Traffic expertise meets residual RL: Knowledge-informed model-based residual reinforcement learning for CAV trajectory control
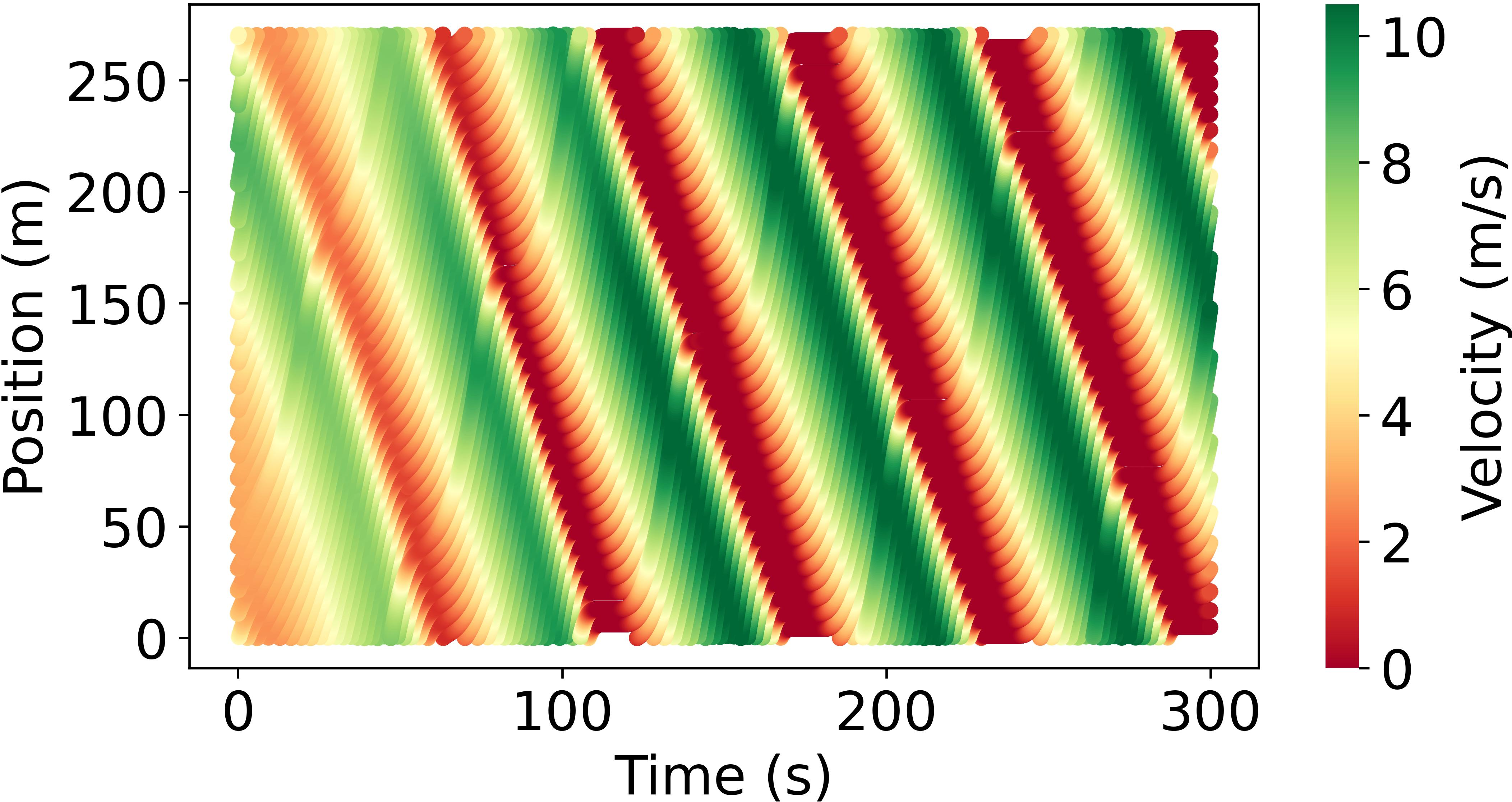
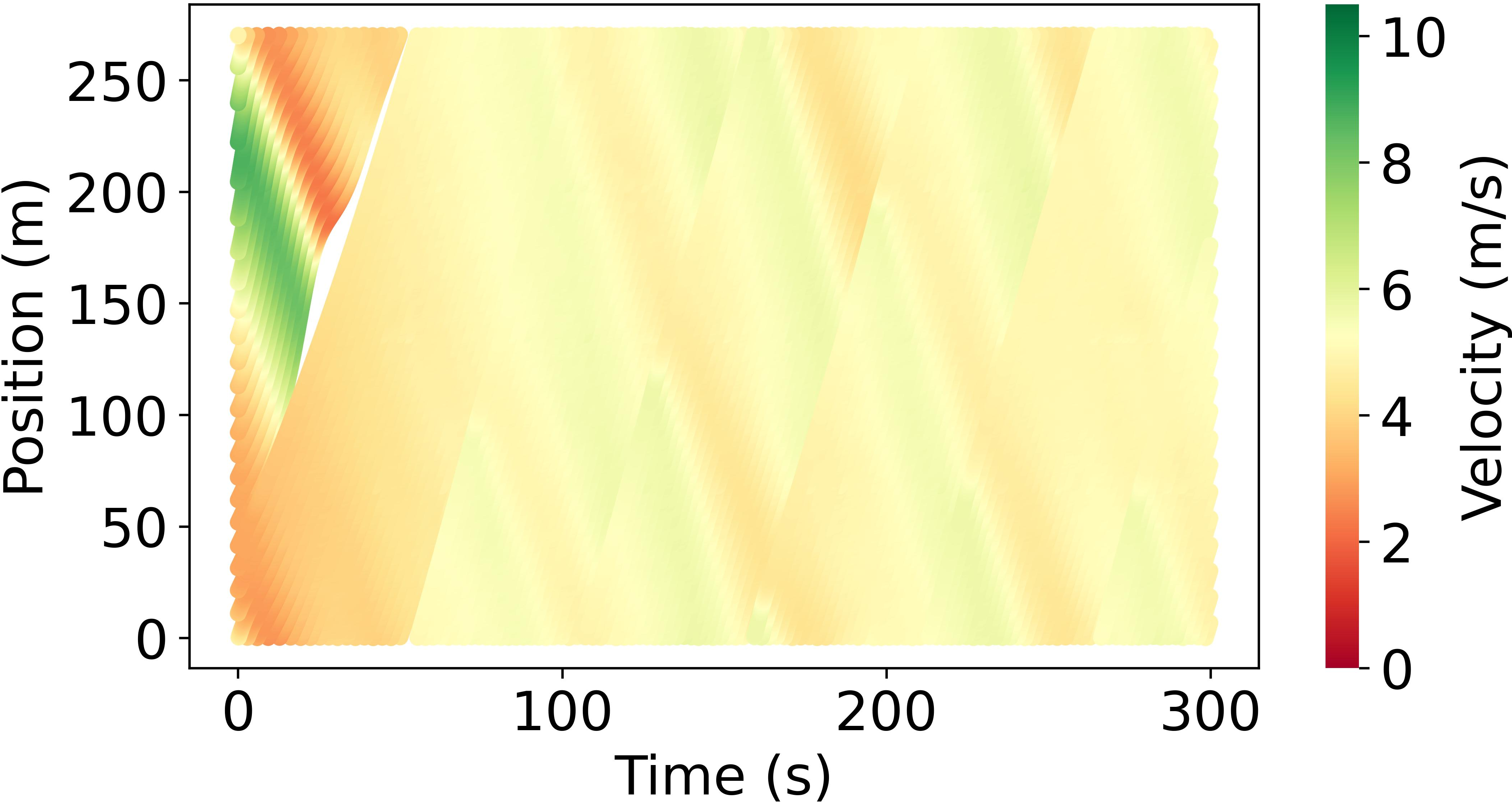
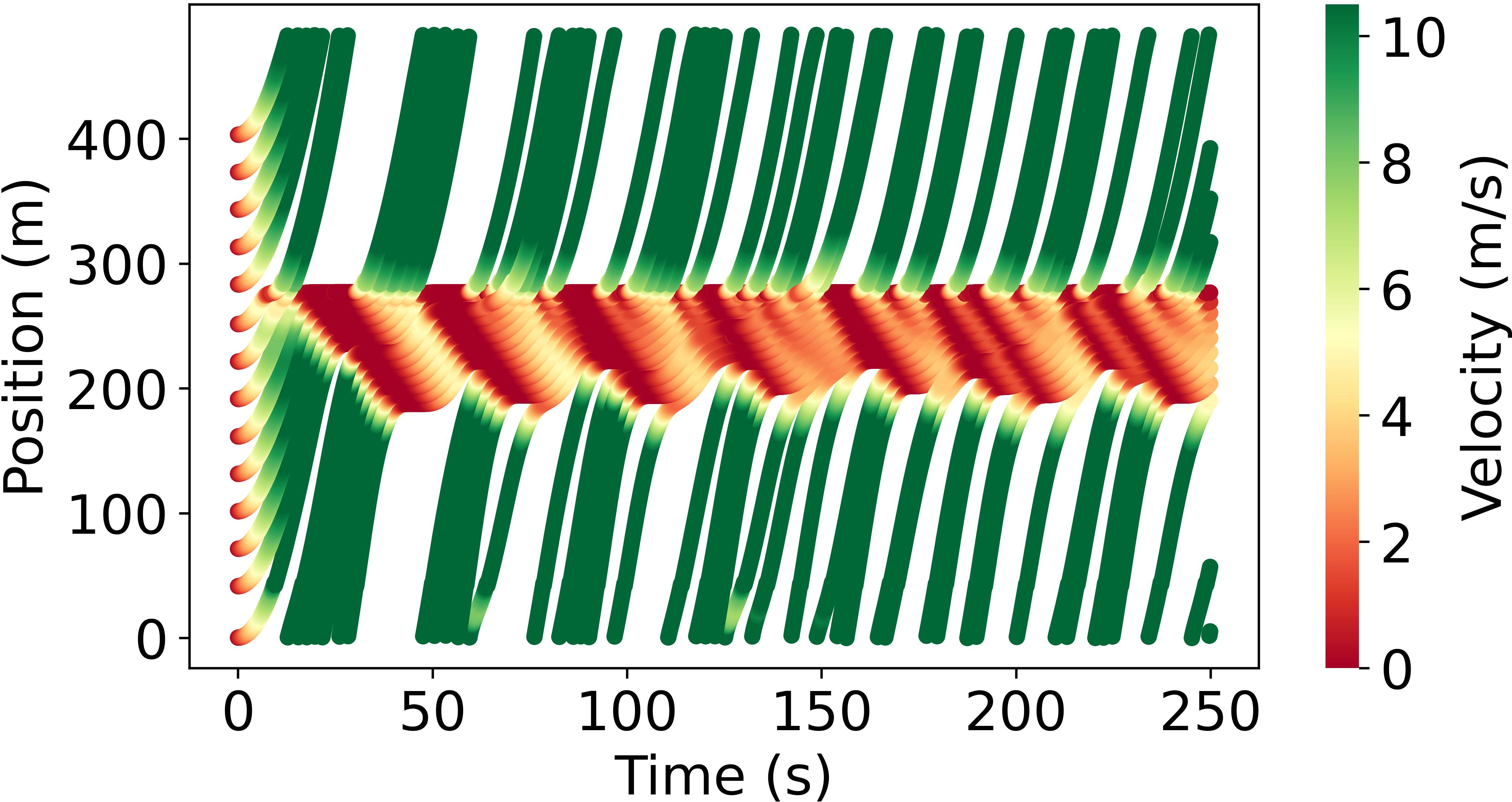
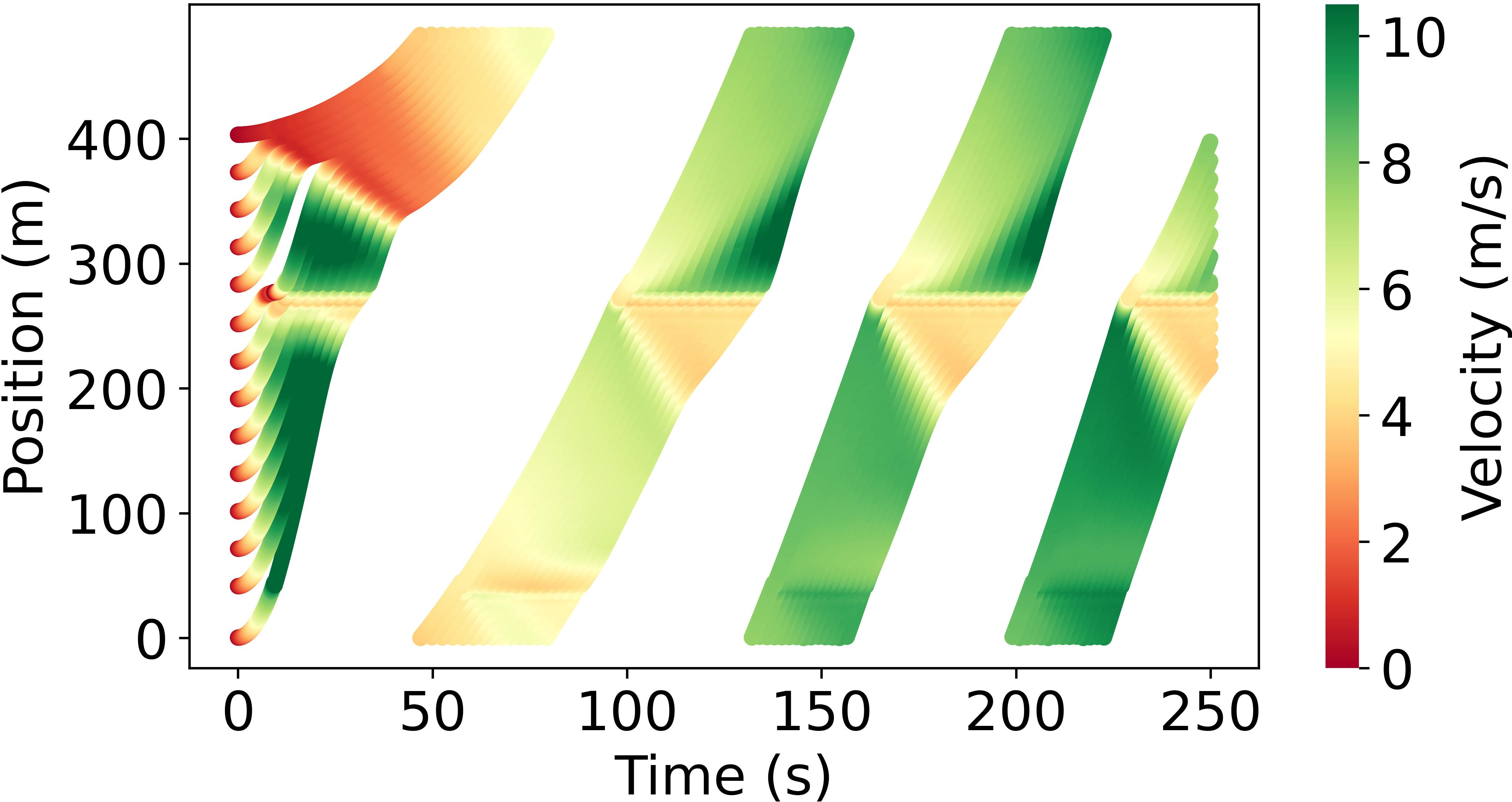
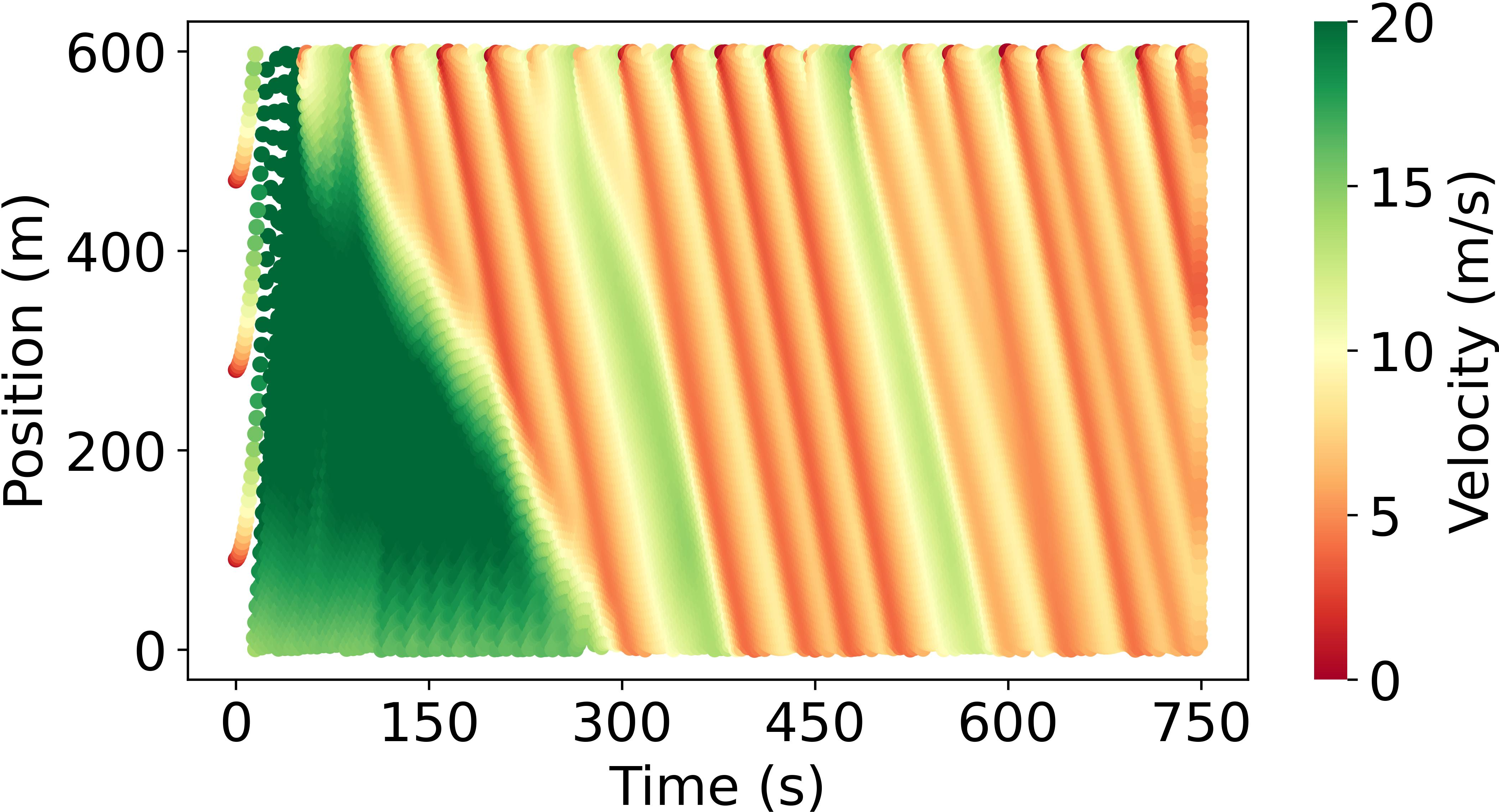
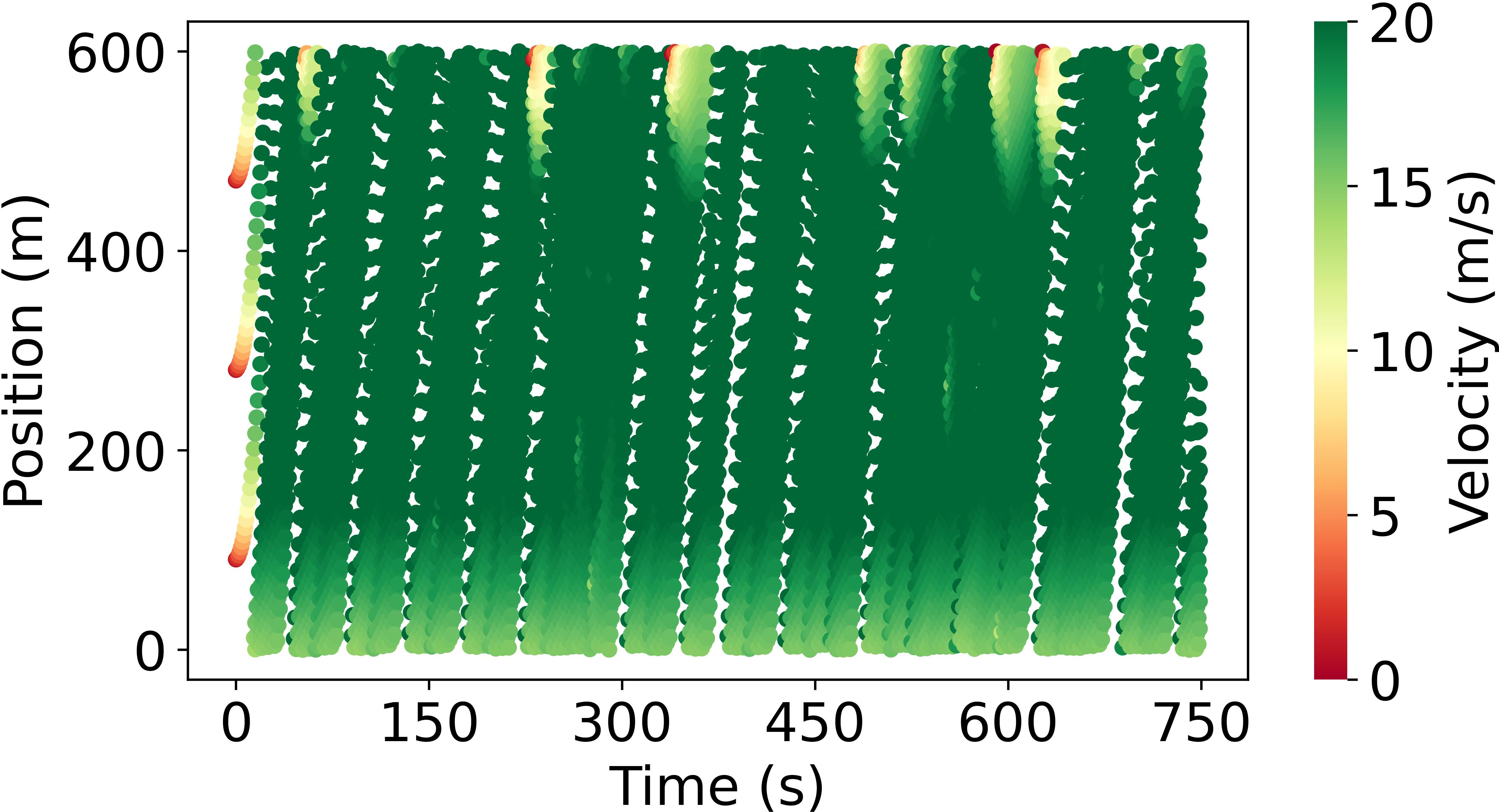
Abstract: Model-based reinforcement learning (RL) is anticipated to exhibit higher sample efficiency compared to model-free RL by utilizing a virtual environment model. However, it is challenging to obtain sufficiently accurate representations of the environmental dynamics due to uncertainties in complex systems and environments. An inaccurate environment model may degrade the sample efficiency and performance of model-based RL. Furthermore, while model-based RL can improve sample efficiency, it often still requires substantial training time to learn from scratch, potentially limiting its advantages over model-free approaches. To address these challenges, this paper introduces a knowledge-informed model-based residual reinforcement learning framework aimed at enhancing learning efficiency by infusing established expert knowledge into the learning process and avoiding the issue of beginning from zero. Our approach integrates traffic expert knowledge into a virtual environment model, employing the Intelligent Driver Model (IDM) for basic dynamics and neural networks for residual dynamics, thus ensuring adaptability to complex scenarios. We propose a novel strategy that combines traditional control methods with residual RL, facilitating efficient learning and policy optimization without the need to learn from scratch. The proposed approach is applied to CAV trajectory control tasks for the dissipation of stop-and-go waves in mixed traffic flow. Experimental results demonstrate that our proposed approach enables the CAV agent to achieve superior performance in trajectory control compared to the baseline agents in terms of sample efficiency, traffic flow smoothness and traffic mobility. The source code and supplementary materials are available at: https://zihaosheng.github.io/traffic-expertise-RL/.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

