- The paper presents a novel method that integrates latent physical knowledge into video diffusion models using Masked Autoencoders for feature extraction.
- It employs quaternion networks to translate visual features into pseudo-language prompts, enabling effective capture of physical dynamics.
- Experimental results demonstrate improved adherence to physical laws, outperforming benchmarks in fluid dynamics and typhoon simulations.
Teaching Video Diffusion Model with Latent Physical Phenomenon Knowledge
Introduction
The study titled "Teaching Video Diffusion Model with Latent Physical Phenomenon Knowledge" addresses the limitations of current Video Diffusion Models (VDMs) in comprehending and generating videos that align with physical laws. VDMs have improved media content generation substantially, yet their ability to accurately capture complex temporal motion in line with physical principles remains an unsolved challenge. The authors propose a novel approach that equips video diffusion models with latent physical knowledge, thereby enhancing their ability to produce videos that adhere to physical laws.
Methodology
The core methodology involves leveraging Masked Autoencoders (MAE) to incorporate latent physical phenomena into VDMs. In brief, the process consists of the following steps:
- Latent Knowledge Extraction: The method uses MAE to encapsulate physical phenomena into embeddings by reconstructing masked segments of video data, as shown in Figure 1. This process helps the model comprehend and represent underlying physical laws within its framework.
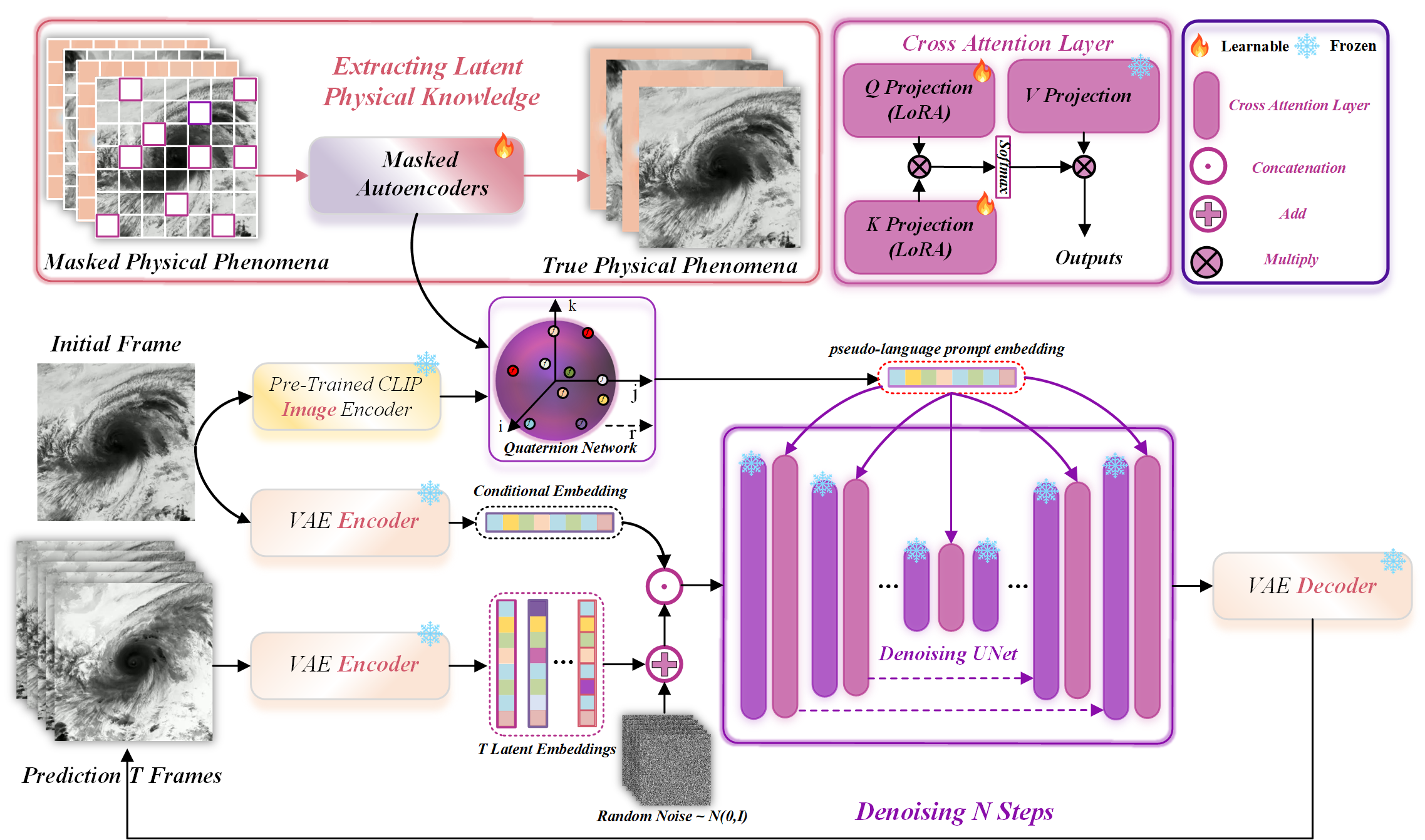
Figure 1: Overview of our proposed method. Aiming to teach stable video diffusion model with latent physical phenomenon knowledge.
- Quaternion Network Projection: Inspired by CLIP's vision-LLMs, the study employs quaternion networks to effectively translate visual features into pseudo-language prompts, enriched with the latent physical knowledge extracted earlier.
- Video Generation Pipeline: The pipeline integrates the pseudo-language prompts into the video diffusion framework. It fine-tunes the model using LoRA to enable parameter-efficient adaptation to diverse physical scenarios.
Experiments and Results
The experimental phase tested the pipeline on simulated fluid dynamics and real-world typhoon datasets. By comparing qualitative outcomes, the method consistently generated videos that better adhered to expected physical behaviors, as depicted in Figures 2 and 3.

Figure 2: Qualitative comparison between our method and other advanced methods in fluid simulation dataset.
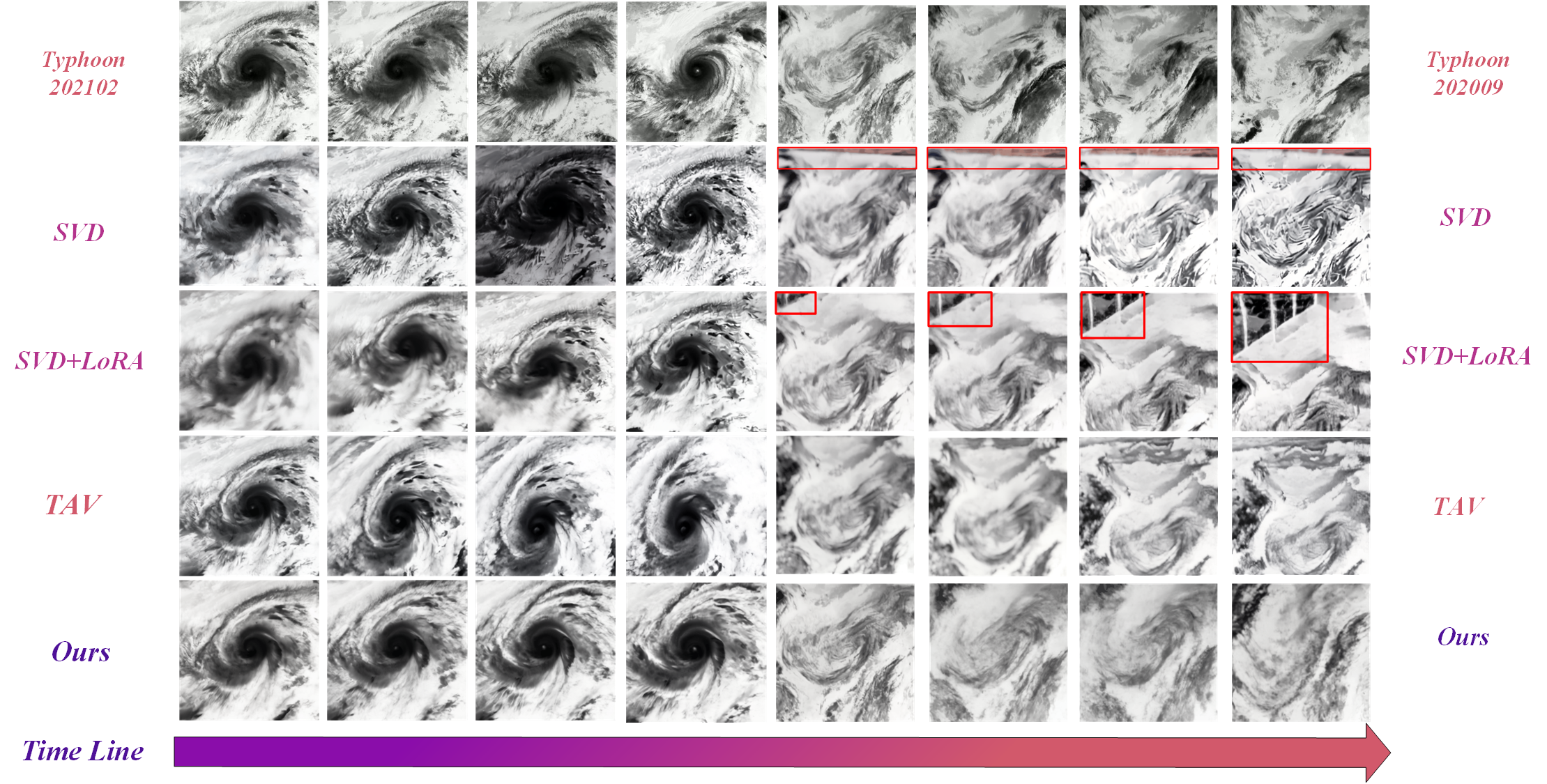
Figure 3: Qualitative comparisons in true typhoon dataset.
The authors quantified the performance using metrics such as RMSE, SSIM, and several physics-based measures like Stream Function Error and Vorticity Error. Their method consistently outperformed existing models in most metrics across various scenarios, highlighting its efficacy and fidelity in adhering to physical laws.
Discussion
The results of this study underscore an important advancement in video content generation, where understanding and adhering to physical principles elevates the realism and applicability of synthetic videos. The introduction of latent physical knowledge serves not only to improve the realism of the generated content but also to ensure consistency with natural laws, which is crucial for applications in simulation, education, and entertainment.
Moreover, this method reveals the potential of integrating advanced vision-LLMs, such as the CLIP-derived pseudo-language embedding, within the field of video generation. These models capture complex dynamic relationships present in physical phenomena, which are difficult to articulate and represent otherwise.
Conclusion
The proposed method successfully integrates latent physical knowledge into video diffusion models, substantially enhancing their ability to generate videos that align with essential physical principles. By adopting MAE for latent knowledge extraction and quaternion networks for spatial relationship modeling, the study opens new avenues for improvement in physically informed video synthesis. Observations from both numerical simulation and real-world datasets affirm this method’s superiority, suggesting its promising application in various domains where fidelity to physical laws is paramount. Future studies could expand upon this work by exploring additional physical phenomena or fine-tuning networks for specific applications.
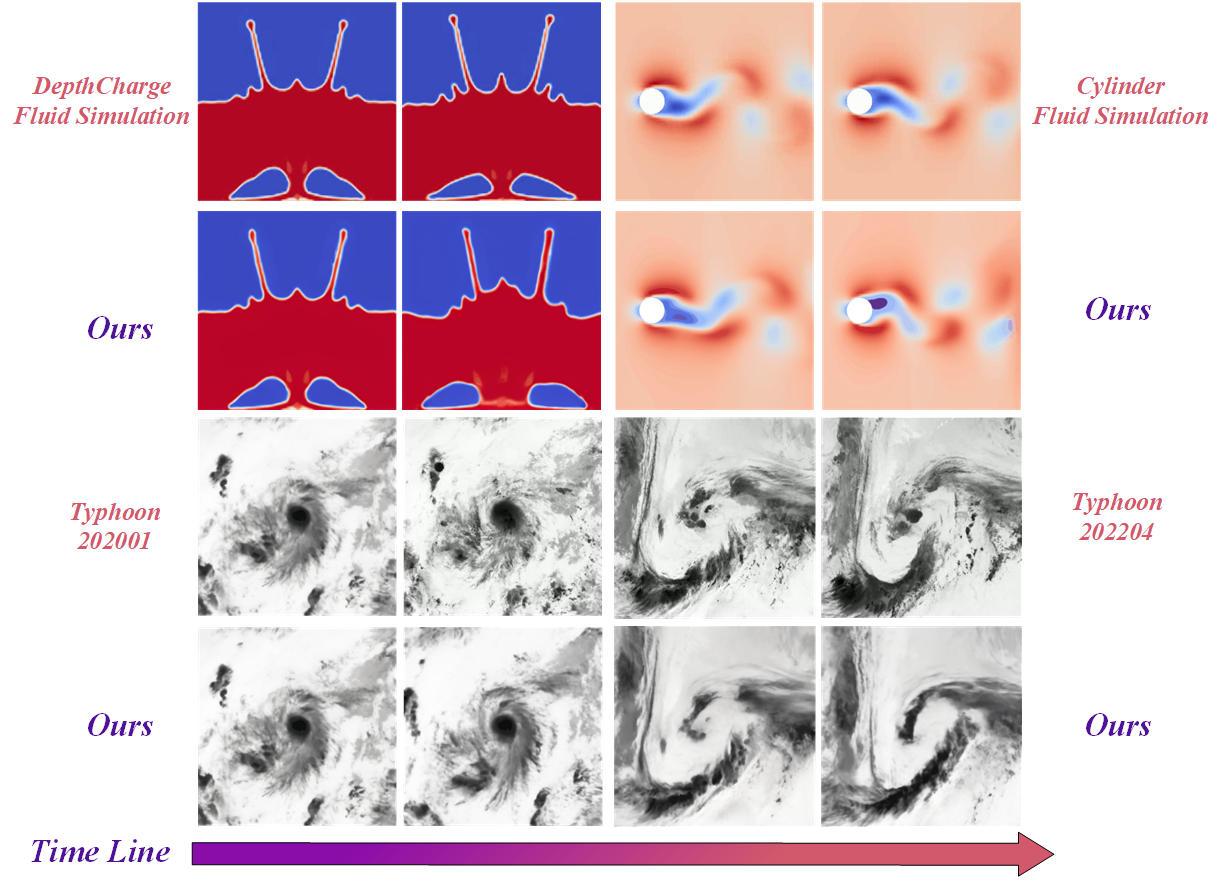
Figure 4: More qualitative results of our proposed method.
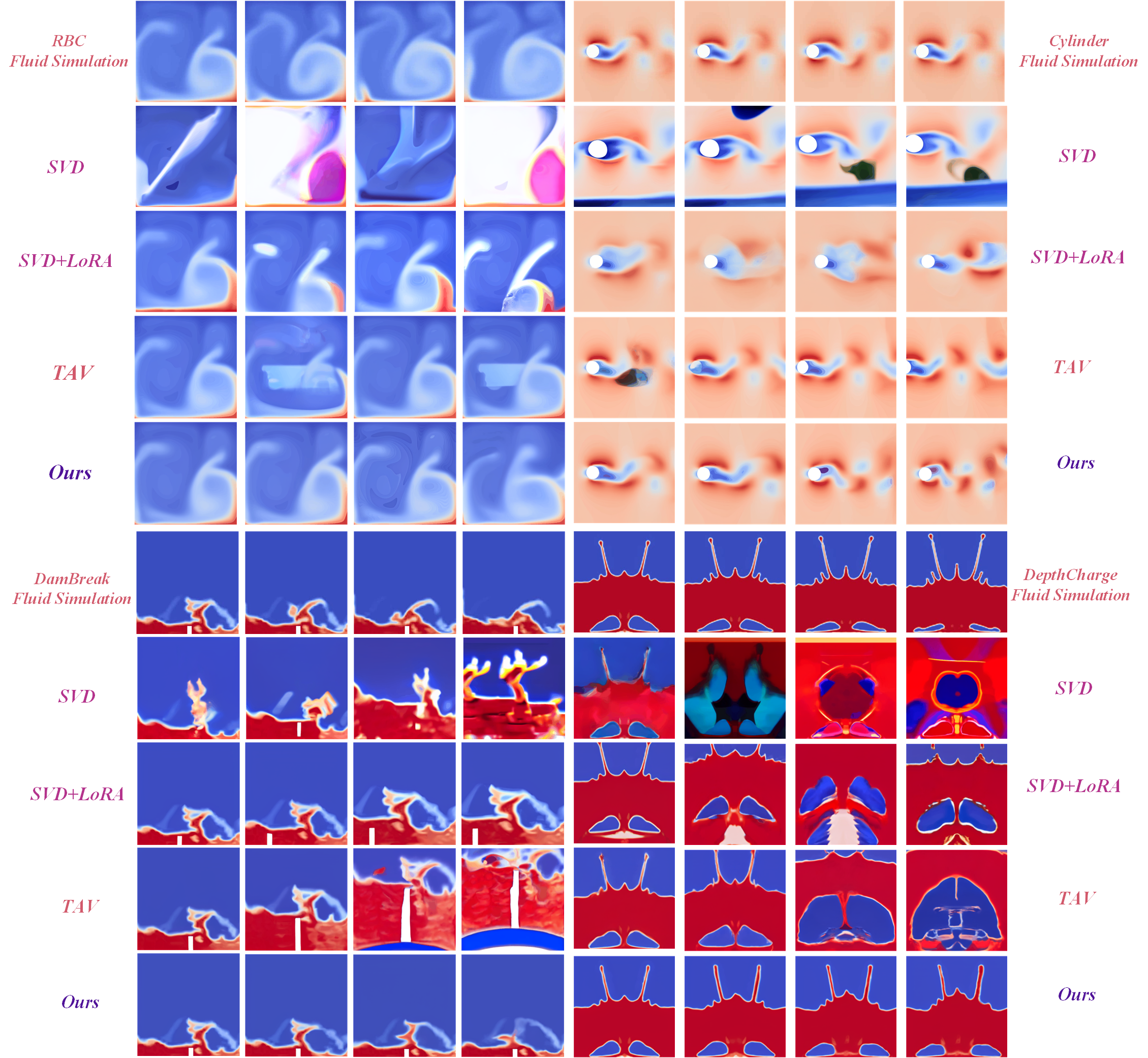
Figure 5: Qualitative comparisons in fluid simulation dataset.

