- The paper introduces a novel framework that integrates hierarchical scene graphs with LLM-based spatial reasoning to address semantic exploration in robotics.
- The paper employs advanced detection (YOLOE, YOSO) and TSDF mapping along with mutual information maximization for planning semantically valuable exploration moves.
- The paper demonstrates superior semantic grounding and sample efficiency in HM3D simulations compared to traditional occupancy-based methods.
Active Semantic Perception: A Scene Graph and LLM Approach to Embodied Semantic Exploration
Introduction and Motivation
The paper introduces an architecture for active semantic perception that integrates hierarchical scene graph representations with LLM-based spatial reasoning to address semantic exploration in robotics. The core proposition is that, while geometric mapping has seen substantial progress, it lacks the semantic richness required for efficient goal-driven exploration in complex indoor environments. The approach targets the key gap between geometric exploration—focused on coverage and occupancy—and semantically meaningful exploration, where the ability to make inferences about unseen regions and object relationships is critical for tasks such as search and information gathering.
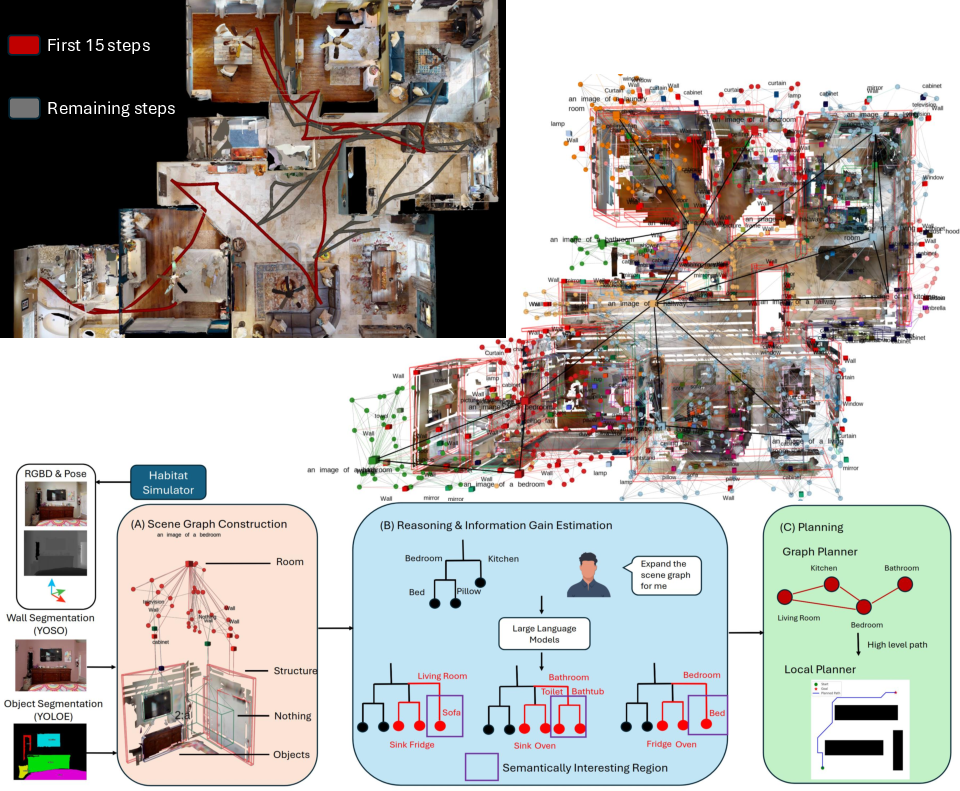
Figure 1: Visualization of a robot's exploration trajectory that prioritizes semantically salient regions (red and grey), resulting in rapid semantic scene coverage and rich hierarchical scene graph construction.
Hierarchical Scene Graph Construction
The mapping module constructs a compact, hierarchical, multi-layer scene graph, extending the Clio [maggio2024clio] framework but replacing its segmentation and object tracking pipeline with high-throughput, real-time detectors (YOLOE for objects, YOSO for panoptic structure segmentation). The scene graph employs a four-node taxonomy:
- Object nodes: Each node corresponds to a detected instance, tracked and merged using 3D voxel association with greedy IoU matching. Real-time bounding box fitting (via marching cubes) ensures accurate spatial localization.
- Room nodes: Constructed via truncated signed distance field (TSDF) integration, cluster-based room identification (using CLIP-based image features), and agglomerative clustering. Room labels are assigned by proximity in CLIP-embedding space to canonical room definitions.
- Nothing nodes: Represent explicitly confirmed free-space (negative space) by extracting the largest cuboid in the free TSDF region, an information-theoretic addition for improved scene inference.
- Structure nodes: Planar features (walls, doors, windows, blinds) segmented and reconstructed via RANSAC on YOSO segmentations, ensuring scene integrity and enforcing geometric constraints.
This representation, by explicitly incorporating negative space and fine-grained structure, avoids many ambiguities and hallucinations endemic to prior work relying on occupancy grids or unstructured feature maps.
Semantic Reasoning and LLM-Driven Scene Completion
The reasoning module samples plausible completions of unobserved regions—i.e., inferring the likely existence and layout of unseen rooms or objects—by querying LLMs (Gemini-2.5-Pro) with the current scene graph in both structured (YAML) and visual (cross-sectional image) forms. Scene graph completions are generated in two stages:
- Expansion prompt: LLM generates hypothetical extensions based on semantic priors (e.g., “door from a living room likely leads to a kitchen or bedroom”).
- Refinement prompt: The initial graph is semantically filtered, ensuring consistency and realism as far as LLM priors allow.
Sampling is conducted in an ensemble manner, both for capturing model uncertainty and supporting information-theoretic planning.
To quantify the value of potential actions, the authors formalize viewpoint selection via mutual information maximization between future observations and the current scene graph:
I(Yk+1;Gk∣xk+1)=H(Yk+1∣xk+1)−H(Yk+1∣xk+1,Gk)
This information gain metric is computed hierarchically (object- and room-level) and fused for multi-resolution planning.
Hierarchical Planning and Execution
The planner uses a two-level approach: high-level waypoints are determined by semantic information gain on the scene graph, and executed via standard A* over occupancy grids (TSDF maps) for local collision-free motion. Notably, the semantic exploration policy enables longer, semantically informed steps (i.e., skipping trivially guessable local frontiers) resulting in more efficient coverage of high-value semantic targets.
Empirical Evaluation and Ablation
Simulation experiments in complex HM3D indoor environments within Habitat demonstrate that the proposed semantic exploration pipeline outperform both frontier-based and semantic occupancy-based methods (SSMI) under both path-length and time constraints. Key metrics:
- Semantic grounding: The method achieves higher average F1 scores (object detection) and lower graph edit distances (GED, measuring scene graph correctness) over a range of exploration budgets.
- Sample efficiency: The system reaches high semantic accuracy with fewer steps due to longer, semantically-targeted moves.
- Predictive power: In unobserved “room-finding” tasks, the LLM-augmented planner predicts unseen rooms with high spatial fidelity and lower navigation cost than frontier-based methods.
Ablation studies on scene graph structure demonstrate the necessity of negative space and structure nodes for reducing hallucinations and guiding plausible completions—without which LLMs frequently posit implausible or spatially inconsistent hallucinations.
Limitations
The method demonstrates several notable limitations:
- LLM hallucinations: Despite structured prompts and voting-based filtering, LLM outputs can violate geometric or contextual constraints (e.g., bathrooms inside bedrooms), requiring manual rejection.
- Computation time: Integrated LLM querying and completion sampling (with multiple refinement rounds) is computationally non-trivial—scene completion and reasoning take on the order of minutes per planning cycle, albeit amortized by longer semantic moves.
- Inadequate prior modeling: Off-the-shelf LLMs are not explicitly trained for scene composition, leading to systematic biases and limited diversity in hypothetical completions, particularly in large-scale or non-standard topologies.
Theoretical and Practical Implications
This work provides a concrete demonstration that large LLMs, when tightly integrated with structured hierarchical representations and information-theoretic planning, can advance semantic exploration in embodied agents beyond what is possible with geometric or shallow semantic models. Practically, this enables the development of search and navigation agents capable of goal-driven exploration in occluded or unknown spaces, with applications in search-and-rescue, facility logistics, and other embodied AI domains.
From a theoretical perspective, the results reinforce the potential of scene graph abstraction as a unifying layer for bridging geometric perception and symbolic reasoning in robotics. The information gain-based planner illustrates how generative semantic models can be harnessed for predictive exploration, a core aspect of “intelligent” search.
Future Directions
Directions for further research include:
- Dedicated scene completion models: Training or fine-tuning LLMs on structured scene graph datasets to reduce hallucination, improve compositional diversity, and bring predictive distributions closer to realistic scene statistics.
- Automated plausibility rejection: Integrating geometric reasoning modules for online filtering of implausible completions.
- Real-world deployment: Addressing sim-to-real gaps, uncertainty calibration, and computational acceleration of the reasoning cycle.
- Extensions to dynamic and object-goal tasks: Adapting the planner for dynamic environments, task-driven search (e.g., people, rare objects), and interaction with other agents.
Conclusion
Active Semantic Perception presents an effective framework for integrating hierarchical scene graphs and LLM-based spatial reasoning to achieve semantically efficient exploration in robotics. The architecture demonstrates quantitatively superior semantic recovery and efficient prediction of unobserved regions in large, complex indoor scenes. The method achieves this via structured scene graph construction, principled scene completion and uncertainty quantification, and information-theoretic planning for viewpoint selection. Continued development in this direction, including the incorporation of domain-adapted LLMs and the automation of semantic consistency checks, promises to further bridge the gap between geometric and truly semantic perception for embodied agents.

