- The paper demonstrates that cellular automata implementations in C and C++ show minimal performance differences across compilers and data structures.
- The study evaluates array management strategies, noting up to three orders of magnitude speed improvements with Apple clang for simple update functions.
- The research advocates for modern C++ practices, such as pre-allocated vectors and object-oriented designs, to ensure code safety without compromising efficiency.
Programming of Cellular Automata in C and C++
Introduction
The paper explores the execution efficiency and programming conventions for implementing cellular automata (CA) in C and C++, focusing on different array management techniques, data structures, and compilers. This analysis is critical in the context of using simple, elementary CA as they demonstrate that even simple programs can yield complex patterns, an insight well established in computational theory by Wolfram [Wolfram.Nature.1984, Wolfram.NKS.2002]. Given the increasing tendency towards complex and feature-rich software, this research serves as a valuable assessment of fundamental programming efficiency against modern development practices.
Methodology
The study implements CA in multiple configurations using both C and C++ paradigms, evaluating various combinations of primitive data types, structures, and containers such as arrays and vectors. The implementations also cover a range of looping constructs, including index-based and pointer-based traversals in C and iterator-based approaches in C++. Each implementation was executed with two compilers: GNU gcc and Apple clang, under the optimization level -O2.
The elementary CA operates on a one-dimensional grid with a simple update rule (Rule 250 in Wolfram's lexicon), where cells are either "on" or "off". The paper's method effectively abstracts CA into simple update functions, which are executed over a configurable grid size to assess performance over differing operational scales.
Results
The analysis reveals minimal variances in performance across the different implementations and conditions. The choice between C and C++ does not significantly affect execution times. Furthermore, data structures (arrays versus vectors) and the usage of structs or objects manifest negligible deviations in performance metrics.
However, a noteworthy observation is that the Apple clang compiler exhibits a superior ability to optimize specific CA scenarios, particularly those with simpler update functions, achieving up to three orders of magnitude improvement in execution speed for certain configurations.
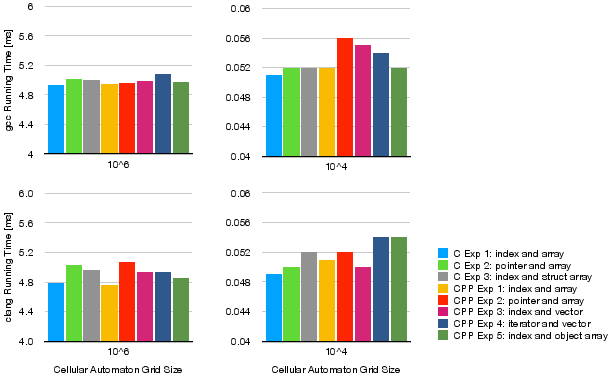
Figure 1: Running times in milliseconds for different cellular automata programs in C and C++. The top row shows the results for the GNU gcc compiler and the bottom row for the Apple clang compiler. The left column shows the results for a cellular automaton grid size of 106 and the right column of grid size 104.
Discussion
This study reinforces the prevailing recommendation to utilize vectors in C++ programming due to their inherent safety, dynamism, and comparable efficiency to arrays, provided memory is allocated prior to operations. The performance equivalence established between vector-based methods and traditional array approaches validates the use of vectors for CA implementations without compromising speed.
The findings also suggest that multi-state CAs, which utilize structs and objects, achieve efficient performance, advocating for object-oriented approaches in CA programming.
The paper acknowledges limitations related to its scope, suggesting potential for future investigations into compiler optimizations and parallel implementations, such as leveraging Apple's Metal frameworks or exploring shader programming for CA computations.
Conclusion
The research furnishes compelling evidence for adopting modern C++ practices, specifically using vectors with index-based access when implementing CAs, ensuring code safety and performance. The negligible impact on running times when utilizing structures or classes for multi-state CA models further supports structured and object-oriented designs. Future research should explore compiler enhancements and heterogeneous computing frameworks to fully exploit CA capabilities in practical applications.

