Logic Augmented Generation
Abstract: Semantic Knowledge Graphs (SKG) face challenges with scalability, flexibility, contextual understanding, and handling unstructured or ambiguous information. However, they offer formal and structured knowledge enabling highly interpretable and reliable results by means of reasoning and querying. LLMs overcome those limitations making them suitable in open-ended tasks and unstructured environments. Nevertheless, LLMs are neither interpretable nor reliable. To solve the dichotomy between LLMs and SKGs we envision Logic Augmented Generation (LAG) that combines the benefits of the two worlds. LAG uses LLMs as Reactive Continuous Knowledge Graphs that can generate potentially infinite relations and tacit knowledge on-demand. SKGs are key for injecting a discrete heuristic dimension with clear logical and factual boundaries. We exemplify LAG in two tasks of collective intelligence, i.e., medical diagnostics and climate projections. Understanding the properties and limitations of LAG, which are still mostly unknown, is of utmost importance for enabling a variety of tasks involving tacit knowledge in order to provide interpretable and effective results.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Logic Augmented Generation”
What this paper is about
This paper introduces a new way to combine two kinds of AI so they work better together:
- Semantic Knowledge Graphs (SKGs): tidy “maps of facts” with clear rules. They’re great for being precise and explainable, but they struggle with messy, real‑world text and changing situations.
- LLMs: the smart text generators behind chatbots. They’re great at handling messy, unstructured information and giving context, but they can be hard to trust and explain.
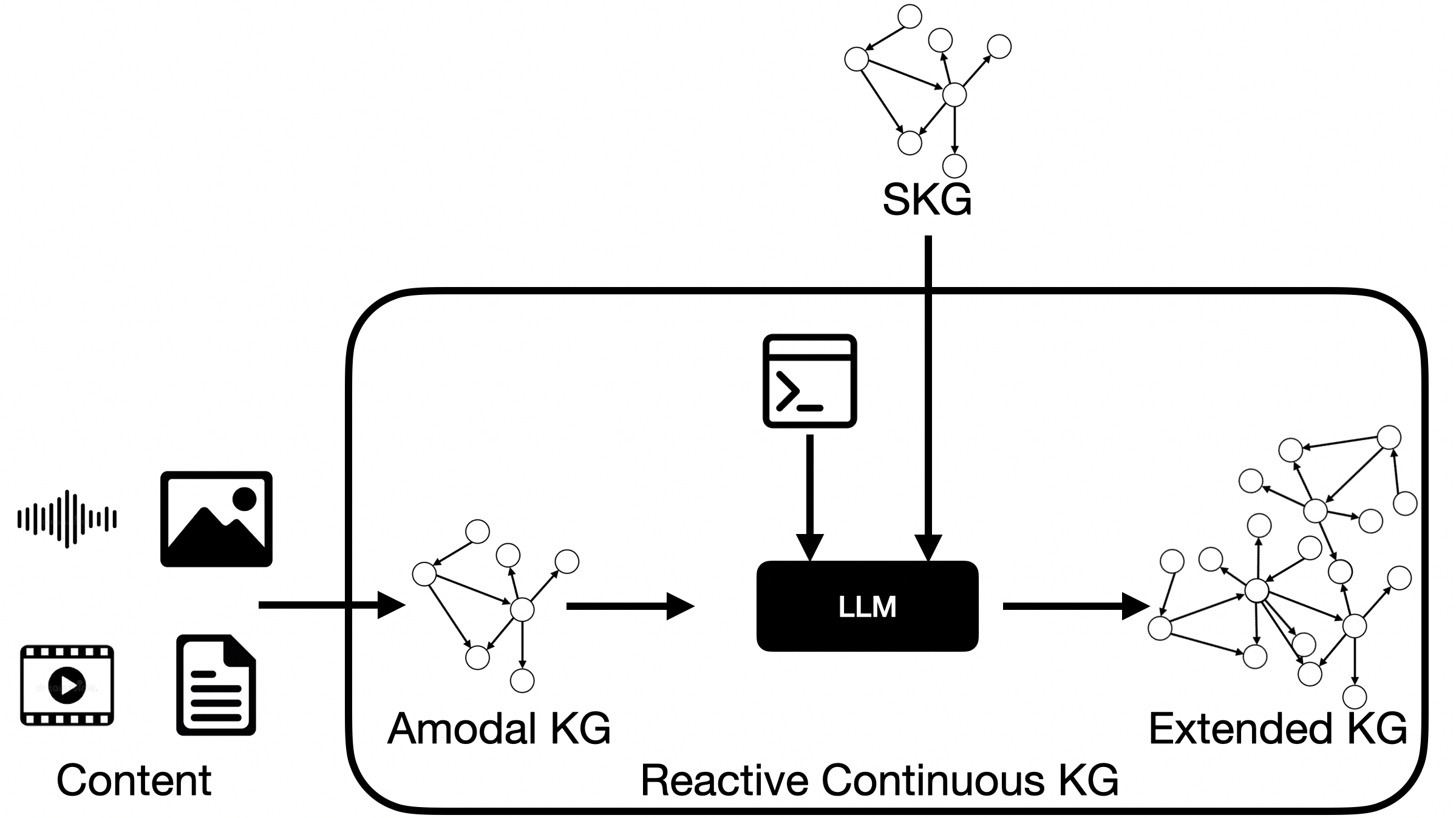
The authors propose “Logic Augmented Generation” (LAG), a method that uses the logic and rules of SKGs to guide the creativity of LLMs. The goal is to get the best of both worlds: flexible answers that are also reliable and explainable.
The main questions the paper asks
Here are the ideas the authors explore, in everyday terms:
- How can we use LLMs to add helpful, contextual ideas to a “fact map” without making it messy or wrong?
- Can we treat an LLM like a kind of “reactive” knowledge graph that updates itself when you feed it new information?
- How do we set boundaries so the LLM’s guesses stay plausible and consistent with known facts?
- Could this help groups of experts work together better in complex problems, like diagnosing a medical case or making climate projections?
How their approach works (in plain language)
Think of this as teamwork between a careful librarian and a creative storyteller:
- The SKG is the librarian: it stores facts in a tidy, rule‑based way (who did what, when, and how things relate).
- The LLM is the storyteller: it can read messy notes, understand the situation, and suggest reasonable connections that aren’t written down explicitly.
The LAG method connects them in a simple pipeline:
- Turn text into a “fact map” (SKG)
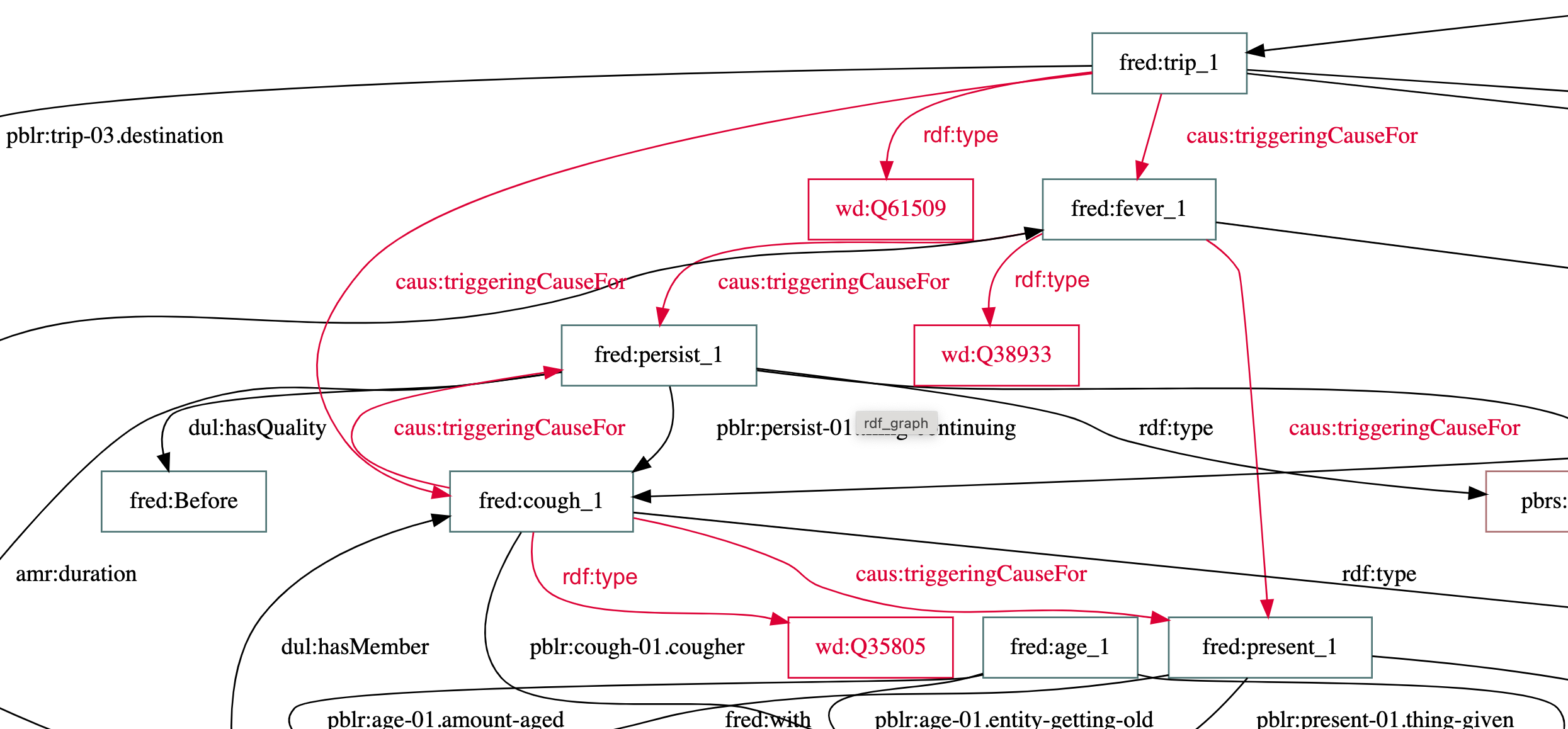
- A tool called FRED reads sentences and builds a small, structured web of facts (who, what, where, when).
- Example: “A 38-year-old man has fever and dry cough after a trip” becomes nodes and links like Person → hasSymptom → Fever.
- Give that fact map to the LLM with clear instructions
- The LLM gets the SKG plus prompts (instructions) that set logical and factual boundaries.
- The LLM adds “tacit knowledge” — helpful background knowledge that people often use but don’t say out loud (like “travel can increase infection risk”).
- Check and extend the fact map within rules
- The LLM’s suggestions are turned into new fact links, but only if they fit the rules of the original SKG and match trusted sources (like Wikidata).
- The result is an “extended” SKG: still explainable, now richer in context.
The authors call the LLM acting this way a “Reactive Continuous Knowledge Graph” (RCKG): it reacts to input and can generate many possible connections, but must be guided by logic to stay useful and trustworthy.
What they found and why it matters
The paper is mainly a proposal and early demonstration, not a large experiment. Still, they show promising outcomes:
- A working architecture: They describe and prototype how to connect SKGs, LLMs, prompts, and external knowledge bases into one system (LAG).
- More complete, still explainable knowledge: In a medical example, the system adds a likely causal link (recent travel → may trigger infection) that wasn’t stated outright, while keeping the relationships clear and checkable.
- Better support for teamwork: In fields like medicine and climate science where experts share diverse inputs (notes, reports, observations), LAG helps harmonize information and surface key assumptions that drive decisions.
- Clear boundaries for AI “guesses”: The authors highlight that LLMs often provide “plausible” ideas that aren’t guaranteed true. LAG keeps those ideas inside logical, factual boundaries, reducing errors.
- A research roadmap: They identify hard but important challenges—like writing better prompts (e.g., metacognitive prompting), representing “tacit” knowledge, and blending “truth-preserving” logic (strict facts) with “plausibility-preserving” reasoning (good guesses).
Why this could be a big deal
If developed further, LAG could:
- Make AI systems both smart and trustworthy in high‑stakes areas like medical diagnostics and climate services.
- Help groups of experts communicate better by making hidden assumptions explicit and machine‑checkable.
- Reduce costly mistakes by keeping creative AI within the rails of verified knowledge.
- Speed up insights from messy, real-world information (text, notes, sensor data) without losing clarity or accountability.
In short, Logic Augmented Generation is about giving creative AI a “map and a rulebook,” so it can explore ideas while staying grounded in facts—exactly what’s needed for complex, real-world decision‑making.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on it.
- Formal semantics for RCKGs: define a plausibility-preserving logic (operators, entailment, necessity/possibility) and its interface with OWL’s truth-preserving semantics, including soundness/completeness and conditions for safe mixed reasoning.
- Consistency management: algorithms to detect, explain, and repair contradictions between LLM-generated triples and SKG facts (e.g., paraconsistent reasoning, belief revision, or argumentation-based conflict resolution).
- Boundary enforcement: concrete mechanisms to constrain LLM generation to SKG schemas and axioms (e.g., constrained decoding, SHACL/ShEx validation, automatic repair strategies), with measurable boundary-violation rates.
- Uncertainty and confidence: methods to quantify, calibrate, and propagate uncertainty of LLM-generated triples (e.g., confidence scores, conformal prediction, temperature scaling) through hybrid symbolic–neural reasoning.
- Provenance and accountability: standardized provenance capture (e.g., PROV-O) for LLM-generated statements, including source attribution, prompts used, model version, and justification traces usable in audits.
- Prompt engineering protocols: systematic procedures to translate SKG context into prompts (including metacognitive prompting), with ablation studies and automated prompt optimization strategies across domains.
- Evaluation framework: benchmarks, datasets, and metrics for tacit knowledge extraction quality, hybrid consistency, interpretability, factuality, and downstream task performance (medical and climate use cases).
- Comparative baselines: rigorous comparisons against SKG-only, LLM-only (RAG/graph extraction), and existing continuous/dynamic KG methods, including ablating each LAG component.
- Scalability and performance: analysis of computational costs (latency, memory, throughput) for large SKGs and real-time settings; strategies for caching, batching, and incremental updates.
- Temporal reasoning: methods to handle time-stamped facts, streaming data, and evolving contexts; integration of temporal logics with plausibility-based inferences in RCKGs.
- Multimodal grounding: procedures to extract and align knowledge from non-text signals (images, audio, sensors) into RCKGs and reconcile them with amodal SKGs; modality-specific error analysis.
- Tacit operator taxonomy: formalization and implementation of distinct tacit operators (e.g., social implicature, affective evocation, evaluative judgment, causal consequence, metaphorical blend) with testable reasoning behaviors.
- Non-monotonicity and context control: concrete mechanisms for default reasoning, context scoping/switching, and revocation of tacit inferences without destabilizing the SKG.
- Schema evolution and ontology learning: workflows to propose, vet, and integrate schema updates suggested by RCKGs (e.g., new classes/relations), with human-in-the-loop approvals and change tracking.
- Entity alignment and reconciliation: robust, auditable entity linking across external KGs (e.g., SNOMED-CT, ICD-10, Wikidata, CMIP), including error handling, coverage analysis, and license-aware mappings.
- Guardrails and safety: techniques to prevent unsafe, biased, or privacy-violating content in generated triples; red-teaming, bias audits, and domain-specific safety checklists for medical/climate outputs.
- Human-in-the-loop protocols: interfaces and procedures for expert review, feedback incorporation, dispute resolution, and collective decision aggregation over extended KGs.
- Acceptance criteria: policy and thresholds for when LLM-generated knowledge is admitted into the extended SKG (e.g., confidence, corroboration, expert approval), and when it is quarantined or rejected.
- Query support and integration: methods to guarantee that extended KGs remain efficiently queryable (SPARQL), including indexing strategies and cross-layer query planning over SKG+RCKG outputs.
- Domain transfer: strategies for adapting LAG across domains (medical → climate → others), including few-shot domain conditioning and analysis of failure modes under distribution shift.
- Climate-specific constraints: incorporation of physical and policy constraints (e.g., conservation laws, scenario bounds) into generation and validation for climate projections; domain-specific evaluation tasks.
- Numeric and unit consistency: handling of measurements, units, and dimensional analysis in LLM-generated triples; reconciliation with SKG datatypes and numeric constraints.
- Cost and sustainability: measurement and optimization of LLM inference costs and energy footprint for continuous knowledge generation in operational settings.
- Reproducibility: release of code, prompts, models, and datasets; documentation of model versions and seeds; standardized experiment protocols to ensure replicability of LAG results.
- Legal and ethical compliance: procedures for data privacy (e.g., GDPR) in patient scenarios, IP/license handling for generated content, and accountability for decisions influenced by LAG outputs.
- Failure analysis: systematic characterization of LAG failure modes (e.g., hallucinations within constraints, boundary overfitting, brittle prompts) and robust mitigation strategies.
- Trade-off studies: empirical analysis of how stricter logical constraints affect generative richness and utility of tacit knowledge; guidelines for tuning constraint strength per task.
- Lifecycle governance: policies and tooling for monitoring drift, versioning SKG/RCKG components, and deprecating or updating generated knowledge over time.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging existing components described in the paper (e.g., FRED, Framester semantics, Text2AMR2FRED, Wikidata reconciliation, ontology design patterns, DOLCE-Zero) and widely available LLMs and graph technologies.
- Clinical decision support with interpretable differential diagnosis (collective intelligence panels)
- Sector(s): Healthcare
- Tools/workflows: Use FRED/Text2AMR2FRED to extract a patient-case SKG; prompt an LLM with the SKG and medical ontologies (e.g., SNOMED-CT, ICD-10) to generate an extended SKG with tacit causal hypotheses; present graphs to clinical teams for validation and aggregation.
- Assumptions/dependencies: Licensed access to SNOMED-CT/ICD-10; EHR/FHIR integration; governance for human-in-the-loop validation; robust entity reconciliation (e.g., with Wikidata); data privacy and regulatory compliance (HIPAA/GDPR).
- Climate data interpretation workbench for scenario exploration
- Sector(s): Climate services, Public sector, Research
- Tools/workflows: Integrate CMIP6 datasets into a SKG; LAG generates tacit links (e.g., causal consequences, adaptation options) as extended triples; collaborative dashboards for scientists and stakeholders.
- Assumptions/dependencies: Access to CMIP6 and domain ontologies; clear provenance and uncertainty annotations; expert oversight to triage plausibility vs truth.
- Enterprise knowledge ingestion and enrichment (policy, SOPs, R&D reports)
- Sector(s): Software/IT, Manufacturing, Pharma, Energy
- Tools/workflows: Use FRED to extract SKGs from unstructured corpora; LLM augments with tacit relationships (prerequisites, implications, exceptions) within top-level ontologies (DOLCE-Zero + Ontology Design Patterns); store in a triple store with SPARQL endpoints.
- Assumptions/dependencies: Domain ontology availability/coverage; access rights and content licensing; SHACL validation to enforce boundaries.
- Logic-bounded enterprise chatbots (grounded assistants)
- Sector(s): Customer support, Internal IT helpdesk, Compliance
- Tools/workflows: Serve LLM responses constrained by an SKG (facts, definitions, process states); expose answers and their supporting graph subpaths; enforce boundaries via SHACL or rule checks before response.
- Assumptions/dependencies: High-quality SKG; latency budget for KG retrieval and validation; alignment of LLM prompts to respect logic constraints.
- Requirements engineering and traceability augmentation
- Sector(s): Software engineering, Safety-critical systems (e.g., automotive, avionics)
- Tools/workflows: Extract requirements SKG from documents; LAG adds tacit constraints, conflicts, and dependencies; link to test cases and design artifacts; query via SPARQL for impact analysis.
- Assumptions/dependencies: Domain ontologies (e.g., systems engineering ODPs); organizational adoption of knowledge graph workflows.
- Legal and policy analysis aides with interpretable rule graphs
- Sector(s): Government, Legal tech, Compliance
- Tools/workflows: Extract legal SKGs (e.g., obligations, exceptions) from statutes and guidance; LAG proposes tacit implications and stakeholder-specific conditions as candidate triples; support public consultations or impact assessments.
- Assumptions/dependencies: Legal ontologies (e.g., LKIF, custom ODPs); rigorous provenance; human review for doctrinal correctness; jurisdiction-specific coverage.
- Scientific literature curation and hypothesis mapping
- Sector(s): Academia, R&D-intensive industries
- Tools/workflows: Extract entities, relations, and frames from papers into SKGs; LAG suggests implicit causal links, methodologies, and gaps; reconcile to external SKGs (e.g., Wikidata) for entity normalization.
- Assumptions/dependencies: Quality of NLP extraction in domain-specific prose; curation resources; acceptance of plausibility-preserving annotations as “hypothesis” rather than “fact.”
- Ontology bootstrapping and refinement with metacognitive prompting
- Sector(s): Knowledge engineering across domains
- Tools/workflows: Use Ontogenia-like workflows (as cited) to generate and refine ontologies from corpora; apply metacognitive prompting to improve logical quality; integrate ODPs and DOLCE-Zero for conceptual coherence.
- Assumptions/dependencies: Expert review; SHACL/OWL reasoning for consistency; availability of seed patterns.
- Semi-automated schema/ontology alignment for data integration
- Sector(s): Data platforms, Enterprise IT, Public sector open data
- Tools/workflows: LAG proposes alignments between schemas using top-level constraints and patterns; human verifies mappings; publish as owl:equivalentClass/property assertions or SKOS mappings.
- Assumptions/dependencies: Ontology heterogeneity and ambiguity; performance on multilingual corpora; governance for change control.
- Multimodal incident and risk reports into KGs for operations
- Sector(s): Industrial IoT, Safety, Insurance
- Tools/workflows: Use multimodal SKG extraction (ItAF demo) from text/images; LAG adds tacit causes, mitigations, and preconditions; enable cross-incident reasoning and trend analysis.
- Assumptions/dependencies: Sensor/image/text access; privacy; domain-specific taxonomies for incidents and mitigations; validation to avoid spurious causality.
Long-Term Applications
These applications require further research and development on LAG’s semantics (plausibility- vs truth-preserving reasoning), scalable prompt strategies, real-time multimodal integration, safety evaluation, and/or regulatory acceptance.
- Regulatory-grade clinical decision support systems (CDSS) with hybrid logic
- Sector(s): Healthcare
- Tools/products: LAG-powered CDSS that produces auditable extended SKGs and aligns to clinical guidelines; integrates with EHRs and clinical workflows.
- Dependencies: Formal semantics and safety guarantees for tacit operators; extensive clinical validation; alignment with EU AI Act/FDA/EMA regulations.
- Operational platforms for climate adaptation planning with stakeholder co-creation
- Sector(s): Climate services, Urban planning, Insurance
- Tools/products: Shared LAG-backed knowledge platforms that ingest CMIP6, local observations, and policy inputs to co-create adaptation pathways as graphs; support “what-if” causal exploration.
- Dependencies: Continuous data pipelines; uncertainty-aware reasoning; inclusive governance for conflicting expert views; socio-economic data integration.
- Dynamic RCKGs for real-time decision-making from sensor and social signals
- Sector(s): Smart cities, Energy, Transportation, Public safety
- Tools/products: Event streams mapped to SKGs; LAG extends with plausible implications and actions; operators dispatch decisions based on graph queries.
- Dependencies: Robust streaming KG infrastructure; temporal and provenance modeling; false-positive management for tacit inferences; latency constraints.
- Hybrid plausibility–truth reasoning engines and standards
- Sector(s): Semantic Web, AI Safety, Standards bodies
- Tools/products: Reasoners that manage interactions between truth-preserving OWL rules and plausibility-preserving tacit operators; W3C-style best practices for RCKG outputs and validation.
- Dependencies: Theoretical advances in non-monotonic/contextual semantics; benchmark datasets and evaluation metrics.
- Automated conflict resolution and bias mitigation in collective intelligence
- Sector(s): Healthcare boards, Policy panels, Corporate strategy
- Tools/products: LAG modules that detect and reconcile inconsistencies between expert inputs; quantify confidence and disagreement; propose resolution paths with justifications.
- Dependencies: Trust calibration; explainability tooling; social choice mechanisms encoded in SKGs; extensive UX research.
- Compliance and risk reasoning in finance/insurance with tacit scenario modeling
- Sector(s): Finance, Insurance, RegTech
- Tools/products: LAG extends risk KGs with plausible contagion paths, policy interactions, and scenario narratives; supports stress testing and capital planning with graph explainability.
- Dependencies: Access to high-quality risk ontologies and data; model risk management; regulatory acceptance of plausibility-based outputs.
- Personalized, privacy-preserving knowledge assistants built on personal KGs
- Sector(s): Consumer software, Education
- Tools/products: On-device or federated LAG assistants that augment personal SKGs (notes, schedules, learning resources) with tacit prerequisites and task decompositions; explainable study plans or life-admin workflows.
- Dependencies: Privacy/security guarantees; lightweight on-device LLMs; user-consent and data portability; alignment to personal ontologies.
- Autonomous research graph builders and reviewers across disciplines
- Sector(s): Academia, Pharma, Materials science
- Tools/products: Agents that continuously ingest literature, update domain SKGs, propose tacit hypotheses and contradictions, and route to reviewers; support living reviews.
- Dependencies: Scalable curation pipelines; reputation/provenance systems; community norms for machine-proposed hypotheses; integration with publishing ecosystems.
- Knowledge-driven robotic planning with logic-constrained LLM reasoning
- Sector(s): Robotics, Industrial automation
- Tools/products: Planners that query SKGs and use LAG to infer tacit preconditions/effects within logical constraints; improve explainability and safety of task plans.
- Dependencies: Tight coupling with motion/control stacks; real-time guarantees; validated task ontologies; formal safety envelopes for plausibility-based inferences.
- Public-policy simulators with explainable causal chains
- Sector(s): Government, NGOs
- Tools/products: LAG-generated extended SKGs simulate plausible policy consequences across sectors (health, education, climate), exposing causal chains for deliberation.
- Dependencies: High-fidelity socio-economic data; rigorous calibration/validation; guardrails to prevent misuse/misinterpretation.
Each long-term application benefits from maturing the LAG stack: refined prompt engineering (e.g., metacognitive prompting), expanded tacit operators, better reconciliation with external SKGs (e.g., Wikidata, domain ontologies), and formal safety/provenance frameworks to translate plausibility into trustworthy, auditable outcomes.
Glossary
- Abstract Meaning Representation (AMR): A semantic formalism that represents the meaning of sentences as rooted, directed, labeled graphs independent of surface syntax. Example: "Abstract Meaning Representation~\cite{Banarescu2013} (AMR) graphs."
- amodal: Independent of any specific sensory modality; in KGs, denotes abstractions beyond sensory input. Example: "and then extracting an {\em amodal} SKG from natural language"
- Chain-of-Thought: A prompting technique that elicits step-by-step reasoning in LLMs. Example: "Evolutions of Chain-of-Thought, such as Metacognitive Prompting~\cite{Wang2023}, can be beneficial to LAG"
- collective intelligence: Group-level intelligence emerging from collaboration and interaction, enabling superior problem-solving. Example: "with a {\em collective intelligence} approach in two different domains, i.e., medical diagnostics and climate services."
- conceptual frames: Structured representations of situations or events that organize roles and relations in text understanding. Example: "assumes situations as occurrences of conceptual frames"
- Continuous Knowledge Graphs: Dynamic KGs that evolve incrementally over time with mechanisms for updates and adaptation. Example: "Continuous Knowledge Graphs have been introduced recently, e.g. in~\cite{Lairgi2024} as evolutionary dynamic graphs"
- Coupled Model Intercomparison Project (CMIP): A coordinated climate modeling effort enabling standardized comparisons across models. Example: "Coupled Model Intercomparison Project\footnote{\url{https://www.wcrp-climate.org/wgcm-cmip}.} (CMIP)"
- DOLCE-Zero: A streamlined top-level ontology derived from DOLCE, used to ground domain ontologies. Example: "leveraging DOLCE-Zero~\cite{Gangemi2002}\cite{paulheim2015serving} as a top-level ontology."
- FRED machine reader: An automated system that extracts OWL knowledge graphs from text using frame semantics. Example: "following the knowledge extraction paradigm introduced by the FRED machine reader~\cite{Gangemi2017}"
- Framester Semantics: A semantic framework integrating frame semantics with linked data for KG extraction and alignment. Example: "which extracts OWL SKGs based on Framester Semantics~\cite{Gangemi2016}"
- generative pre-trained transformers: Neural architectures trained on large corpora that can generate context-conditioned outputs. Example: "using (typically or mostly) continuous vector spaces such as generative pre-trained transformers."
- HACID: An EU project on hybrid human–AI collective intelligence for open-ended decision-making. Example: "The HACID acronym stands for Hybrid Human Artificial Collective Intelligence in Open-Ended Decision Making project."
- ICD-10: A standardized medical classification system for diseases and health conditions. Example: "For medical diagnostics we integrated data gathered from SNOMED-CT, ICD-10, and Wikidata."
- in-context learning: An LLM’s ability to adapt behavior based on prompt-provided examples or context without parameter updates. Example: "via in-context learning that requires adequate prompt engineering strategies."
- LLMs: Transformer-based models trained on massive text corpora that generate and interpret natural language. Example: "LLMs overcome those limitations making them suitable in open-ended tasks and unstructured environments."
- Logic Augmented Generation (LAG): An approach that integrates SKGs and LLMs to generate knowledge bounded by logical constraints. Example: "we envision Logic Augmented Generation (LAG) that combines the benefits of the two worlds."
- Metacognitive Prompting: A prompting strategy that explicitly guides models to reflect on their reasoning processes. Example: "Evolutions of Chain-of-Thought, such as Metacognitive Prompting~\cite{Wang2023}, can be beneficial to LAG"
- modular ontology network: A set of interlinked ontologies organized into coherent modules for scalability and reuse. Example: "formalised in a rich modular ontology network designed by reusing Ontology Design Patterns"
- neuro-symbolic approach: A method that combines neural models with symbolic logic and knowledge representations. Example: "RCKGs are an example of a neuro-symbolic approach that generates a much richer and deeper knowledge graph"
- non-monotonic: A property of reasoning where adding new information can invalidate previous inferences. Example: "Also, tacitness is typically non-monotonic and context-dependent."
- Ontology Design Patterns (ODPs): Reusable solutions to common ontology modeling problems. Example: "designed by reusing Ontology Design Patterns~\cite{Gangemi2009} (ODPs)"
- OWL2: A W3C-standard ontology language for rich knowledge representation and reasoning on the Semantic Web. Example: "a frame semantics-compatible logic like OWL2."
- plausibility-preserving: A semantic property where inferences aim to maintain plausibility rather than strict truth. Example: "RCKG semantics is {\em plausibility-preserving} rather than {\em truth-preserving}."
- Reactive Continuous Knowledge Graphs (RCKGs): LLM-driven KGs that generate and adapt knowledge reactively within continuous spaces. Example: "we use LLMs as potential {\em Reactive Continuous Knowledge Graphs} (RCKGs)."
- schema adaptation: The capability of a KG system to evolve its schema to accommodate new types and relations. Example: "featuring incremental knowledge updates, schema adaptation, conflict resolution, source tracking and verification, and temporal awareness."
- Semantic Knowledge Graphs (SKGs): Structured, machine-interpretable graphs encoding entities, relations, and axioms with formal semantics. Example: "Semantic Knowledge Graphs (SKG) face challenges with scalability, flexibility, contextual understanding, and handling unstructured or ambiguous information."
- social implicatures: Implied social meanings or inferences that arise in communication beyond explicit content. Example: "social implicatures can have different logical properties (group relativity, role sensitivity, status dependency, intensity, valence, gradability, source dependency, etc.)"
- SNOMED-CT: A comprehensive clinical healthcare terminology used for coding medical information. Example: "For medical diagnostics we integrated data gathered from SNOMED-CT, ICD-10, and Wikidata."
- supramodal: Pertaining to natural language’s integration across sensory modalities rather than any single modality. Example: "mapping signal to natural language, which is {\em supramodal}"
- tacit knowledge: Implicit, experiential knowledge that is hard to articulate but informs reasoning and decisions. Example: "RCKGs extract tacit knowledge by capturing insights, reasoning, or behaviours that resemble the informal, experiential, and often unspoken knowledge humans acquire through experience and practice"
- top-level ontology: A high-level, domain-independent ontology providing foundational categories and relations. Example: "as a top-level ontology."
- triples: The subject–predicate–object statements that constitute the basic facts in RDF-style knowledge graphs. Example: "a LLM can generate potentially infinite triples by means of in-context learning."
- truth-preserving: A property of logical systems where inference rules guarantee that truth is maintained from premises to conclusions. Example: "RCKG semantics is {\em plausibility-preserving} rather than {\em truth-preserving}."
- truth-theoretic semantics: A semantics grounded in formal truth conditions rather than plausibility or usage. Example: "mitigating the lack of truth-theoretic semantics in LLM's output."
- Wikidata: A collaboratively curated, structured knowledge base used for linking and reconciling entities. Example: "Wikidata is used as an external SKG to perform knowledge reconciliation."
- knowledge reconciliation: The process of aligning and integrating entities and facts across different knowledge sources. Example: "Wikidata is used as an external SKG to perform knowledge reconciliation."
Collections
Sign up for free to add this paper to one or more collections.