- The paper presents an end-to-end differentiable pipeline for decoupling scene generation from lens parameters to achieve precise defocus blur control.
- It combines a distilled SDXL generator, a focus distance transformer, and a differentiable lens model guided by EXIF metadata.
- Quantitative evaluations and human studies confirm superior blur monotonicity and content consistency compared to existing methods.
Fine-grained Defocus Blur Control for Generative Image Models
Introduction and Motivation
The paper addresses the challenge of precise, physically-plausible control over defocus blur in text-to-image diffusion models, conditioned on camera EXIF metadata such as aperture and focal length. Existing generative models, including those with EXIF conditioning, fail to disentangle scene content from camera parameters, resulting in poor control over blur and frequent alteration of scene content when camera settings are changed. The proposed framework introduces a modular, end-to-end differentiable pipeline that decouples scene generation from lens properties, enabling fine-grained, interactive control over defocus blur while preserving scene integrity.
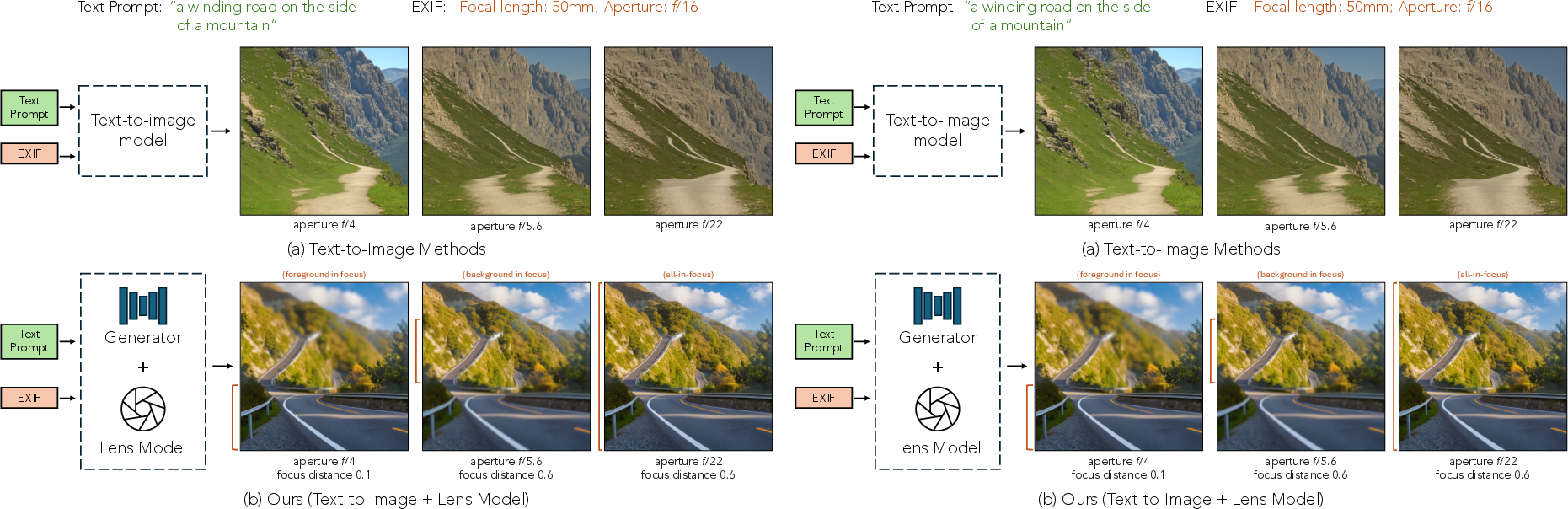
Figure 1: Overview. The model enables precise control of defocus blur location and intensity, preserving scene content across varying aperture and focus settings.
Model Architecture and Pipeline
The architecture consists of three main components: a fast few-step generator, a focus distance transformer, and a differentiable lens blur model. The generator, distilled from SDXL using DMD2, produces an all-in-focus image. A frozen monocular depth estimator (Metric3Dv2) predicts depth, which, together with the image, is processed by a fine-tuned Visual Saliency Transformer (VST) to predict focus distance and a scale factor. The lens model (TAF Lens, based on Wang et al.) applies spatially-varying blur using physically-inspired thin lens equations, parameterized by focal length, aperture, focus distance, and scale.
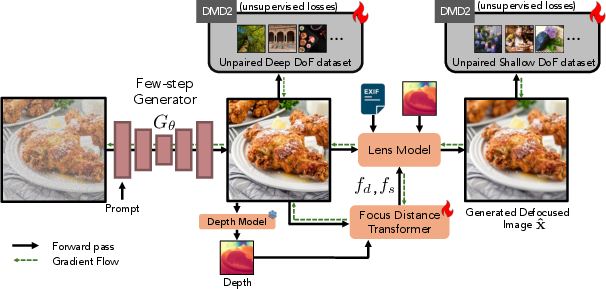
Figure 2: Model Architecture. The pipeline generates all-in-focus images, predicts depth and focus, and applies spatially-varying blur via a differentiable lens model.
The entire pipeline is trained end-to-end using weak supervision from curated deep and shallow depth-of-field datasets, with DMD2 and GAN losses for distribution matching and realism. The modular design allows lens model swapping at inference, e.g., using Dr.Bokeh for higher-quality bokeh rendering.
Dataset Construction and Supervision
Two large-scale datasets (1.5M samples each) are curated from stock photography: Deep DoF (all-in-focus) and Shallow DoF (defocused, salient object). Filtering criteria include aperture range, device type, exposure time, photographic validity, and classifier output for blur. No explicit focus distance labels are required; weak supervision is provided by the dataset structure and DMD2 losses.

Figure 3: Deep and Shallow DoF Datasets. Filtering yields all-in-focus and defocused images for training.
Training and Implementation Details
- Generator Distillation: SDXL is distilled into a 4-step generator using DMD2, enabling fast, interactive generation.
- Focus Distance Prediction: VST is fine-tuned to predict focus distance as a saliency-weighted average of depth, with a scale factor learned via an MLP head.
- Lens Model: The TAF lens model computes the circle of confusion per pixel and applies spatially-varying convolution for blur. The model is differentiable, allowing gradient flow for end-to-end training.
- Hardware: Training is performed on 16 A100 GPUs, with batch size 1 and AdamW optimizer.
- Losses: Combined DMD2, GAN, and Huber losses for generator, lens, and focus distance scale.

Figure 4: Image Generation Pipeline. All-in-focus image, depth prediction, saliency-based focus, lens model, and spatial blur kernel.
Quantitative and Qualitative Results
The proposed method is evaluated against multiple baselines: SDXL (with EXIF as text or DoF prompt), distilled SDXL, Camera Settings as Tokens, SDXL+TAF Lens, SDXL+Dr.Bokeh, and Deep-DoF Gen+TAF. Metrics include Blur Monotonicity (energy decrease with aperture), Content Consistency (semantic segmentation stability), LPIPS, and FID for both Deep and Shallow DoF datasets.
- Blur Monotonicity: The method achieves 93.91 (TAF) and 96.89 (Dr.Bokeh), outperforming all baselines.
- Content Consistency: 92.34 (TAF), highest among all methods.
- LPIPS: 0.0064 (TAF), indicating minimal perceptual change across aperture settings.
- FID: 13.24 (Deep DoF), 16.69 (Shallow DoF), lowest among all methods.
Ablation studies confirm that each component (lens model, focus distance transformer, dataset pretraining) is critical for optimal performance.
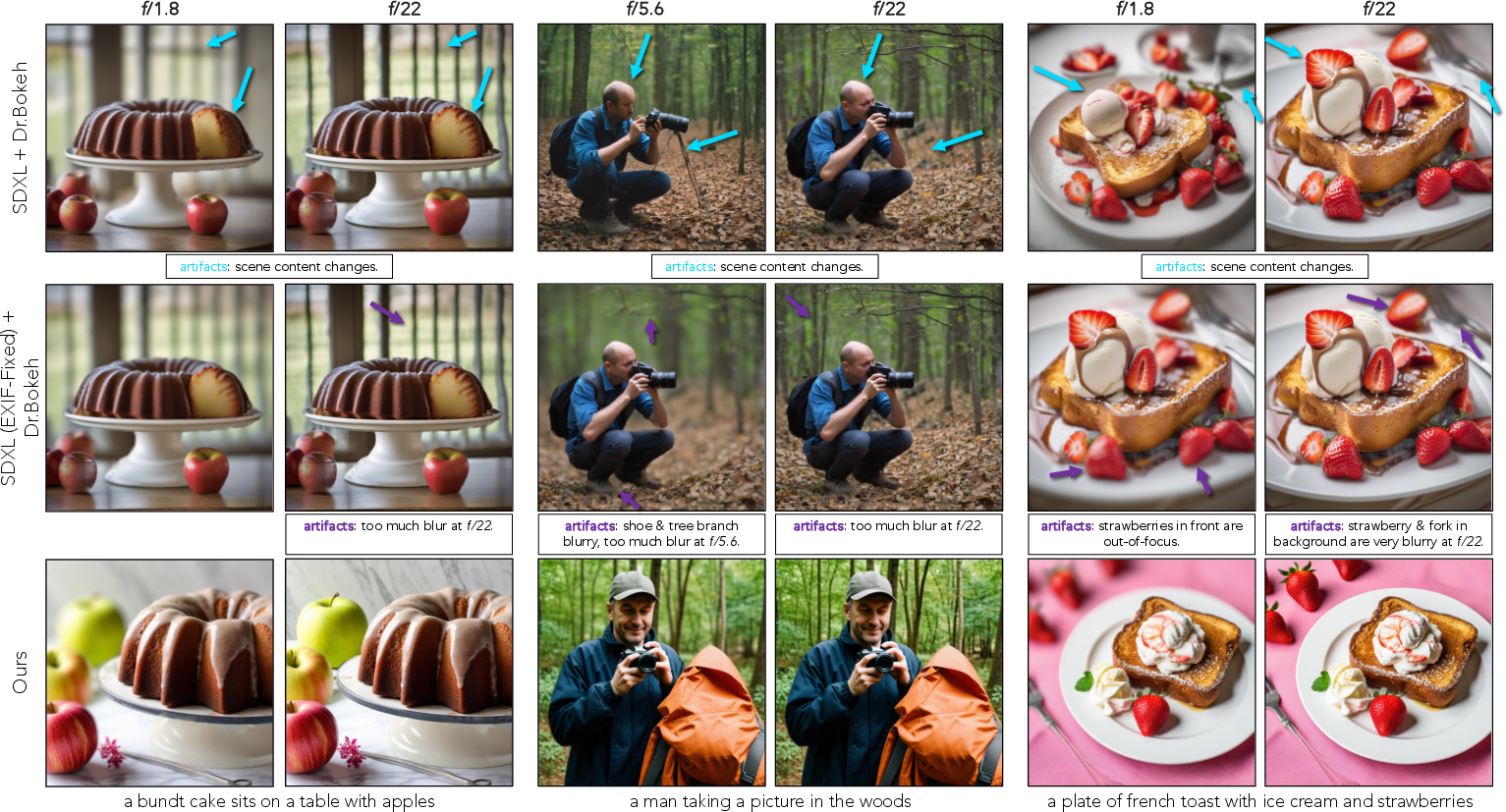
Figure 5: Qualitative Comparisons with SDXL + Dr.Bokeh. The baseline fails to preserve scene content and realistic blur across aperture changes; the proposed method maintains both.

Figure 6: Qualitative Results. The model produces consistent scene content with controllable blur as aperture varies.

Figure 7: Comparison to Camera Settings as Tokens. The baseline alters scene content and fails to control blur; the proposed method decouples blur from content.

Figure 8: Comparison to Deep-DoF Gen. + TAF. The baseline produces out-of-focus images; the proposed method maintains focus on salient regions.

Figure 9: Varying focus distances in the generation process. The focal plane shifts smoothly across depth as focus distance is changed.
Human Study
A user study with 25 participants and 25 prompts confirms that the method is preferred over baselines in at least 83% of cases for preserving scene content and realistic blur control.
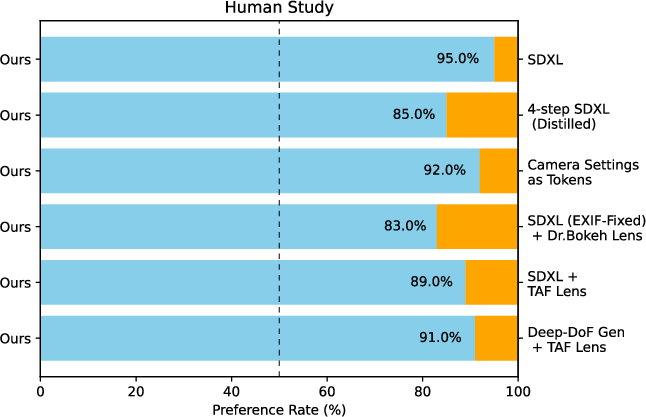
Figure 10: Human Studies. User preference rates for the proposed method over baselines.
Theoretical and Practical Implications
The framework demonstrates that explicit modeling of lens properties and focus distance, combined with end-to-end differentiable training, enables physically-plausible, fine-grained control over defocus blur in generative models. The approach is unsupervised, requiring only weak supervision from curated datasets, and is modular, allowing lens model replacement at inference. Theoretical analysis of the blur monotonicity metric is provided, with empirical validation on real photographs.
Limitations and Future Directions
- Residual Blur Priors: Occasional background blur in all-in-focus generator due to SDXL priors; larger Deep DoF datasets may mitigate this.
- Focus Distance Scale: Weakly supervised, may result in suboptimal focal planes; future work could use RGBD datasets with precise focus measurements.
- Depth Map Resolution: Limited high-frequency detail at occlusion boundaries; improved depth estimators could enhance results.
- Bokeh Shape: Only disc-shaped bokeh is learned; framework allows for stylized bokeh via lens model swapping.
Conclusion
The proposed framework provides a robust, modular solution for fine-grained, physically-plausible control of defocus blur in text-to-image generative models, conditioned on camera EXIF metadata. By decoupling scene generation from lens properties and enabling explicit focus distance estimation, the method achieves superior blur control and scene consistency compared to existing approaches. The unsupervised, end-to-end differentiable pipeline is scalable and extensible, with strong quantitative and qualitative results validated by human studies. Future work may explore supervised focus distance learning, higher-resolution depth estimation, and stylized bokeh rendering.