- The paper demonstrates a log-linear relationship between model parameters and performance, while highlighting additional influences from training data and instruction tuning.
- It employs the clembench framework to evaluate LLMs across diverse conversational games, revealing distinct thresholds for instruction-following and interactive competence.
- The study shows that inference implementation and quantization choices critically modulate practical LLM performance in real-world dialogue applications.
Introduction
This paper provides a comprehensive analysis of how various model characteristics drive LLM performance when evaluated through self-play of conversational games, using the clembench framework. Unlike prior research that primarily focused on next-token prediction accuracy or static NLP benchmarks, this study interrogates interactive, agentive LLM abilities, decomposed into fine-grained measures of instruction-following and game competence. The investigation empirically quantifies the impact of scale (parameter count, training data size), instruction-tuning method, data quality, inference implementation, and quantization on LLM performance in situated, goal-oriented contexts.
The results reveal a statistically significant log-linear relationship between model parameter count and aggregate clembench score (R2=0.57), which further improves with the inclusion of training data size (R2=0.67). However, this only partially accounts for the observed variance. Notably, there is considerable performance spread within parameter size brackets, indicating additional influential factors beyond model magnitude.
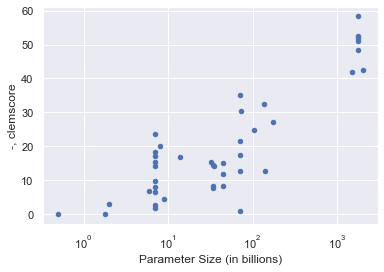
Figure 2: Clemscore versus model size demonstrates a significant but not exhaustive relationship; variance within size buckets is substantial.
Further analysis breaks down the contributions of model characteristics to both instruction-following (% played) and interactive competence (quality score) across the suite of evaluated games. In tasks such as imagegame, successful engagement and high-quality responses emerge only in larger models, while simpler formats such as taboo or wordle exhibit early instruction-following but delayed quality gains.
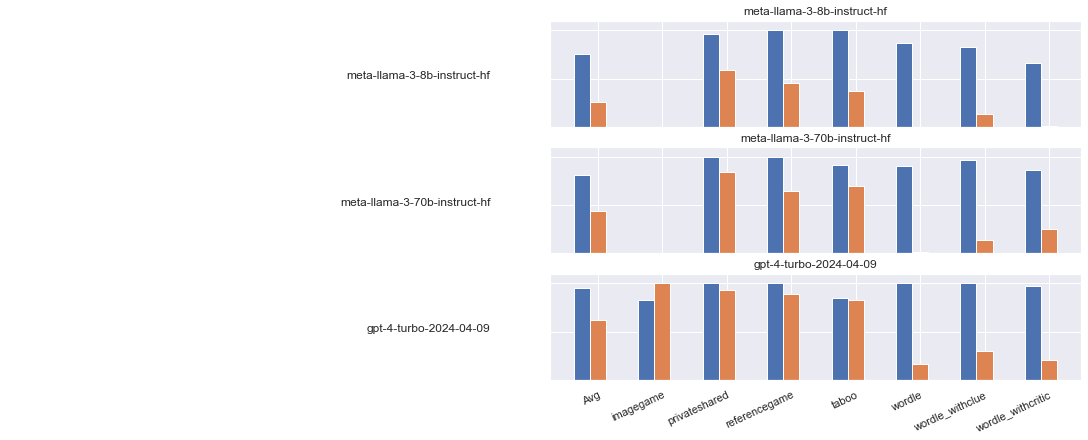
Figure 3: Score profiles of representative models highlight divergent development of instruction-following and competence across games.
Influence of Instruction-Tuning Data and Method
The dataset conducts a natural experiment: fine-tuned variants derived from the same base model (e.g., mistral-7b, llama-2-70b-hf) demonstrate wide disparities in clembench performance, up to 17 points within a single base. The openchat-3.5 family, for instance, achieves higher scores in earlier releases, despite newer versions optimizing for broader coverage and additional capabilities such as mathematical reasoning. Differences arise from both instruction-tuning technique (e.g., PPO vs. C-RLFT) and, critically, the composition and format of the fine-tuning data—models favoring a balanced mixture of "chat" and "reasoning" demonstrations in instruction datasets exhibit superior agentive test-time performance. Notably, improved general benchmark results in a model lineage do not monotonically translate to gains in these interactive-agentive tasks.
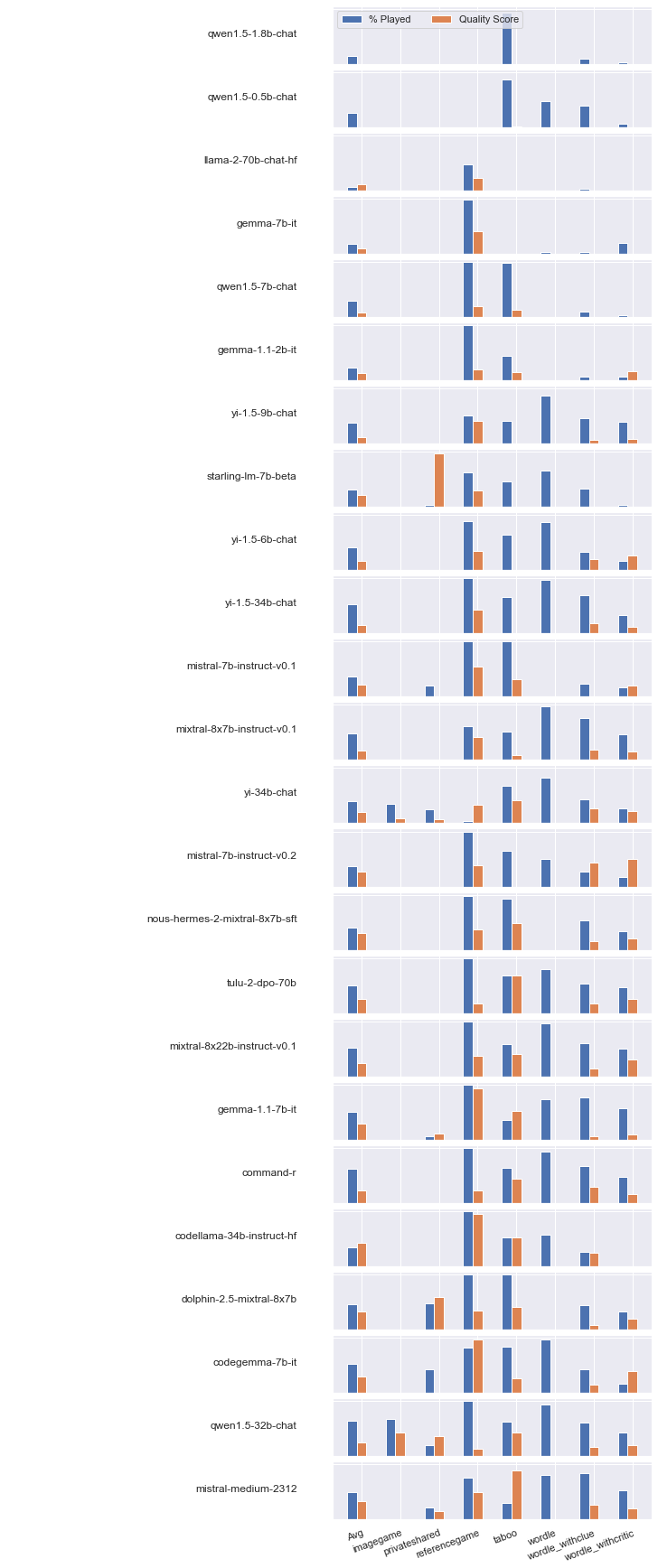
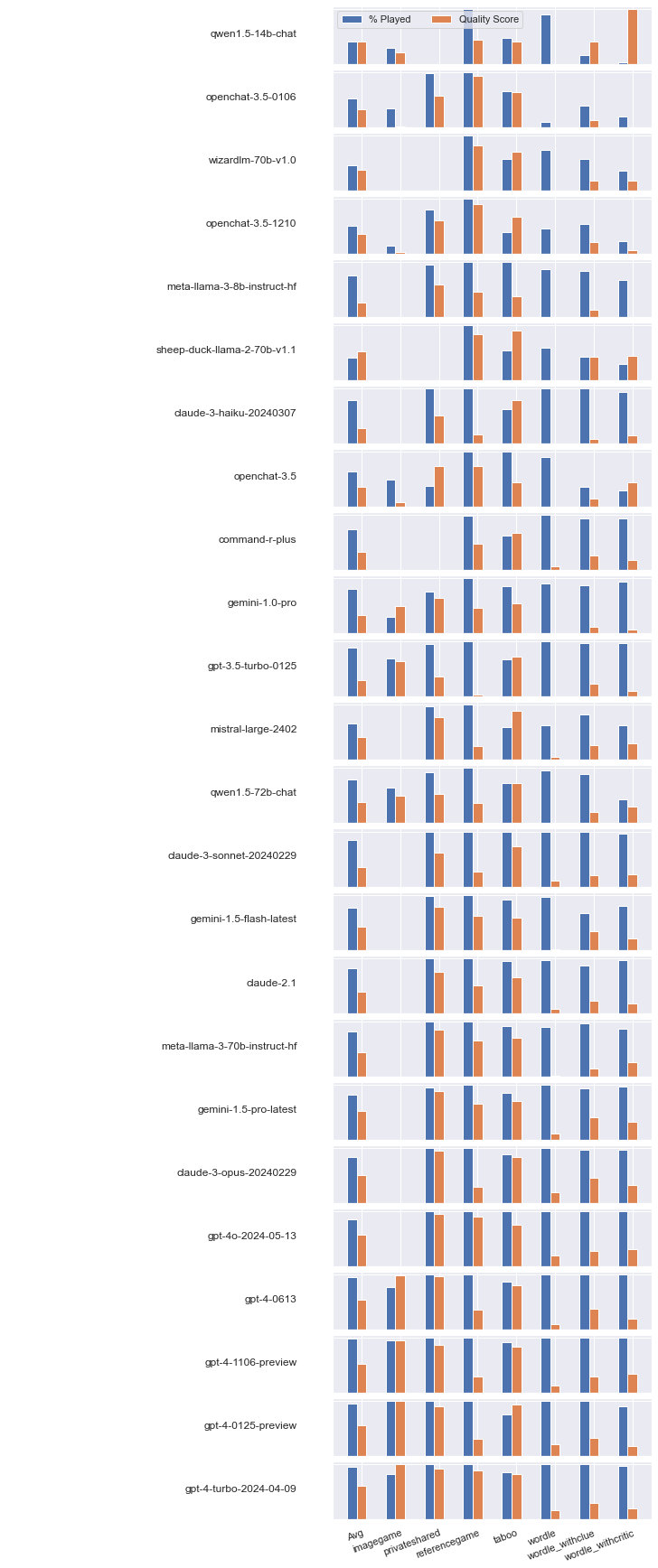
Figure 1: Aggregated and per-game clembench profiles for all tested models, revealing complex interplay between instruction-following and effective play.
Effects of Inference Implementation and Quantization
Unexpectedly, aggregate clembench scores can differ by up to 5 points when using the same model weights accessed via different inference providers (API, local, etc.), despite controlling for temperature and other common settings. These discrepancies are attributed to non-public sampling parameterization, input formatting (system/user prompt templates), stop token handling, and other provider-specific preprocessing and decoding practices.
Quantization experiments show that 8-bit quantized models maintain essentially indistinguishable clembench performance relative to full precision, especially in larger models; 4-bit quantization leads to more pronounced, but still moderate, performance loss. This implies that serving quantized agentive models is feasible and cost-effective for these interactive tasks.
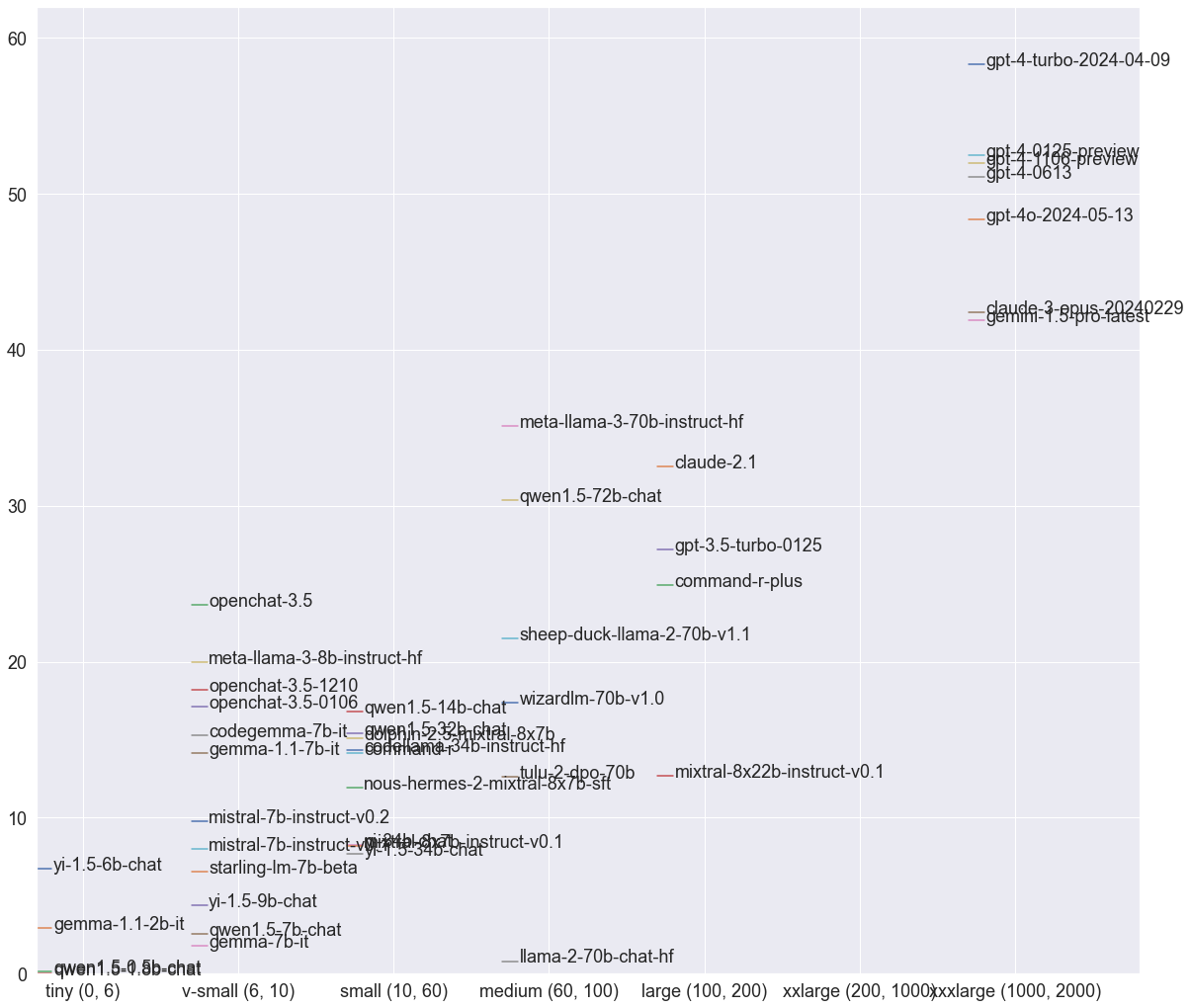
Figure 4: Binned performance by model size, showcasing intra-bucket variation driven by factors beyond scale.
Dynamics and Per-Task Progression
Fine-grained tracking of % played and quality across models sorted by size and performance establishes that, for dialog games like imagegame, complex capabilities (e.g., abstract visual description or spatial referencing) emerge only in the largest models and with appropriate data. In contrast, skill progression in games like taboo is more gradual and scale-sensitive. Crucially, sudden, discrete "emergence" phenomena are not supported; improvements remain broadly continuous as scale and data quality increase.
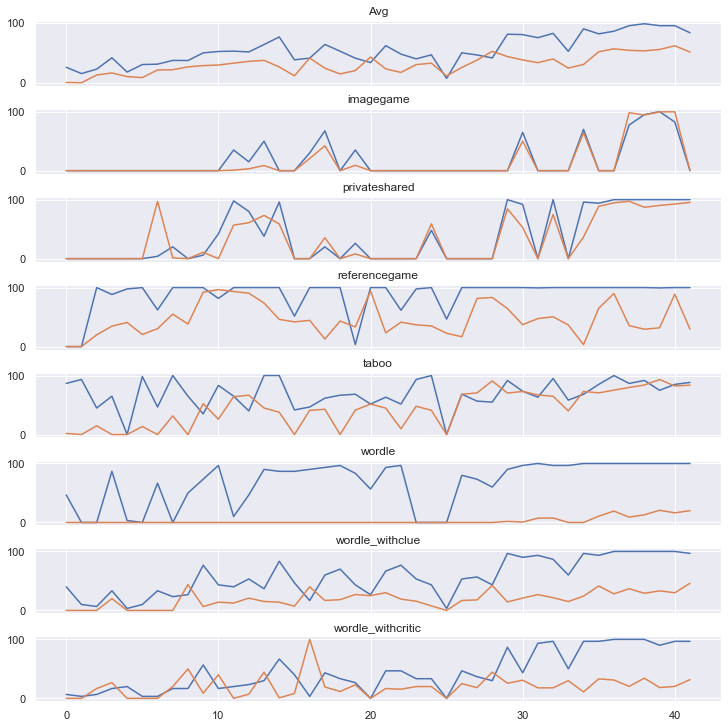
Figure 5: Dynamics of improvement (sorted by model and score), with task-specific curves highlighting varied thresholds and gradients in agentive ability emergence.
Theoretical and Practical Implications
The research demonstrates that while parameter scaling and added training data exert substantial and predictable effects, they cannot substitute for precise, high-quality instruction-tuning data and careful selection of tuning methods. Base model quality alone cannot predict downstream agentive performance; tuning methodology—including prompt formatting and data mixture—must be considered an independent control axis. Furthermore, downstream practitioners must pay attention to inference stack implementation details and quantization settings even when identical weights are in use, as these can materially alter agent performance in deployed systems.
Theoretically, these findings complicate naive scaling law interpretations for complex, interactive language tasks and challenge claims of sudden ability emergence, suggesting instead a multifactorial, continuous development regime with significant interaction effects between scale, supervision regime, and deployment context.
Conclusion
This paper advances the understanding of what properties endow LLMs with effective, goal-directed dialogic agency. It establishes that a model's parameter count and training data quantity set an upper-bound for agentive potential, but instruction-tuning data quality, method, and implementation-level factors critically mediate realized performance, yielding wide intra-size variation. Quantization to 8-bit is generally safe for practical agent deployment. Cumulatively, these findings indicate that optimal model selection for situated conversational agents requires holistic consideration of scale, data, supervision method, and serving platform, each capable of strongly modulating the realized capabilities observed in interactive evaluation settings.