- The paper introduces a diffusion-transformer framework that enables arbitrary post-capture refocusing through simulated bokeh pairs and stacking constraints.
- It employs depth dropout and a stacking constraint to improve DoF consistency and robustness against inaccurate depth maps, ensuring precise focus and blur control.
- Extensive evaluations demonstrate superior performance in refocusing, bokeh addition, and deblurring, matching state-of-the-art semantic and error metrics.
DiffCamera: Arbitrary Refocusing on Images
Introduction and Motivation
DiffCamera addresses the longstanding challenge of post-capture depth-of-field (DoF) manipulation in single images. Traditional DoF effects, such as bokeh, are fixed at capture time and difficult to modify, limiting both photographic flexibility and downstream generative applications. Existing computational photography methods for refocusing typically require specialized hardware (e.g., light-field or focal sweep cameras) or are limited to all-in-focus images and heavily reliant on accurate depth maps, which are often unavailable or unreliable. DiffCamera proposes a diffusion-transformer-based framework that enables arbitrary refocusing on any image, conditioned on a user-specified focus point and bokeh level, without the need for specialized capture setups.
Methodology
Data Simulation Pipeline
A core challenge in training a refocusing model is the lack of real-world datasets containing perfectly aligned image pairs with varying focus planes and bokeh levels. DiffCamera circumvents this by simulating such data from all-in-focus images. The pipeline involves:
- Collecting a diverse set of all-in-focus images from real-world photographs, phone-captured photos, and AI-generated images.
- Estimating depth maps using Depth Anything V2.
- Generating multiple bokeh variants per image using BokehMe, systematically varying the focus plane and bokeh level.
This simulation enables the creation of large-scale, perfectly aligned DoF image pairs, facilitating supervised learning of the refocusing task.
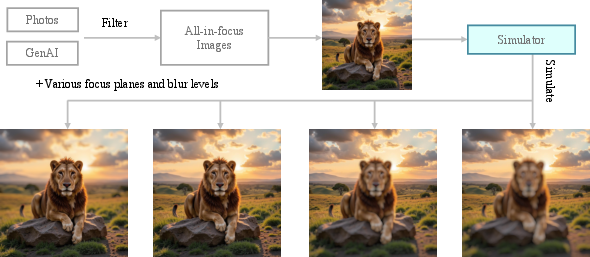
Figure 1: Data collection pipeline. Pairs are simulated on all-in-focus images with different focus planes and blur levels.
The model architecture is a diffusion transformer that operates in the latent space. The inputs are:
- Reference image IR (encoded via a frozen VAE encoder)
- Target camera conditions: focus point (fx,fy) and bokeh level b (projected into a learnable camera token)
- Predicted depth map D (optionally, see below)
- Noisy latent ITt at diffusion timestep t
All inputs are tokenized and concatenated, with full attention modeling the relationships between image content and camera parameters. The model predicts the velocity v in the rectified flow framework, enabling iterative denoising to the target refocused image.
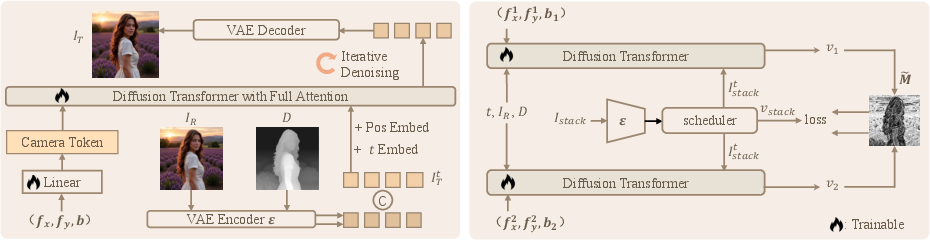
Figure 2: DiffCamera pipeline. Left: image and camera conditions are tokenized and input to a diffusion transformer. Right: stacking constraint learning objective, with shared weights and frozen VAEs.
Stacking Constraint
A vanilla diffusion objective is insufficient for precise DoF control, often resulting in incorrect focus or blur placement. DiffCamera introduces a stacking constraint inspired by photographic focus stacking: images focused at different planes can be linearly blended into a multi-focus image using a sharpness-based mask. This constraint is implemented as an additional loss in the latent space, enforcing that the model's predictions for different focus conditions can be composited to yield a physically plausible multi-focus result. This regularization significantly improves DoF consistency and adherence to camera conditions.

Figure 3: Illustration of focus stacking. Two images focused at different planes are stacked using a mask derived from Laplacian sharpness maps.
Depth Dropout
To mitigate over-reliance on potentially inaccurate depth maps, a depth dropout mechanism is introduced: during training, 50% of depth maps are replaced with zeros. This forces the model to learn to infer DoF effects both with and without explicit depth information, enhancing robustness to depth estimation errors and generalization to real-world images.

Figure 4: Qualitative studies on depth dropout. Depth dropout improves robustness to inaccurate depth maps, outperforming BokehMe and the model variant without dropout.
Experimental Evaluation
Benchmark and Metrics
A new benchmark is constructed, comprising 150 scenes (60 camera photos, 30 phone photos, 60 AI-generated images), each with multiple refocus, bokeh-adding, and deblurring samples. Evaluation metrics include:
- MAE: pixel-wise error to simulated ground truth
- LVCorr: Laplacian variance correlation with target bokeh level
- CLIP-I: semantic consistency with the reference image
- CLIP-IQA: perceptual image quality
- LPIPS, PSNR: for deblurring
Comparative Results
DiffCamera is compared against GPT-4o (DALLE3) for refocusing and bokeh addition, and against Restormer for deblurring. Notable findings:
- Refocusing: DiffCamera achieves CLIP-I of 0.954 vs. 0.859 for GPT-4o, and MAE of 0.025 vs. 0.138, indicating superior semantic consistency and lower error.
- Bokeh Addition: LVCorr of 0.920, demonstrating accurate control over blur level.
- Deblurring: Outperforms Restormer and GPT-4o in MAE, LPIPS, and CLIP-IQA, generating sharper and more consistent content in previously blurred regions.

Figure 5: Qualitative comparisons on refocusing and adding bokeh. DiffCamera performs refocusing on images with strong defocus blur, setting blur to zero and fixing the focus point at the center.

Figure 6: Qualitative comparisons on bokeh removing (deblur). DiffCamera is compared with Restormer and GPT-4o.

Figure 7: More comparisons. DiffCamera is compared with a deconvolution-based refocusing method and a two-stage Restormer+BokehMe pipeline.
Ablation Studies
Qualitative Results and Generalization
DiffCamera demonstrates robust refocusing on arbitrary focus points and bokeh levels, even in real-world photos with naturally occurring bokeh. The model maintains high scene consistency and generates plausible sharp content in previously blurred regions, despite the ill-posed nature of deblurring.

Figure 9: More visualizations on refocus. DiffCamera can refocus on arbitrary points with designated blur levels, even if the subject is originally blurry.

Figure 10: Refocusing with different blur levels, maintaining high scene consistency.

Figure 11: Application to real-world photos with natural bokeh.
Limitations and Future Directions
- Resolution and Aspect Ratio: Current training is limited to 512×512 and 1024×1024 resolutions. Scaling to higher resolutions and diverse aspect ratios is a natural extension.
- Ill-posed Deblurring: Generating sharp content from heavily blurred regions remains fundamentally ambiguous; incorporating additional reference images could address identity preservation.
- Finer Bokeh Control: Current conditioning is limited to focus point and blur level. Extending to bokeh shape and style is feasible by augmenting the data and conditioning tokens.
- Depth Robustness: While depth dropout improves robustness, further augmentation (e.g., noise injection) could enhance performance under severe depth map errors.
Conclusion
DiffCamera establishes a new paradigm for post-capture DoF manipulation in single images, leveraging a diffusion transformer trained on simulated bokeh pairs, a physically grounded stacking constraint, and depth dropout for robustness. The method achieves state-of-the-art performance in arbitrary refocusing, bokeh addition, and deblurring, with strong generalization to real-world and synthetic images. The approach provides a foundation for future research in controllable photographic editing and generative AI, with potential extensions to higher resolutions, richer camera controls, and integration with user-provided references.
