- The paper provides a comprehensive review of both context-free and context-dependent evaluation metrics for NLG systems.
- It analyzes traditional metrics such as BLEU, ROUGE, and METEOR alongside embedding-based methods like BERTScore.
- The study highlights future directions including task-specific metrics and robust, interpretable evaluation frameworks for improved NLG assessment.
Evaluation Metrics for Natural Language Generation (NLG) Systems
The paper "A Survey of Evaluation Metrics Used for NLG Systems" provides a comprehensive review of the metrics employed to evaluate NLG systems. As NLG encompasses tasks such as machine translation, summarization, question answering, and more, the evaluation of generated text's quality, fluency, and accuracy becomes critical. The paper categorizes existing evaluation metrics into context-free and context-dependent metrics and evaluates them based on various dimensions.
Context-Free Evaluation Metrics
Context-free metrics, such as BLEU, ROUGE, and METEOR, focus on the output text in isolation, comparing it to reference outputs.
BLEU and Its Variants
BLEU evaluates text by comparing overlapping n-grams in the hypothesis with those in the reference. It is widely used across NLG tasks due to its simplicity and task-agnostic nature. Despite its popularity, BLEU has been criticized for poor correlation with human judgment in diverse text contexts, especially in dialogue systems where linguistic diversity and context relevance are crucial.
ROUGE and METEOR
ROUGE focuses on recall, making it suitable for summarization tasks where capturing all relevant information is important. METEOR extends BLEU by incorporating synonyms and stemming, improving its correlation with human evaluations. However, METEOR requires language-specific resources, making it less versatile.
Embedding-Based Approaches
The paper also explores embedding-based metrics like BERTScore, which leverage contextual embeddings to evaluate semantic similarity beyond word matches. These metrics demonstrate improved correlation with human judgments, particularly in tasks with semantically rich content, such as summarization and machine translation.
Context-Dependent Evaluation Metrics
These metrics assess the generated text in the context of the input data, making them more suitable for tasks where understanding the source context is critical.
PARENT and LEIC
PARENT evaluates data-to-text generation tasks by considering content alignment with structured data sources. LEIC, designed for image captioning, integrates visual features to better assess the relevance of generated captions to the input images.
Dialogue-Specific Metrics
In dialogue generation, metrics such as RUBER and MaUde account for both reference-based and unreferenced assessments to judge response quality. These metrics aim to capture aspects like coherence and engagement, which are not addressed by traditional n-gram-based metrics.
Challenges and Criticisms
Despite advancements, evaluation metrics face challenges, such as measuring aspects like creativity and user engagement, which are difficult to quantify but critical for applications like storytelling and dialogue systems. Criticisms include low correlation with human evaluation (particularly at the sentence level) and the incapacity of many metrics to handle nuanced language understanding and generation (Figure 1).
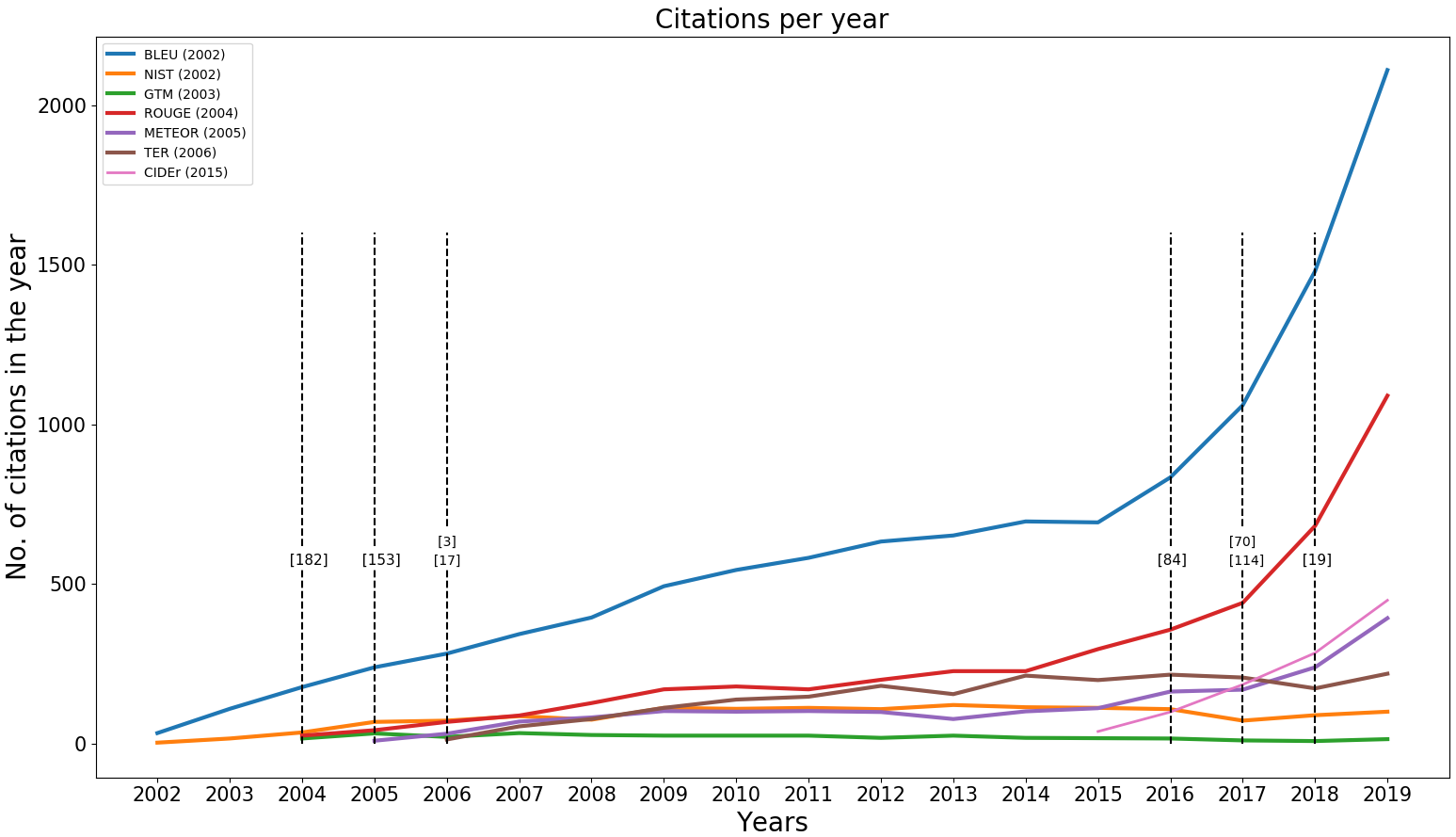
Figure 1: Number of citations per year on a few popular metrics. Dashed lines represent some of the major criticisms on these metrics at the corresponding year of publication.
Future Directions
The paper outlines future directions in metric development, emphasizing the need for:
- Task-Specific Metrics: Developing metrics tailored for specific NLG tasks to better capture relevant evaluation dimensions.
- Robustness and Interpretability: Creating transparent metrics that provide interpretable outputs, revealing which linguistic aspects influence the scores.
- Common Benchmarking Platforms: Establishing shared platforms for evaluating metrics across standard datasets to improve consistency and comparability.
Conclusion
The paper highlights that while existing metrics provide a baseline for NLG evaluation, further research is essential to develop metrics that align more closely with human evaluations across diverse tasks. Future work should concentrate on building versatile, interpretable, and contextually aware metrics to truly assess NLG systems' quality and impact.