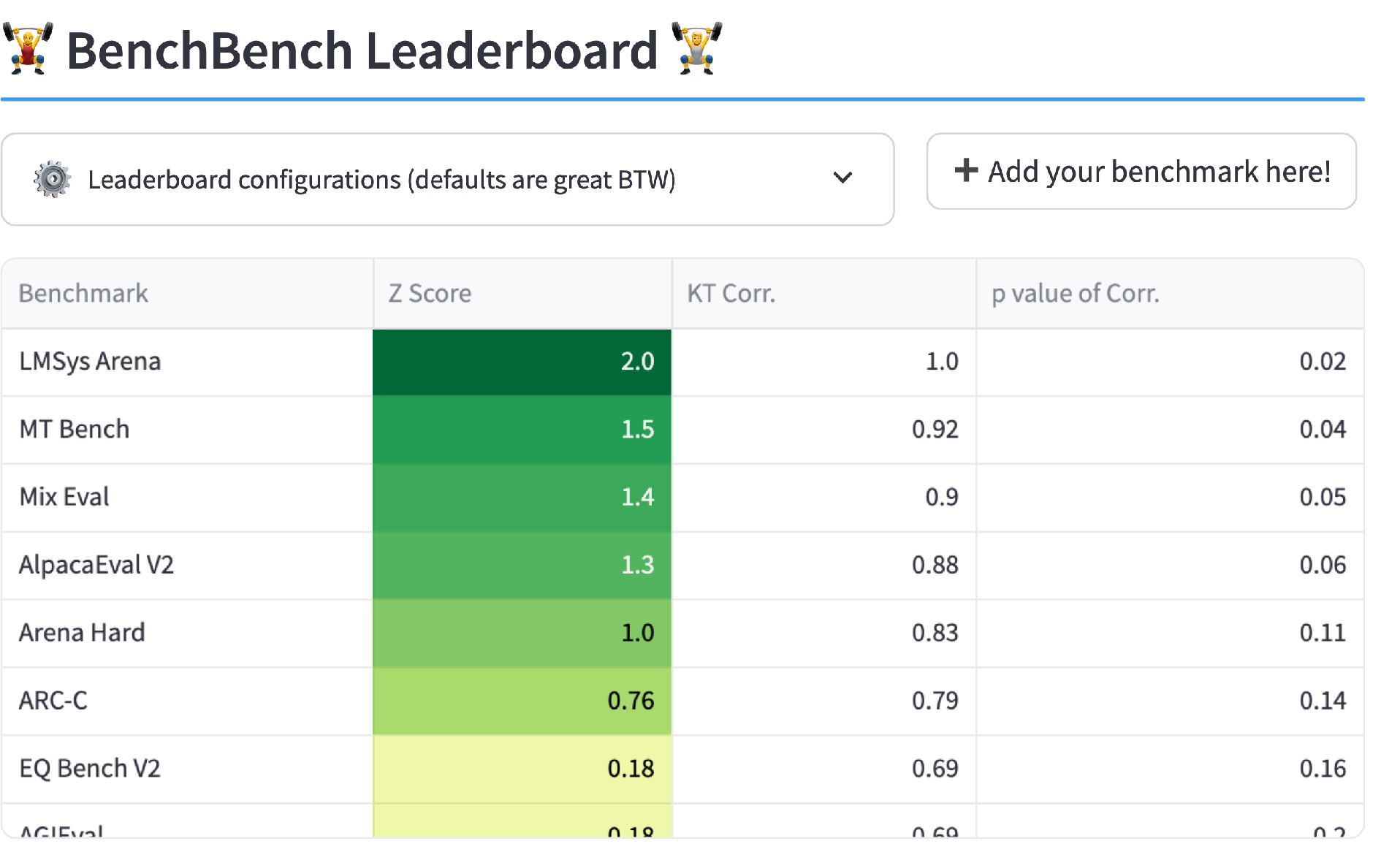
Figure 4: Linear dependence between Pearson and Kendall-tau metrics, with a bias factor requiring metric-specific threshold calibration.
Rather than providing fixed thresholds, the authors recommend calculating Z-scores relative to the empirical distribution of agreement scores, thus interpreting BAT outcomes as a function of the current ecosystem consensus rather than arbitrary cutoffs.
Impact of Model Subset Size
A key finding is the inverse relationship between model subset size and BAT agreement variance. Larger representative model sets contribute to reproducible BAT decision-making.
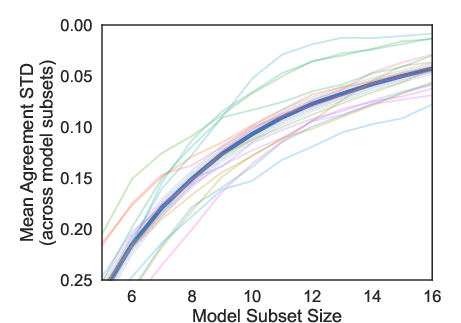
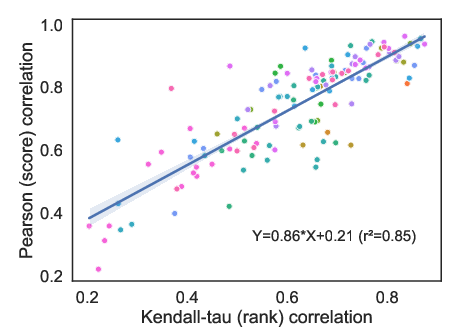
Figure 5: Standard deviation of agreement scores decreases as model subset size increases, underscoring the importance of large, diverse model pools.
BenchBench Package and Leaderboard: Operationalizing BAT Best Practices
To synchronize community methodologies, the authors release BenchBench—a Python framework that enforces the outlined best practices. BenchBench automatically aggregates benchmarks, recommends unbiased model subsets, and computes data-driven agreement metrics and thresholds, facilitating reproducible BAT workflows. The meta-benchmark leaderboard enables users to rank benchmarks by agreement with selected references, using Z-score-based interpretations.
Figure 4: BenchBench-leaderboard operationalizes meta-BAT, dynamically ranking benchmarks according to their agreement with aggregated references.
Practical and Theoretical Implications
Standardization of Benchmark Validation
The formalization and automation of BAT address reproducibility and comparability—critical issues for both LLM developers and benchmark creators. By reducing the methodological degrees of freedom, the community can objectively assess benchmarks’ validity, retire saturated or irrelevant benchmarks, and identify genuinely novel evaluative traits.
Nuanced Interpretation of Agreement Metrics
High benchmark agreement should not be conflated with identical construct measurement; strong LLMs often excel broadly, creating spurious correlations among benchmarks with only surface-level overlap. Similarly, low agreement—especially among top-tier or closely packed models—may signal either true trait divergence or poor benchmark reliability, necessitating further reliability analysis.
(Figure 6)
Figure 6: Benchmark agreement scores decline when focusing on top-tier models, reflecting challenges in differentiating high-performing LLMs.
Evolution of LLM Evaluation Methodologies
The BenchBench framework, designed for continual benchmark ingestion and dynamic agreement evaluation, fosters adaptive evaluation regimes responsive to ongoing LLM advances and benchmark evolution. This supports not only efficient model validation, but also systematic benchmarking research and meta-analysis.
Conclusion
"Do These LLM Benchmarks Agree? Fixing Benchmark Evaluation with BenchBench" (2407.13696) delivers a stringent critique and methodological overhaul of Benchmark Agreement Testing in the LLM field. The empirical analysis highlights the substantial variance introduced by arbitrary choices regarding reference benchmarks, model subsets, and correlation metrics. The proposed aggregate-based, data-driven practices—embodied in the BenchBench package—yield robust, reproducible, and interpretable BAT results. This work will facilitate more principled benchmark construction, selection, and retirement, catalyzing further theoretical inquiry into LLM evaluation methodology and fostering reliable practical adoption across the AI community.