SG-Nav: Online 3D Scene Graph Prompting for LLM-based Zero-shot Object Navigation
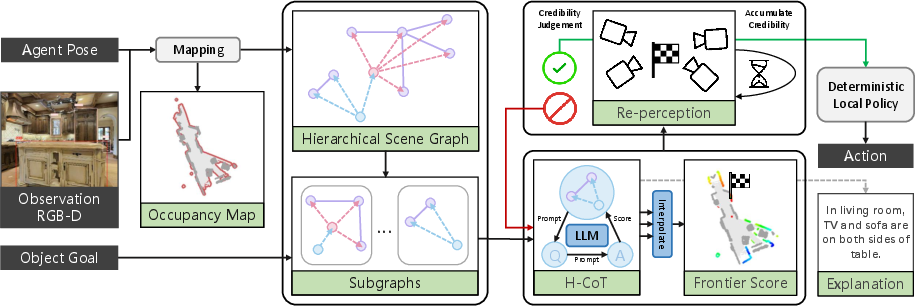
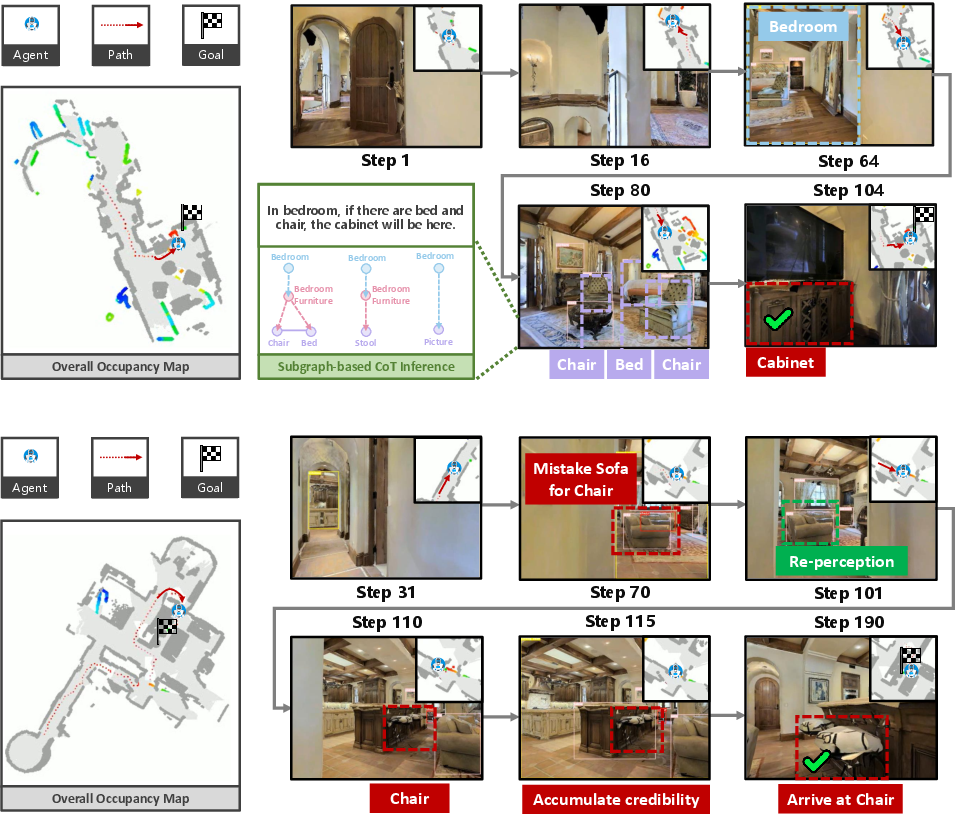
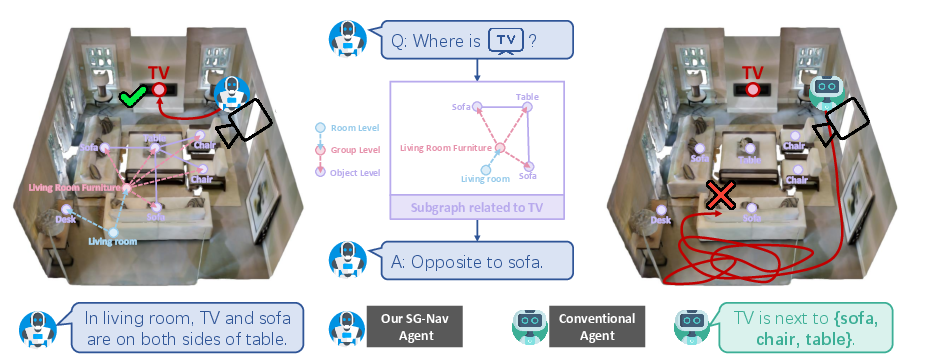
Abstract: In this paper, we propose a new framework for zero-shot object navigation. Existing zero-shot object navigation methods prompt LLM with the text of spatially closed objects, which lacks enough scene context for in-depth reasoning. To better preserve the information of environment and fully exploit the reasoning ability of LLM, we propose to represent the observed scene with 3D scene graph. The scene graph encodes the relationships between objects, groups and rooms with a LLM-friendly structure, for which we design a hierarchical chain-of-thought prompt to help LLM reason the goal location according to scene context by traversing the nodes and edges. Moreover, benefit from the scene graph representation, we further design a re-perception mechanism to empower the object navigation framework with the ability to correct perception error. We conduct extensive experiments on MP3D, HM3D and RoboTHOR environments, where SG-Nav surpasses previous state-of-the-art zero-shot methods by more than 10% SR on all benchmarks, while the decision process is explainable. To the best of our knowledge, SG-Nav is the first zero-shot method that achieves even higher performance than supervised object navigation methods on the challenging MP3D benchmark.
- Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022.
- Objectnav revisited: On evaluation of embodied agents navigating to objects. arXiv preprint arXiv:2006.13171, 2020.
- A persistent spatial semantic representation for high-level natural language instruction execution. In CoRL, pages 706–717. PMLR, 2022.
- Matterport3d: Learning from rgb-d data in indoor environments. 3DV, 2017.
- Object goal navigation using goal-oriented semantic exploration. NeurIPS, 33:4247–4258, 2020.
- Open-vocabulary queryable scene representations for real world planning. In ICRA, pages 11509–11522. IEEE, 2023.
- Integrating egocentric localization for more realistic point-goal navigation agents. CoRL, 2020.
- Robothor: An open simulation-to-real embodied ai platform. In CVPR, June 2020.
- Procthor: Large-scale embodied ai using procedural generation, 2022.
- Cows on pasture: Baselines and benchmarks for language-driven zero-shot object navigation. In CVPR, pages 23171–23181, 2023.
- Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning. arXiv preprint arXiv:2309.16650, 2023.
- Towards learning a generic agent for vision-and-language navigation via pre-training. In CVPR, pages 13137–13146, 2020.
- Instruct2act: Mapping multi-modality instructions to robotic actions with large language model. arXiv preprint arXiv:2305.11176, 2023.
- Voxposer: Composable 3d value maps for robotic manipulation with language models. arXiv preprint arXiv:2307.05973, 2023.
- Inner monologue: Embodied reasoning through planning with language models. arXiv preprint arXiv:2207.05608, 2022.
- Simple but effective: Clip embeddings for embodied ai. In CVPR, pages 14829–14838, 2022.
- Segment anything. In ICCV, pages 4015–4026, 2023.
- Openfmnav: Towards open-set zero-shot object navigation via vision-language foundation models. arXiv preprint arXiv:2402.10670, 2024.
- Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In ICML, pages 12888–12900. PMLR, 2022.
- Grounded language-image pre-training. In CVPR, pages 10965–10975, 2022.
- Code as policies: Language model programs for embodied control. In ICRA, pages 9493–9500. IEEE, 2023.
- Visual instruction tuning. NeurIPS, 36, 2023.
- Visual instruction tuning, 2023.
- Zson: Zero-shot object-goal navigation using multimodal goal embeddings. NeurIPS, 35:32340–32352, 2022.
- Thda: Treasure hunt data augmentation for semantic navigation. In ICCV, pages 15374–15383, 2021.
- Film: Following instructions in language with modular methods. arXiv preprint arXiv:2110.07342, 2021.
- Simple open-vocabulary object detection with vision transformers. arxiv 2022. arXiv preprint arXiv:2205.06230, 2, 2022.
- Visual representations for semantic target driven navigation. In ICRA, pages 8846–8852. IEEE, 2019.
- Learning transferable visual models from natural language supervision. In ICML, pages 8748–8763. PMLR, 2021.
- Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai, 2021.
- Poni: Potential functions for objectgoal navigation with interaction-free learning. In CVPR, pages 18890–18900, 2022.
- Sayplan: Grounding large language models using 3d scene graphs for scalable task planning. In CoRL, 2023.
- James A Sethian. Fast marching methods. SIAM review, 41(2):199–235, 1999.
- Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action. In CoRL, pages 492–504. PMLR, 2023.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020.
- Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames. arXiv preprint arXiv:1911.00357, 2019.
- Embodied task planning with large language models. arXiv preprint arXiv:2307.01848, 2023.
- Embodied instruction following in unknown environments. arXiv preprint arXiv:2406.11818, 2024.
- Embodiedsam: Online segment any 3d thing in real time. arXiv preprint arXiv:2408.11811, 2024.
- Memory-based adapters for online 3d scene perception. In CVPR, pages 21604–21613, 2024.
- Visual semantic navigation using scene priors. arXiv preprint arXiv:1810.06543, 2018.
- Auxiliary tasks and exploration enable objectgoal navigation. In ICCV, pages 16117–16126, 2021.
- Vlfm: Vision-language frontier maps for zero-shot semantic navigation. In ICRA, 2024.
- L3mvn: Leveraging large language models for visual target navigation. In IROS, pages 3554–3560. IEEE, 2023.
- Language to rewards for robotic skill synthesis. arXiv preprint arXiv:2306.08647, 2023.
- 3d-aware object goal navigation via simultaneous exploration and identification. In CVPR, pages 6672–6682, 2023.
- Fusion-aware point convolution for online semantic 3d scene segmentation. In CVPR, pages 4534–4543, 2020.
- Hierarchical object-to-zone graph for object navigation. In ICCV, pages 15130–15140, October 2021.
- Navgpt: Explicit reasoning in vision-and-language navigation with large language models. In AAAI, volume 38, pages 7641–7649, 2024.
- Esc: Exploration with soft commonsense constraints for zero-shot object navigation. In ICML, pages 42829–42842. PMLR, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.