- The paper presents a comprehensive review of LLM methods for Text-to-SQL generation, outlining approaches such as prompt engineering, fine-tuning, and LLM agents.
- It details the evolution from rule-based methods to advanced deep learning techniques, showcasing improvements in query accuracy through strategies like zero-shot and few-shot prompting.
- The survey evaluates key metrics and datasets including Spider and WikiSQL, highlighting challenges in cross-domain generalization and future research directions.
LLM Enhanced Text-to-SQL Generation: A Survey
This paper provides a comprehensive review of methods enhancing Text-to-SQL translation using LLMs. It structures its analysis around significant technological advances stemming from LLMs used for generating SQL queries from natural language inputs. The survey elaborates on four major categories based on training strategies: prompt engineering, fine-tuning, pre-trained models, and LLM agents.
Text-to-SQL Problem Definition
The task of Text-to-SQL focuses on converting natural language questions into SQL queries, enabling non-experts to query databases effectively. The main challenge lies in producing SQL queries that accurately represent the user's intent while accommodating diverse database schemas. The task is often formulated as a sequence-to-sequence problem, optimizing for the probable SQL query given the input question and schema.
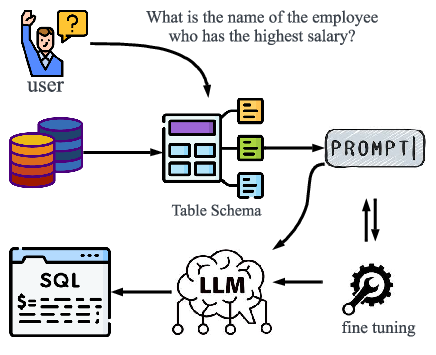
Figure 1: Flowchart of the Text-to-SQL. The flowchart illustrates the process where user questions and the database schema are first collected. These inputs are then processed through prompt engineering and fine-tuning techniques before being passed to a LLM. The LLM generates the corresponding SQL query based on the refined inputs, allowing for accurate query formulation based on natural language input.
Evolution of Text-to-SQL Models
Traditional Methods
Initial approaches to Text-to-SQL utilized rule-based systems or template approaches which lacked flexibility and scalability. The development of deep learning models like LSTMs and Transformers marked a significant shift, allowing models to handle complex queries through better context understanding and sequence handling capabilities. However, these models still faced challenges in generalization across domains due to inherent limitations in schema representation and data variability.
Prompt Engineering
Prompt engineering leverages the pre-trained capabilities of LLMs like GPT-3 and ChatGPT, providing them with carefully constructed prompts to generate SQL queries. Strategies within this domain include zero-shot, few-shot, and chain of thought prompting.
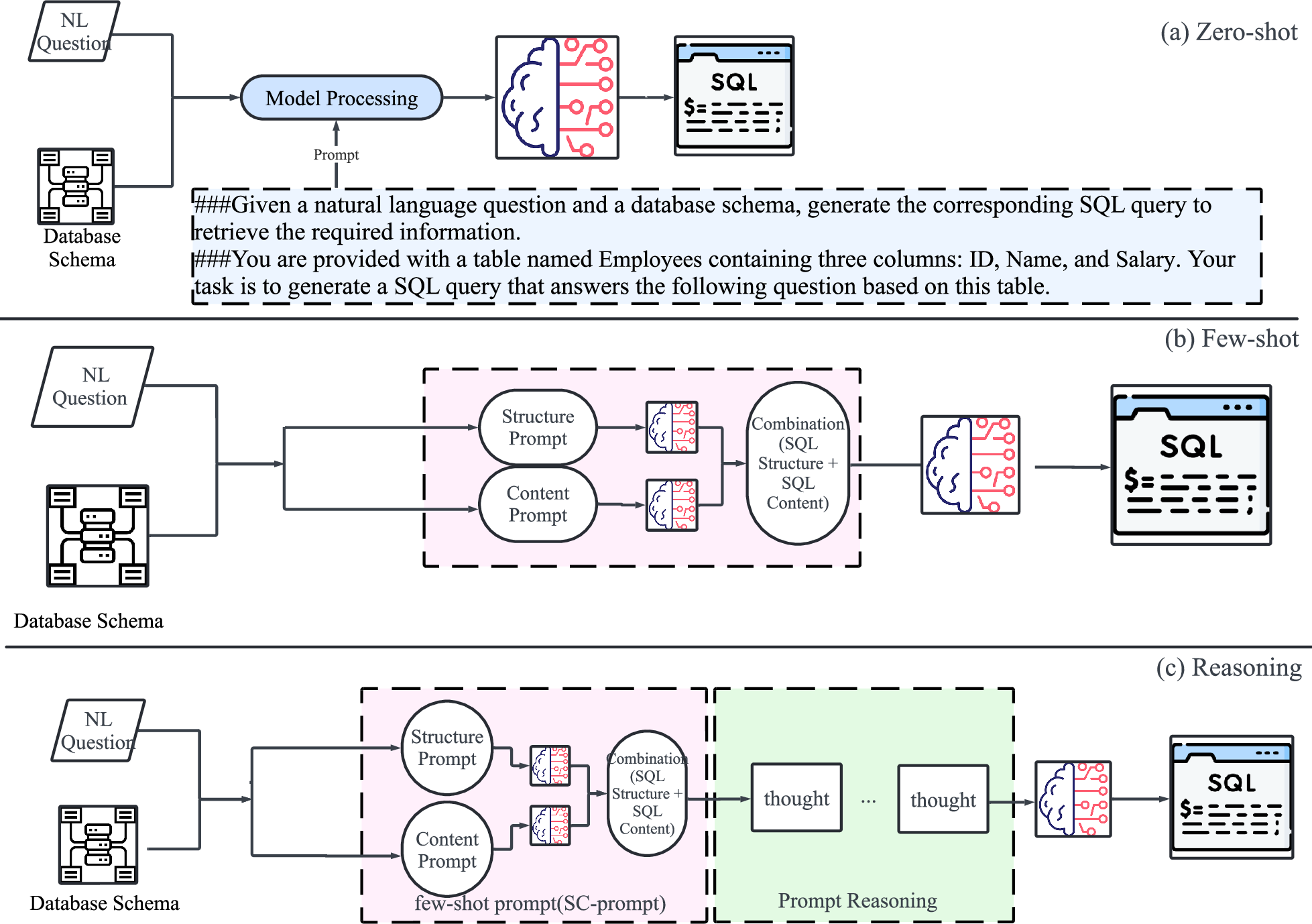
Figure 2: Prompt Engineering Methods. The figure illustrates three key prompt engineering approaches for Text-to-SQL: (a) zero-shot, where the model generates SQL without prior examples; (b) few-shot, which provides a few examples to guide query generation; (c) Reasoning, breaking down the reasoning process step-by-step for complex queries.
Fine-Tuning and Pre-trained Models
Fine-tuning involves adjusting LLMs to feel the nuances of specific datasets, enhancing performance metrics like execution accuracy and exact SQL matching. This category splits into full-parameter fine-tuning and parameter-efficient approaches, deciding on which parts of the model require adjustments to better reflect the dataset specifics. The effective use of models like BERT, TaBERT, and GraPPa evidenced substantial improvements in performance on benchmark datasets.
LLM Agents
The most recent innovation involves using multiple agents or intelligences in tandem for SQL generation. These models offer dynamic query generation capable of interacting, correcting, and optimizing queries based on external variables and feedback, enhancing robustness against data inconsistencies and schema variations.
Metrics and Datasets
Evaluation of Text-to-SQL models comprises several key metrics, like Exact Matching Accuracy (EM), Execution Accuracy (EX), Valid Efficiency Score (VES), and Test-suite Accuracy (TS). These metrics ascertain the syntactic correctness and execution efficacy of generated queries. The survey identifies various datasets used for training and testing, ranging from simple single-domain databases to complex cross-domain scenarios.
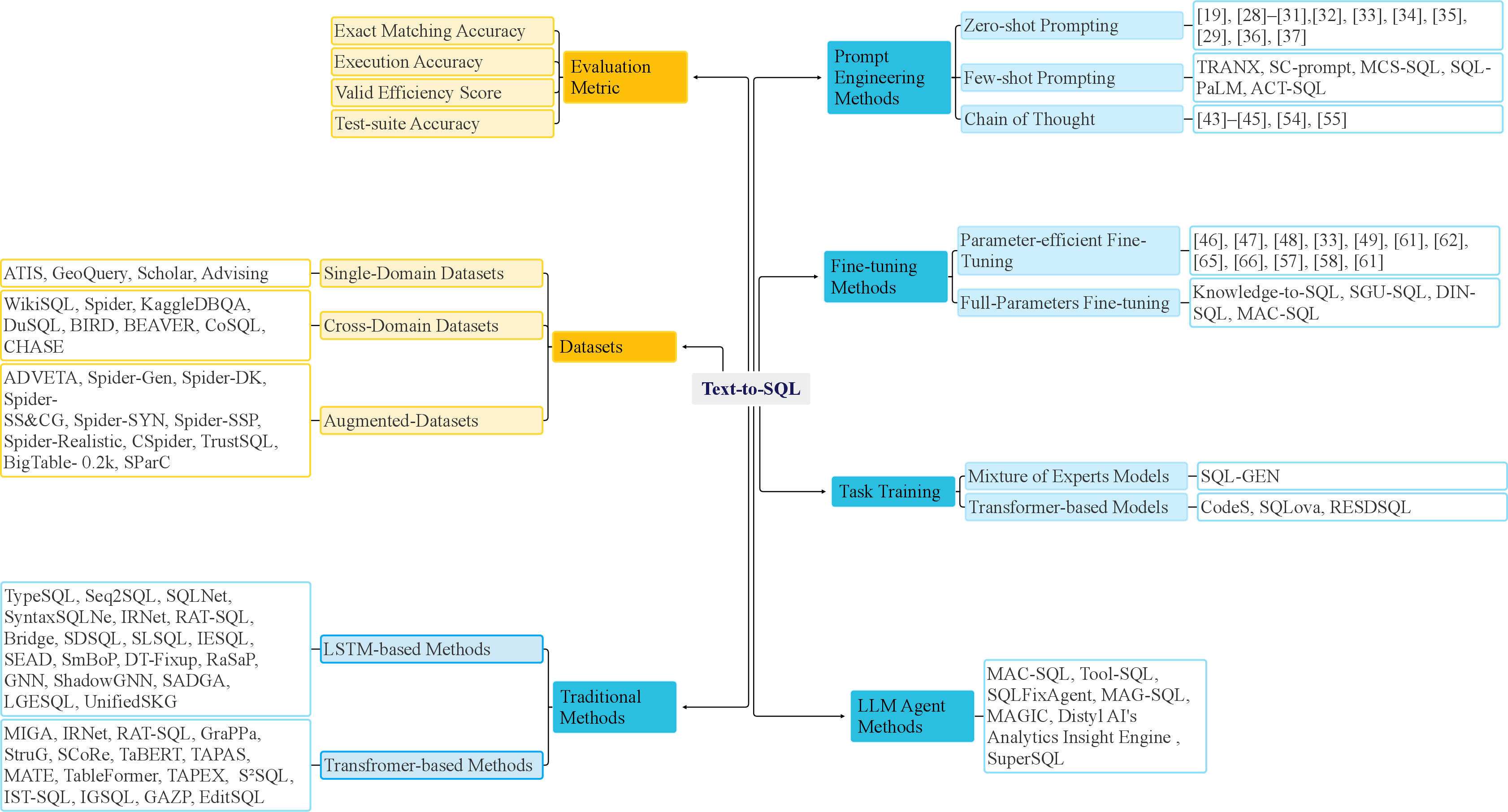
Figure 3: The overview of the text-to-SQL metrics, datasets, and methods.
The utility of datasets like Spider, WikiSQL, KaggleDBQA, and BIRD are discussed, emphasizing characteristics like SQL complexity, domain breadth, and dialogue context. They present challenges that current models must overcome to improve real-world applicability.
Conclusion
The survey concludes with an analysis of advancements in LLM-based Text-to-SQL models. As LLMs continue to evolve, the convergence of prompt engineering, fine-tuning, and intelligent agent frameworks promises further enhancements in SQL generation performance. The paper identifies continuous challenges, especially in the areas of cross-domain generalization and efficiency on large-scale databases, presenting avenues for future exploration in automated database querying systems. Continued research and innovation are anticipated to drive increased effectiveness in human-database interaction, making database querying increasingly accessible to non-specialists.

