- The paper introduces G-Eval, which uses GPT-4 and chain-of-thought reasoning to provide a more human-aligned evaluation of NLG outputs.
- The methodology involves a three-stage pipeline with prompt-based evaluation, CoT generation, and a probability-weighted scoring function.
- The experimental results show superior performance on benchmarks like SummEval, Topical-Chat, and QAGS, while noting potential bias towards LLM-generated outputs.
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Introduction
Evaluating the quality of texts generated by NLG systems is a complex challenge, particularly due to the limitations of conventional metrics such as BLEU and ROUGE, which often show a low correlation with human judgments. This is increasingly apparent in tasks requiring creativity and diversity. Recent approaches propose using LLMs as reference-free metrics for evaluating NLG outputs. However, these approaches frequently exhibit lower correspondence with human assessments compared to medium-sized neural models. Here, G-Eval is introduced as a novel framework employing GPT-4, leveraging CoT reasoning to enhance the evaluation of NLG outputs across diverse tasks.
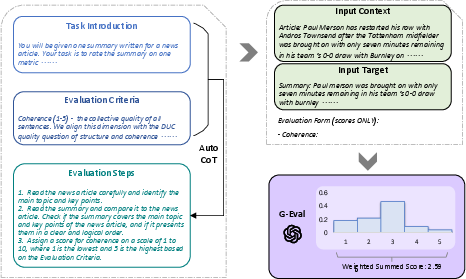
Figure 1: The overall framework of G-Eval. We first input Task Introduction and Evaluation Criteria to the LLM, and ask it to generate a CoT of detailed Evaluation Steps. Then we use the prompt along with the generated CoT to evaluate the NLG outputs in a form-filling paradigm. Finally, we use the probability-weighted summation of the output scores as the final score.
Methodology
G-Eval utilizes a three-stage pipeline: a prompt for NLG evaluation, generation of a CoT, and a scoring function.
Prompt-based Evaluator
The initial phase involves crafting a detailed prompt that articulates the evaluation task and criteria, thereby setting the evaluation's foundation. In this stage, task-specific criteria such as coherence or conciseness are included in the prompt, providing necessary context for subsequent processing.
Chain-of-Thought (CoT) Generation
The CoT is generated iteratively by the LLM, furnishing intermediate evaluative steps. For example, evaluating coherence in text summarization may involve checking the logical flow between summary sentences. This structured reasoning enables the model to assess NLG outputs more effectively.
Scoring Function
The scoring employs a probability-weighted summation of discrete score outcomes generated by the LLM. This approach addresses two key issues: the predominance of a single score value and the limitations of integer-only outputs. By utilizing token probabilities for normalizing scores, G-Eval provides a more nuanced and continuous evaluation metric.
Experimental Evaluation
The framework's efficacy was validated across multiple benchmarks: SummEval, Topical-Chat, and QAGS, demonstrating superior performance in correlating model assessments with human judgments. SummEval results highlighted the improved correlation of G-Eval-4 with human evaluations, surpassing previous state-of-the-art metrics, including GPTScore and BARTScore. In particular, the method's adeptness in handling creativity-driven and consistency-focused tasks underscores its robustness.
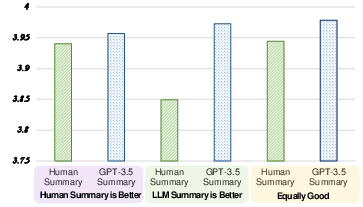
Figure 2: Averaged G-Eval-4's scores for human-written summaries and GPT-3.5 summaries, divided by human judges' preference.
Analysis and Implications
A notable finding from this study is the inherent bias of G-Eval towards LLM-generated outputs, potentially due to shared criteria during text generation and evaluation. Although this introduces a risk of self-reinforcement if the evaluator's outputs serve as a feedback mechanism for LLM training, it also emphasizes the need for transparency and oversight in using LLM-based evaluators.
Furthermore, the effect of CoT significantly boosts model performance, particularly in enhancing coherence metrics. Probability normalization, while affecting Kendall-Tau correlation, offers higher Spearman correlation, indicating a refined ranking ability of generated text quality.
Conclusion
G-Eval represents an advancement in the landscape of NLG evaluation, leveraging the abilities of LLMs, CoT reasoning, and a probability-weighted scoring mechanism. This approach not only surpasses traditional and recent evaluation metrics but also presents a more human-aligned assessment framework. Future work should focus on exploring mitigative strategies for LLM-preferred biases and expanding the framework’s adaptability across emerging NLG tasks.