- The paper introduces FLEX, a novel metric that leverages LLMs to address execution-based evaluation shortcomings in text-to-SQL systems.
- FLEX incorporates multi-faceted context including schema alignment and contextual cues to robustly assess semantic equivalence.
- Empirical validation shows FLEX achieves higher agreement with expert evaluations, prompting significant benchmark ranking reassessments.
Detailed Analysis of "FLEX: Expert-level False-Less Execution Metric for Reliable Text-to-SQL Benchmark"
Introduction
The paper "FLEX: Expert-level False-Less EXecution Metric for Reliable Text-to-SQL Benchmark" (2409.19014) introduces a novel evaluation metric, FLEX, aimed at addressing the shortcomings of existing methods in evaluating text-to-SQL systems. Execution Accuracy (EX), though widely utilized, is plagued by false positives and negatives due to its reliance solely on execution results. The authors propose FLEX, leveraging LLMs to provide a more accurate reflection of human expert evaluations by considering semantic correctness and comprehensive contextual information.
Analysis of Existing Evaluation Metrics
The paper identifies critical limitations of the EX metric, which fails to evaluate the semantic equivalence between the natural language intent and the generated SQL query. False positives occur when semantically incorrect queries coincidentally produce correct results due to specific database states. Conversely, false negatives arise when semantically correct queries yield different execution results due to annotation issues or ambiguous questions. Such deficiencies significantly hinder the accurate assessment of text-to-SQL systems, potentially allowing suboptimal models to be recognized as effective solutions.
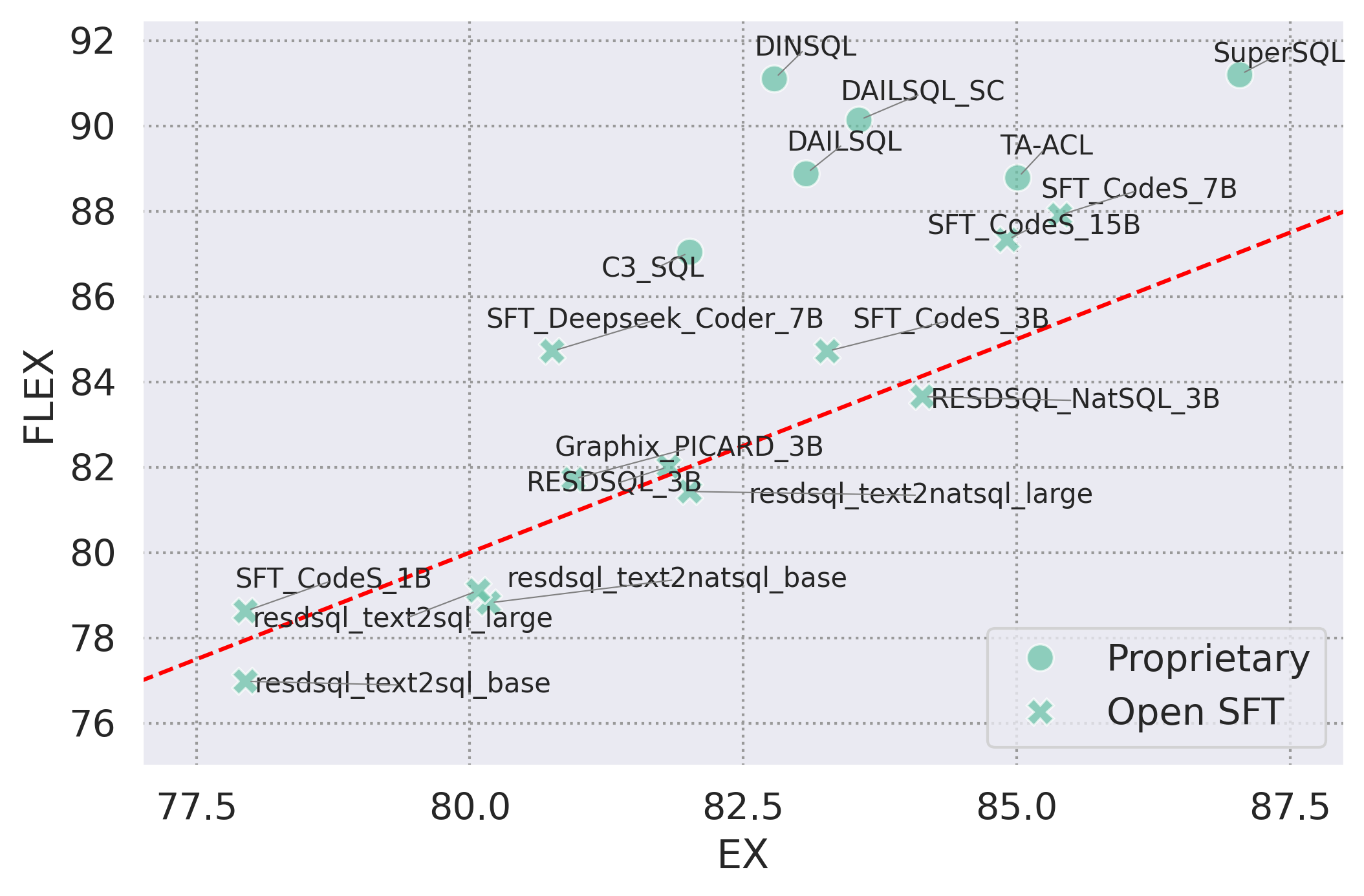
Figure 1: Performance comparison of EX vs. FLEX metrics on Spider benchmark. The red identity line shows an equivalent score.
FLEX: Methodology and Implementation
FLEX utilizes LLMs to mimic expert-level evaluations by introducing a multi-faceted context to the evaluation process. Key components include the natural language question, SQL query, database schema, execution results, and expert criteria for evaluation. Unlike prior methods that solely compare the generated and ground truth queries, FLEX employs criteria such as schema alignment, handling of nullable columns, and accurate filtering conditions to assess queries.
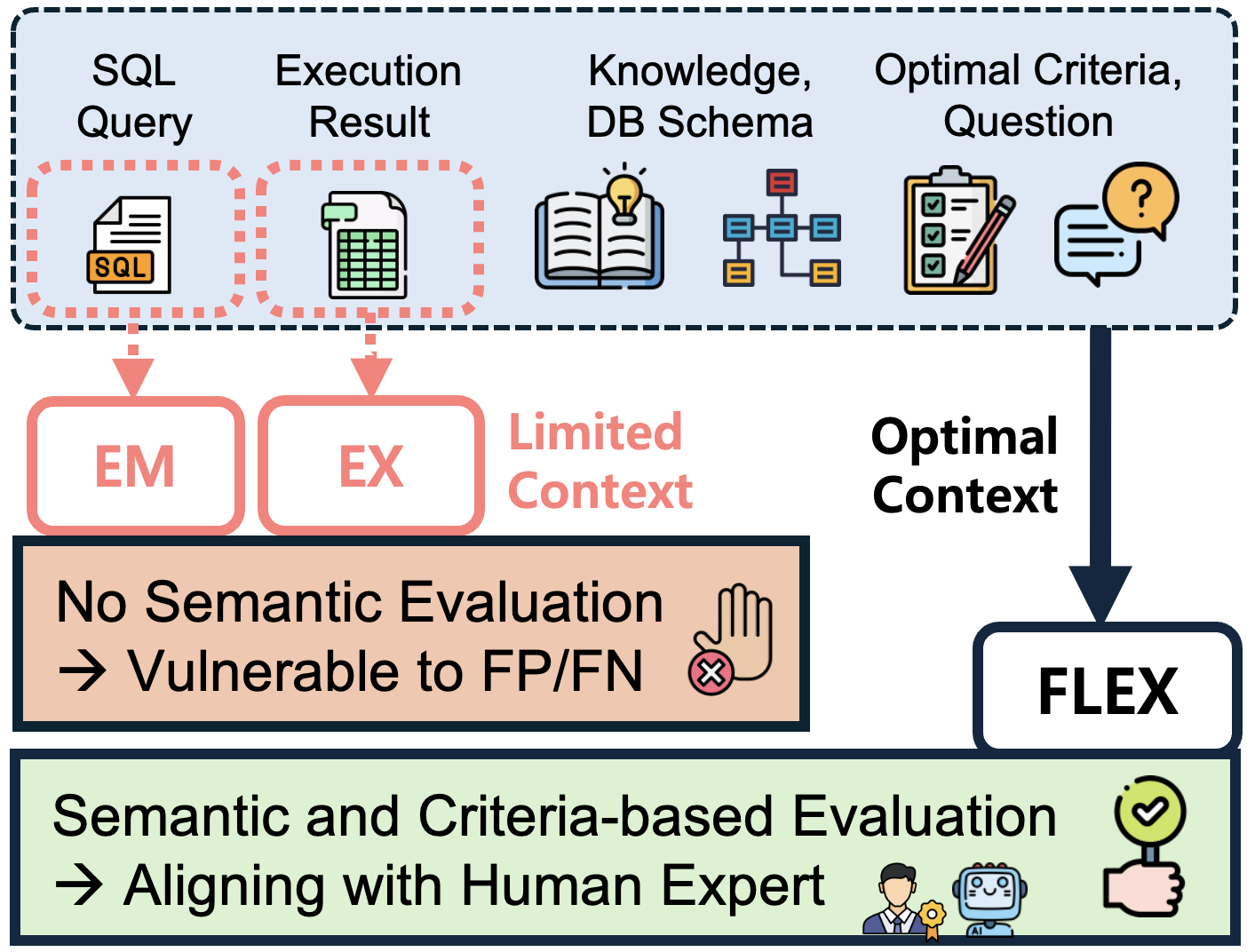
Figure 2: Compared to conventional EM and EX, FLEX evaluates semantic equivalence between question and query based on holistic, contextual information.
Empirical Validation
Extensive experiments demonstrate FLEX's superiority in aligning with human expert evaluations, achieving a Cohen's Kappa of 87.04 compared to EX's 62.00. The re-evaluation of text-to-SQL models using FLEX reveals underestimation by EX due to annotation quality issues. FLEX's ability to identify models' true capabilities prompts a reevaluation of rankings on benchmarks like Spider and BIRD, highlighting the need for nuanced evaluation methodologies.
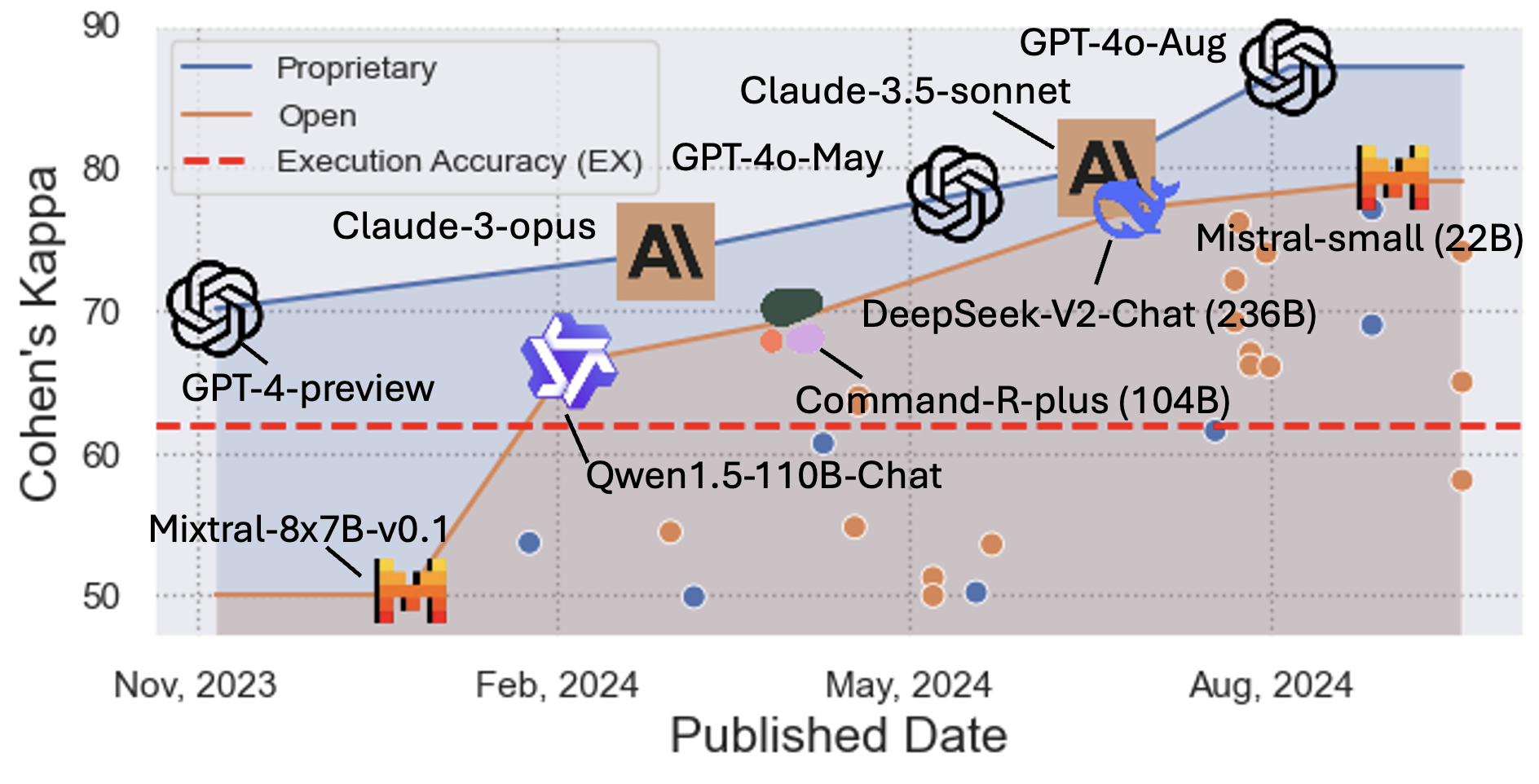
Figure 3: Agreements between human evaluation and FLEX across LLM models over time.
Leaderboard Re-evaluation Findings
Reassessing the Spider and BIRD benchmarks with FLEX reveals significant ranking shifts, indicating that the EX metric underestimates certain models. This adjustment underscores the necessity of FLEX's advanced evaluation approach to capture models' true capabilities, particularly in addressing annotation noise and schema variability.
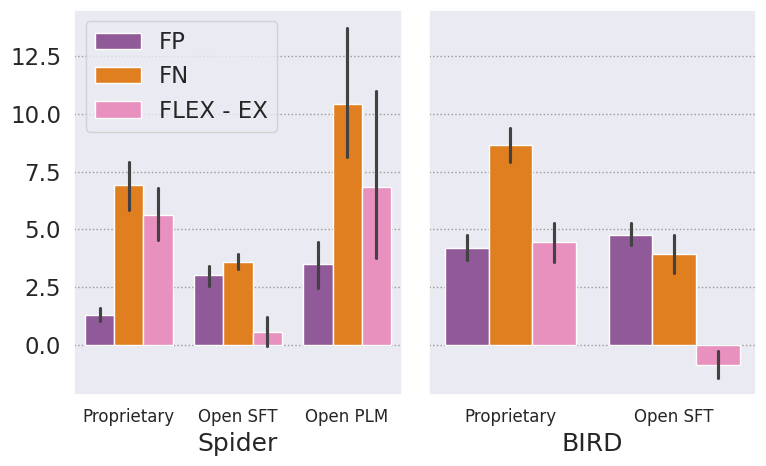
Figure 4: Average model performances and error ratios across different model types.
Future Implications
The introduction of FLEX as a robust evaluation tool presents invaluable opportunities for refining text-to-SQL systems. It fosters advancements in understanding the semantic equivalences between natural language questions and SQL queries. The recognition of current evaluation methods' limitations facilitates further research in developing methods that mimic expert reasoning, enhancing the reliability and applicability of state-of-the-art models in practical settings.
Conclusion
The FLEX metric presents a substantial shift towards more accurate evaluation of text-to-SQL models, overcoming the inherent limitations of execution-based metrics. By emulating expert-level reasoning through comprehensive contextual analysis, FLEX provides a pathway to more reliable assessments, fostering greater advances in the field of natural language processing and database interfaces. Its ability to discern true model capabilities will undeniably shape the future landscape of text-to-SQL evaluation standards.