- The paper demonstrates that Global grouping with Pearson’s r leads to superior discriminative power, ranking consistency, and granularity sensitivity.
- It analyzes 12 correlation measures using six diverse NLG datasets and 32 evaluation metrics to reveal performance differences.
- Results advocate for refined measure selection tailored to specific evaluation contexts to enhance NLG system benchmarking.
Introduction
This paper examines the impact of correlation measures on the meta-evaluation of Natural Language Generation (NLG) metrics, emphasizing the need for a more nuanced understanding of these measures. The primary focus is on analyzing 12 common correlation measures across various grouping and coefficient paradigms, significantly impacting meta-evaluation outcomes. Utilizing real-world data from six NLG datasets processed through 32 evaluation metrics, the paper demonstrates how choosing different measures influences results. Furthermore, the global grouping strategy combined with Pearson correlation showcases superior meta-evaluation properties, including discriminative power, ranking consistency, and sensitivity to score granularity.
Datasets and Metrics
The analysis is based on datasets from diverse NLG tasks, including summarization, translation, story generation, dialogue, and data-to-text. To ensure robustness, the study involves 30 subsets from these datasets. It also integrates both traditional metrics like BLEU, ROUGE, and newer LLM-derived metrics from models like GPT-4 and GPT-3.5, capturing a wide range of evaluation perspectives.
Correlation Measures
The study categorizes correlation measures into four grouping methods: Global, Input, Item, and System level, paired with three correlation coefficients: Pearson's r, Spearman's ρ, and Kendall's τ. These combinations result in 12 distinct correlation measures. The effectiveness of these measures is further scrutinized via three core aspects: discriminative power, ranking consistency, and score granularity sensitivity.
Discriminative Power
Discriminative power refers to a measure's ability to distinguish between automatic evaluation metrics. It is quantified via p-value analysis of metric pair differentiation, with lower p-values signifying stronger discriminative capacities.
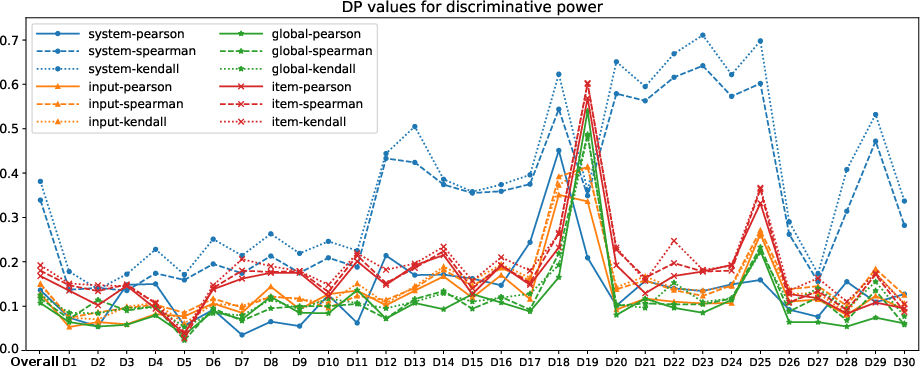
Figure 1: DP values of different correlation measures on all meta-evaluation datasets using the permutation test, the lower the better.
The analysis reveals a hierarchical performance with Global grouping paired with Pearson's r leading, followed by input and item levels. System-level groupings, especially those using Kendall’s τ, lag notably in count-based discriminatory tasks.
Ranking Consistency
Ranking consistency assesses the robustness of metric rankings derived from the same correlation measure across randomized data partitions.
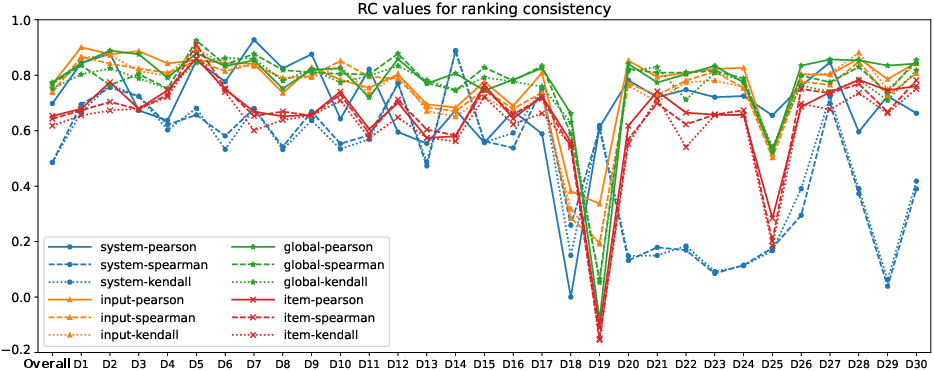
Figure 2: RC values of different correlation measures on all meta-evaluation datasets, the higher the better.
Global-level strategies again outperform peers, with Pearson's r maintaining superior ranking integrity. System-level and Kendall's τ combinations show decreased consistency, impacting overall reliability in metric ordering.
Sensitivity to Score Granularity
This aspect examines how measures handle variations in the discretization of human and metric scores, crucial as LLMs use score discretization resembling human judgment. Changes in score granularity (Gm) dynamically affect correlations between evaluator scores and human benchmarks.
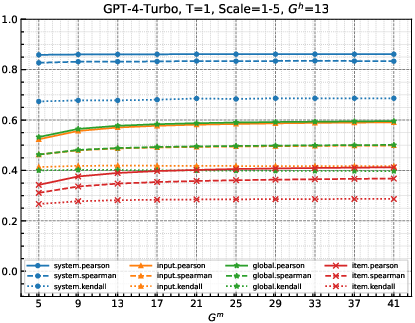
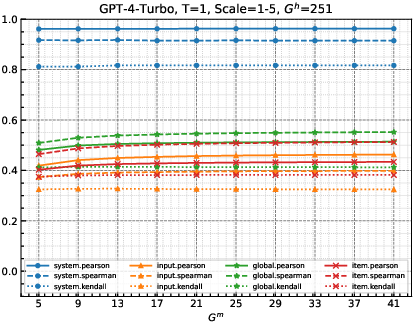
Figure 3: As Gm changes, correlations between the GPT-4-Turbo evaluator and humans on SummEval and WMT23, with fixed evaluation scale of 1-5.
The study finds system-level grouping and measures using Kendall's τ exhibit the least sensitivity to score variability, potentially overlooking nuanced evaluator capabilities when score granularity is comparable to human scoring.
Implications and Conclusion
The findings stress the divergence in performances across correlation measures, with significant practical implications for the evaluation procedure of NLG systems. Pearson correlation coefficients combined with global grouping emerge as leading strategies, offering enhanced evaluative reliability across various performance aspects.
The study advocates for refined correlation measure selection tailored to specific evaluative contexts, urging the community to align on clear methodologies for transparent and consistent meta-evaluation moving forward, particularly as LLMs increasingly influence the landscape of automated evaluation metrics. The insights also highlight opportunities for future research to further refine correlation measure applications and benefit from emerging LLM capabilities.