- The paper introduces DifuzCam which replaces traditional camera lenses with an amplitude mask and diffusion model to achieve high-quality image reconstruction.
- Methodology utilizes a ControlNet-guided pre-trained diffusion model along with separable transformations to convert raw sensor data into detailed images.
- Evaluation shows state-of-the-art performance with improved PSNR, SSIM, and LPIPS metrics, setting a new standard for lensless flat camera systems.
DifuzCam: Replacing Camera Lens with a Mask and a Diffusion Model
This paper introduces DifuzCam, an innovative approach to computational photography, specifically targeting the challenge of lensless flat cameras. The proposed method replaces traditional camera lenses with a diffuser or amplitude mask, significantly reducing size and weight. A pre-trained diffusion model is utilized with a ControlNet network and learned separable transformations to reconstruct high-quality images from raw sensor measurements.
Introduction
Flat cameras using amplitude masks enable substantial camera miniaturization but face challenges in reconstructing visually understandable images. Existing methods—direct optimization and deep learning—have not achieved satisfactory quality in reconstruction. DifuzCam proposes leveraging diffusion models as strong image priors for natural images, enhancing reconstruction quality by utilizing both image and text guidance.
Image of Prototype Flat Camera:




Figure 1: A compact prototype flat camera designed with this approach.
Methodology
Optical Design
The DifuzCam utilizes a flat camera design incorporating a separable amplitude mask printed on a chrome plate using lithography. Each mask feature is precisely constructed to allow optimal interaction with the captured image's light projections.
Mask Pattern Assessment:


Figure 2: Visualization of the mask pattern used in the flat camera prototype.
Reconstruction with Diffusion Models
A separable linear transformation converts multiplexed sensor measurements to pixel space, crucial for guiding the diffusion model, trained on vast natural image data. A ControlNet network is adapted to control the diffusion model during image generation, facilitating image recovery using pre-trained UNet architectures with zero convolutions to maintain diffusion performance.
DifuzCam System Overview:
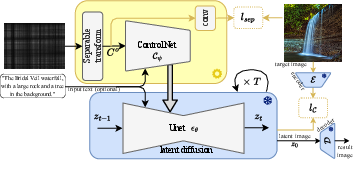
Figure 3: The DifuzCam reconstruction process using ControlNet and diffusion models.
Evaluation
The DifuzCam achieves state-of-the-art results, outperforming existing methods like Tikhonov and FlatNet in various metrics, including PSNR, SSIM, and LPIPS, with CLIP scores demonstrating effective image-text adherence. The model exhibits improved perception and textual alignment by integrating optional text descriptions during the reconstruction phase.
Implementation Details
The dataset consisted of images and their captions from LAION-aesthetics, captured using the DifuzCam prototype. Training was conducted over 500k steps with a pre-trained stable diffusion model, emphasizing the enhancement through textual guidance to align reconstructions closely with the actual scene complexity.
Conclusion
DifuzCam introduces an advanced image reconstruction technique through lensless camera technology, enhancing its practical application in imaging systems. The approach combines robust diffusion model priors with innovative text guidance, overcoming prior limitations and setting new standards in flat camera performance. This methodology holds potential for adaptation across diverse imaging contexts, fueling further innovation in computational photography.
The study suggests scalability of the DifuzCam architecture to other lensless systems, potentially revolutionizing compact device photography with increased versatility and precision in image rendering.