- The paper introduces a benchmark quantifying Semantic Aggregation Hallucination (SAH) in long-video understanding using adversarial QA pairs.
- It employs a semi-automated dataset pipeline and analyzes SAH via in-video versus out-video hallucinations, detailing a novel SAH Ratio metric.
- Mitigation strategies with enhanced positional encoding and Direct Preference Optimization (DPO) reduce SAH, underscoring the need for aggregation-aware model designs.
ELV-Halluc: Benchmarking Semantic Aggregation Hallucinations in Long Video Understanding
Introduction and Motivation
The paper introduces ELV-Halluc, a benchmark specifically designed to evaluate and analyze Semantic Aggregation Hallucination (SAH) in long-video understanding by multimodal LLMs (Video-MLLMs). SAH is defined as the phenomenon where a model correctly perceives frame-level semantics but incorrectly aggregates these into event-level semantic groups, leading to misattribution of concepts across temporally distinct events. This error mode is particularly prevalent in long videos with multiple events, where semantic complexity and temporal structure amplify the risk of aggregation errors.
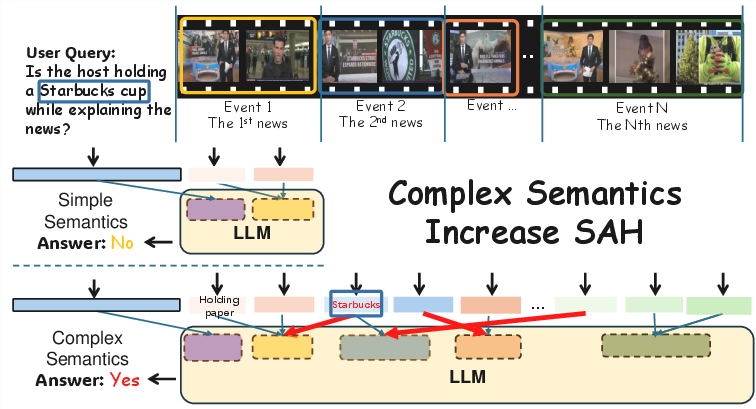
Figure 1: Increasing semantic complexity in long-video scenarios amplifies Semantic Aggregation Hallucination (SAH), with red arrows indicating erroneous aggregation into internal semantic groups.
Previous benchmarks have focused on short videos and attributed hallucinations to vision-language misalignment, poor frame quality, or strong language priors. However, these do not capture the unique challenges posed by long videos, where SAH emerges as a distinct and critical failure mode. ELV-Halluc fills this gap by providing a systematic framework for quantifying and analyzing SAH, enabling targeted evaluation and mitigation strategies.
Benchmark Construction and Dataset Design
ELV-Halluc is constructed from event-by-event videos, each containing multiple clearly separated events under a unified topic (e.g., news broadcasts with several news items). This structure facilitates the isolation of semantic units and increases the likelihood of inducing SAH, as semantics can be reorganized into plausible but incorrect descriptions.
The data construction pipeline is semi-automated: initial captions are generated using Gemini 2.5 Flash, followed by manual verification and refinement to ensure high-quality ground-truth annotations.
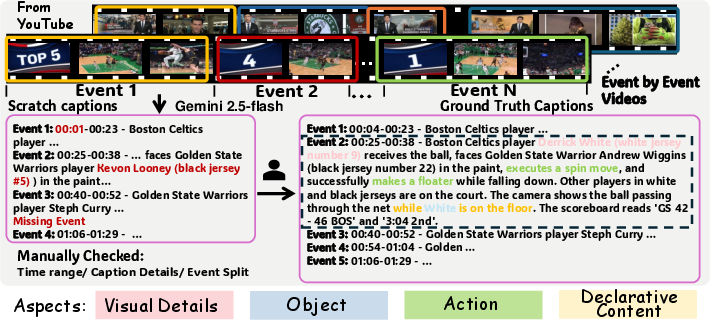
Figure 2: Overview of the data construction pipeline, illustrating the generation and manual verification of captions, with semantic content highlighted for further modification.
Dataset statistics reveal substantial diversity in video duration, topic coverage, and event count, supporting robust evaluation across a range of semantic complexities.
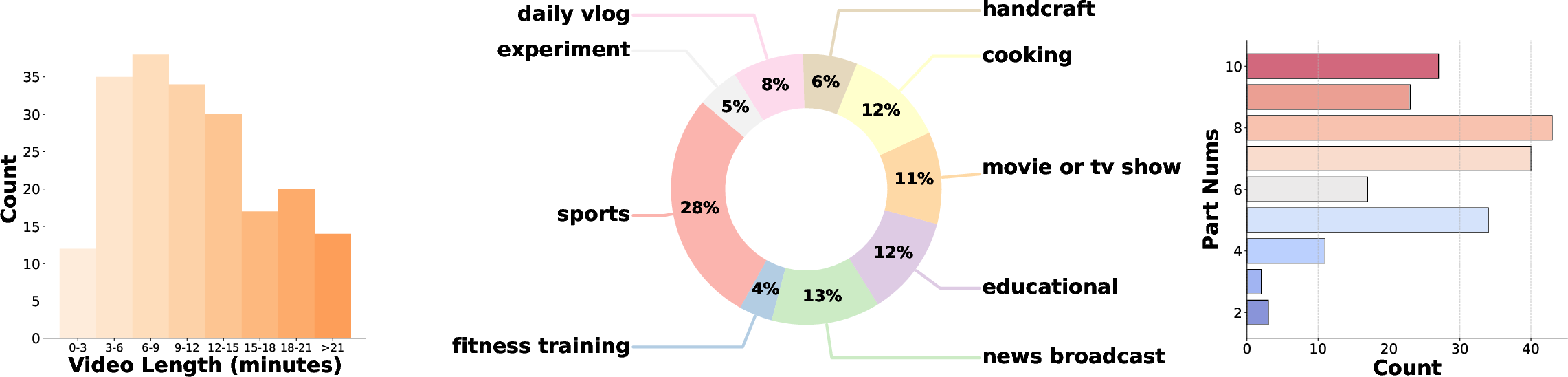
Figure 3: Dataset statistics showing duration distribution, topic distribution, and number of events per video.
Hallucination Evaluation Protocol
To evaluate hallucination, the benchmark employs adversarial question–answer (QA) pairs targeting four semantic aspects: visual details, action, object, and declarative content. Modifications are performed using GPT-4o, generating both in-video and out-video hallucinated captions. In-video modifications swap semantic elements between events within the same video, while out-video modifications introduce elements not present in any event.

Figure 4: Showcase of in-video and out-video modifications, demonstrating the adversarial construction of hallucinated captions.
Each QA pair consists of a ground-truth caption and a hallucinated caption, with the model required to correctly identify both. This design enables precise measurement of the model's sensitivity to semantic misalignment across events—a direct proxy for SAH.

Figure 5: Examples of ELV-Halluc QA pairs across different semantic aspects, illustrating the benchmark's format and diversity.
Metrics: SAH Ratio and Accuracy
The paper introduces the SAH Ratio to quantify the proportion of aggregation errors among all hallucination cases. The metric is defined as:
SAH Ratio=1−InAccOutAcc−InAcc
where OutAcc and InAcc denote accuracy on out-of-video and in-video hallucination pairs, respectively. This formulation isolates the contribution of SAH from other error sources and enables interpretable, model-agnostic analysis.
Experimental Results and Analysis
Extensive experiments are conducted on 14 open-source Video-MLLMs (1B–78B parameters) and two closed-source models (GPT-4o, Gemini 2.5 Flash). Results confirm that SAH is a persistent challenge, with most models exhibiting substantially lower accuracy on in-video hallucinated captions compared to out-of-video ones. Notably, SAH does not necessarily correlate with overall hallucination rates, and its severity increases with semantic complexity (i.e., more events per video).
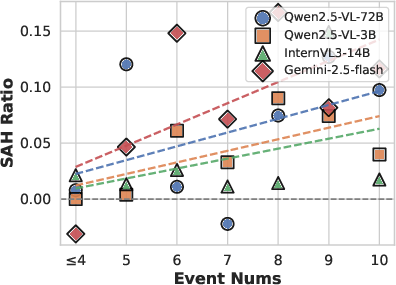
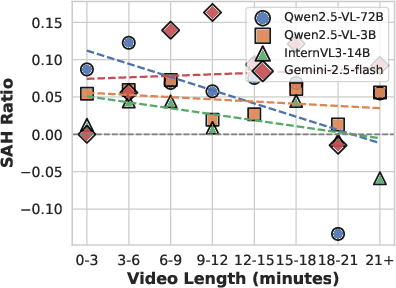
Figure 6: SAH Ratio vs. Event Count, demonstrating positive correlation between semantic complexity and SAH.
SAH is most prevalent in aspects with rapid temporal variation, such as visual details and actions, and least in declarative content.
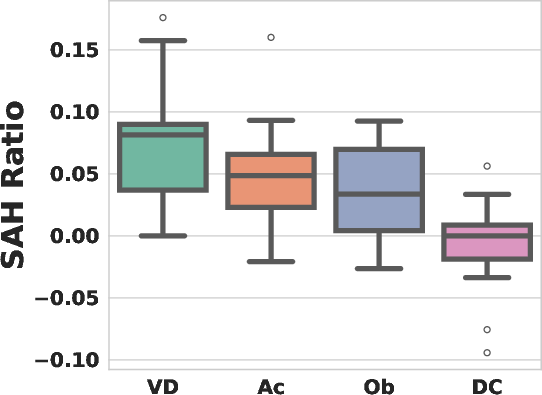
Figure 7: SAH Ratio across different semantic aspects, with highest values for Visual Details and lowest for Declarative Content.
Increasing the number of sampled frames generally improves overall hallucination accuracy but also increases SAH ratio, indicating a trade-off between semantic coverage and aggregation risk. Larger model sizes yield higher overall accuracy but do not consistently reduce SAH, suggesting that scaling alone is insufficient to address aggregation errors.
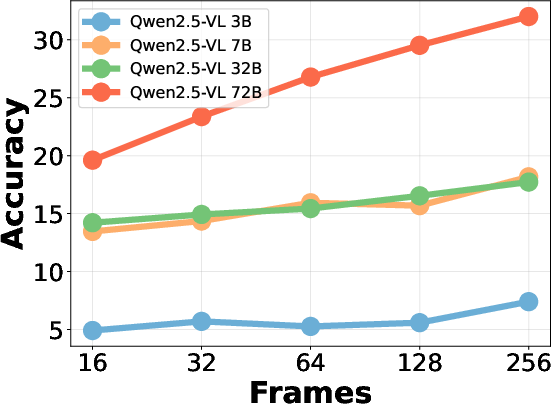
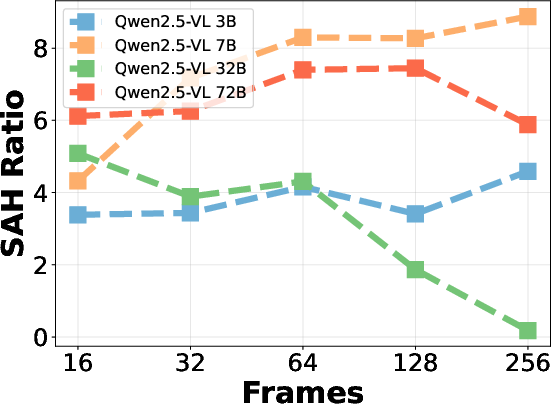
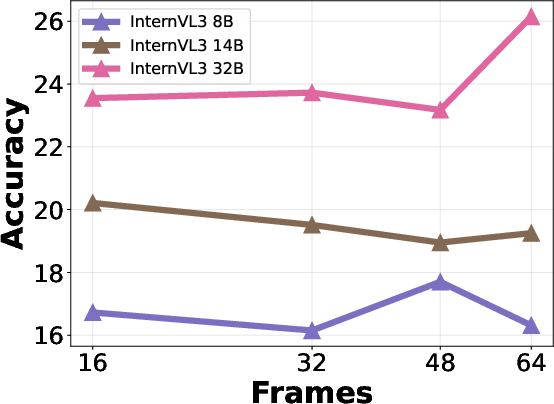
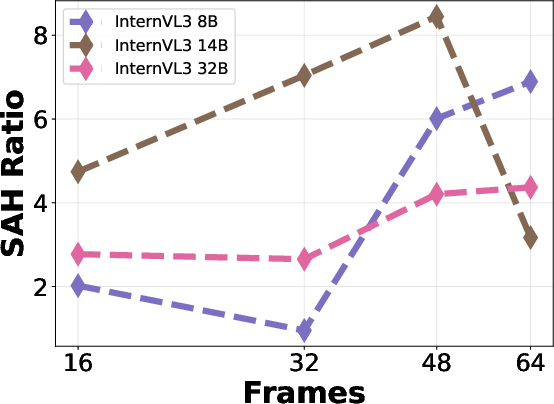
Figure 8: Qwen2.5-VL accuracy vs. frame count, illustrating the impact of frame sampling on hallucination performance.
Mitigation Strategies: Positional Encoding and DPO
The paper investigates mitigation strategies for SAH, focusing on positional encoding and Direct Preference Optimization (DPO). Stronger RoPE variants (e.g., VideoRoPE) enhance the model's ability to bind semantic relationships across frames, reducing SAH ratio but not necessarily improving overall hallucination rates.
DPO is applied using adversarial QA pairs, with in-video pairs yielding the most significant reduction in SAH (27.7%) and a modest improvement in general video understanding performance. Attention heatmaps reveal that DPO with in-video pairs effectively suppresses attention to semantically plausible but incorrect regions, providing a mechanistic explanation for improved aggregation.

Figure 9: Attention Gap Heatmap after DPO with in-video pairs, with blue regions indicating reduced attention to incorrect semantic groups.
Implications and Future Directions
The identification and systematic evaluation of SAH in long-video understanding have significant implications for the development of reliable Video-MLLMs. The results demonstrate that aggregation errors are not mitigated by increased model capacity or naive scaling of input frames, but require targeted architectural and training interventions. The benchmark and mitigation strategies proposed in this work provide a foundation for future research on robust semantic aggregation, temporal reasoning, and event-level grounding in multimodal models.
Potential future directions include scaling the dataset, exploring alternative aggregation mechanisms, and integrating explicit event segmentation into model architectures. Further investigation into the interplay between language priors and visual evidence in long-context scenarios is warranted, as is the development of more sophisticated evaluation protocols for real-world long-video applications.
Conclusion
ELV-Halluc establishes a rigorous framework for benchmarking and analyzing Semantic Aggregation Hallucination in long-video understanding. The work demonstrates that SAH is a distinct and critical error mode, exacerbated by semantic complexity and rapid temporal variation. Mitigation via positional encoding and DPO is effective but not sufficient, highlighting the need for continued research into aggregation-aware architectures and training paradigms. The benchmark, dataset, and analysis presented herein are essential resources for advancing the reliability and interpretability of Video-MLLMs in complex, multi-event scenarios.

