- The paper reveals that DeBERTa, a masked language model, can be adapted to perform generative in-context learning through simple inference modifications.
- The methodology employs an autoregressive approach with modified input token sequences and enhanced ranking techniques to improve text generation.
- The evaluation demonstrates that DeBERTa attains competitive performance with GPT-3 on NLP tasks, paving the way for hybrid model architectures.
Summary of "BERTs are Generative In-Context Learners"
Introduction
The paper "BERTs are Generative In-Context Learners" (2406.04823) challenges prevailing assumptions that masked LLMs, specifically DeBERTa, lack the capability for generative in-context learning, a trait exemplified by models like GPT-3. The study showcases how DeBERTa can function as a generative model through a simple inference technique, without the need for additional training, demonstrating competitive performance compared to GPT-3 across several NLP tasks. This position posits that the in-context learning capabilities are not restricted to the training objectives unique to causal LLMs.
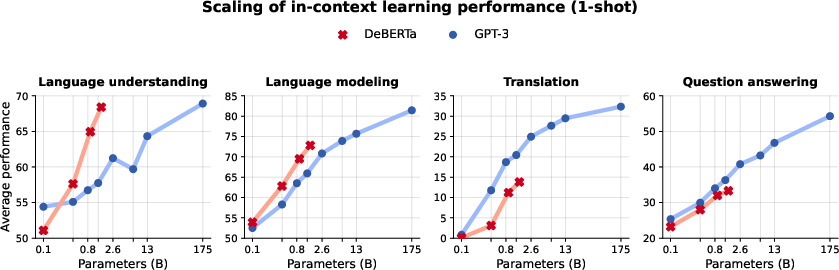
Figure 1: The average 1-shot performance across four groups of NLP tasks. We compare the scaling abilities of DeBERTa (four sizes in red) with GPT-3 (eight sizes in blue).
Methodology: Text Generation and Ranking
The authors propose methodologies for employing masked LLMs in text generation and ranking contexts. The inference techniques involve slight modifications in input token sequences, enabling DeBERTa to operate in a generative capacity similar to causal LLMs.
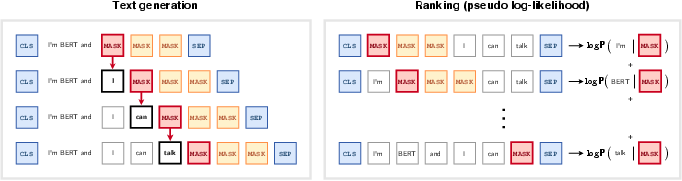
Figure 2: Illustration of the proposed methods for using a masked LLM for text generation and text ranking.
Text Generation: The paper details an autoregressive approach adapted for MLMs, placing a [MASK] token adjacent to a prompt to generate subsequent tokens iteratively. Modifications include accounting for token spans during inference to mitigate the likelihood of premature sequence termination due to common sentence-ending probabilities.
Ranking: The authors adapt the pseudo-log-likelihood score, improving its computation by masking additional tokens to account for dependencies within gradients, thereby enhancing the rank ordering of sequences.
Length Generalization
A significant consideration for DeBERTa’s applicability is its generalization to longer sequences—a limitation due to its pretraining on relatively shorter sequences. Through the "needle in a haystack" benchmark, the paper assesses length scalability, demonstrating DeBERTa's capability in handling sequences comparable to GPT-3.
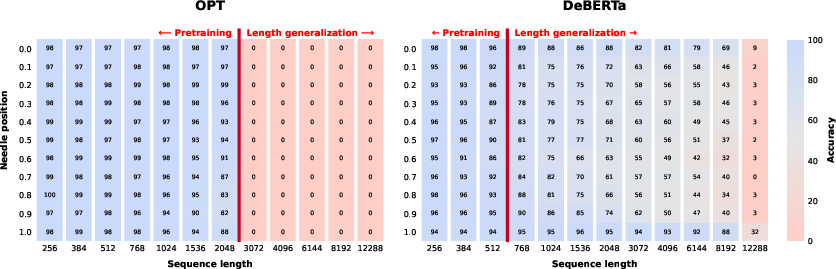
Figure 3: Length generalization measured with a 'needle in a haystack' benchmark.
Evaluation on NLP Tasks
The paper evaluates DeBERTa across several task categories including natural language understanding, language modeling, machine translation, and closed-book question answering. The results indicate the model’s superior performance in language understanding and text completion tasks, while highlighting its competitive stance in commonsense reasoning challenges.
Language Understanding (SuperGLUE): DeBERTa displays robust performance in tasks requiring comprehension, inference, and reasoning, outperforming its contemporaries in multiple metrics.
Machine Translation: Despite DeBERTa's strong language understanding capabilities, it lags behind GPT-3 in translation tasks, attributed partially to training data constraints rather than structural deficiencies.
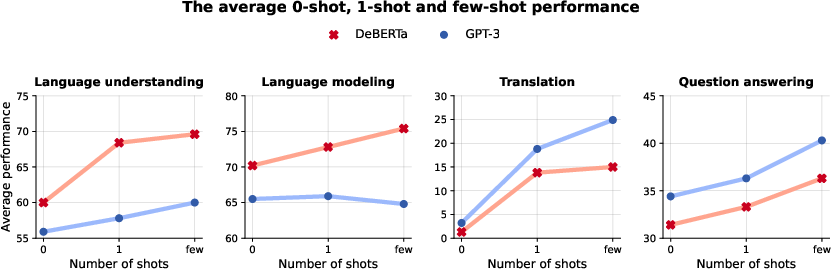
Figure 4: The performance improvement with increased number of in-context examples.
Implications and Future Directions
The findings suggest potential in creating hybrid models leveraging the strengths of both masked and causal LLMs. This path holds promise for refined generative capabilities in NLP, encouraging further exploration into hybrid mechanisms that utilize complementary training objectives.
Conclusion
The study asserts the viability of MLMs like DeBERTa as generative in-context learners, contradicting outdated perceptions of their limitations. It advocates for further research to enhance their scalability and to explore hybrid model architectures that integrate MLM and CLM-based strengths. The empirical evidence presented serves as a foundational step towards advancing the utilization of masked LLMs in broader generative contexts.