- The paper introduces BERT, a pre-trained deep bidirectional Transformer that achieves state-of-the-art results across multiple NLP benchmarks.
- It employs Masked Language Modeling and Next Sentence Prediction to capture context from both left and right text simultaneously.
- Fine-tuning BERT on diverse datasets significantly enhances performance on tasks like GLUE, SQuAD, and SWAG.
The paper "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" introduces BERT, a novel language representation model leveraging Bidirectional Encoder Representations from Transformers. BERT distinguishes itself from prior models by pre-training deep bidirectional representations from unlabeled text, enabling joint conditioning on both left and right contexts across all layers. The pre-trained BERT model can be fine-tuned with a single additional output layer to achieve state-of-the-art performance on various NLP tasks, including question answering and language inference, without significant task-specific architectural modifications.
BERT's architecture is based on a multi-layer bidirectional Transformer encoder, mirroring the original implementation. The model is characterized by the number of layers L, the hidden size H, and the number of self-attention heads A. The paper primarily presents results for two model sizes: BERTBASE (L=12,H=768,A=12, Total Parameters=110M) and BERTLARGE (L=24,H=1024,A=16, Total Parameters=340M). The input representation is designed to handle both single sentences and sentence pairs unambiguously. The input embeddings are constructed by summing the token embeddings, segmentation embeddings, and position embeddings (Figure 1).
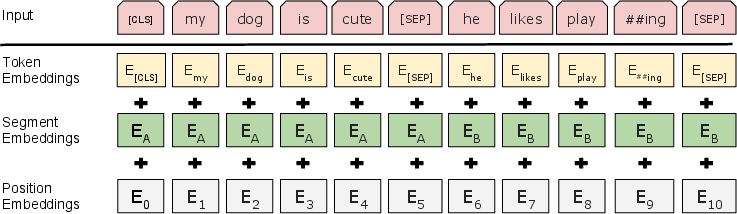
Figure 1: BERT input representation, illustrating the summation of token, segment, and position embeddings.
Pre-training Tasks: Masked LLM and Next Sentence Prediction
BERT employs two unsupervised tasks for pre-training: the Masked LLM (MLM) and Next Sentence Prediction (NSP). The MLM objective involves randomly masking some input tokens and predicting the original vocabulary ID of the masked word based on its context. This approach enables the representation to fuse left and right contexts, facilitating the pre-training of a deep bidirectional Transformer. The NSP task jointly pre-trains text-pair representations by predicting whether a given sentence B is the actual next sentence following sentence A.
The pre-training data consists of the BooksCorpus (800M words) and English Wikipedia (2,500M words). The model is trained with a batch size of 256 sequences for 1,000,000 steps, which approximates 40 epochs over the corpus. Adam is used as the optimizer with specific parameters, including a learning rate of 1e-4, weight decay of 0.01, and a dropout probability of 0.1.
Fine-tuning BERT for Downstream Tasks
Fine-tuning BERT involves initializing the model with pre-trained parameters and fine-tuning all parameters using labeled data from downstream tasks (Figure 2). Each downstream task has a separate fine-tuned model, initialized with the same pre-trained parameters. The self-attention mechanism allows BERT to model various downstream tasks by swapping out appropriate inputs and outputs. For text pairs, BERT uses self-attention to encode the concatenated text pair, effectively including bidirectional cross-attention between the two sentences.
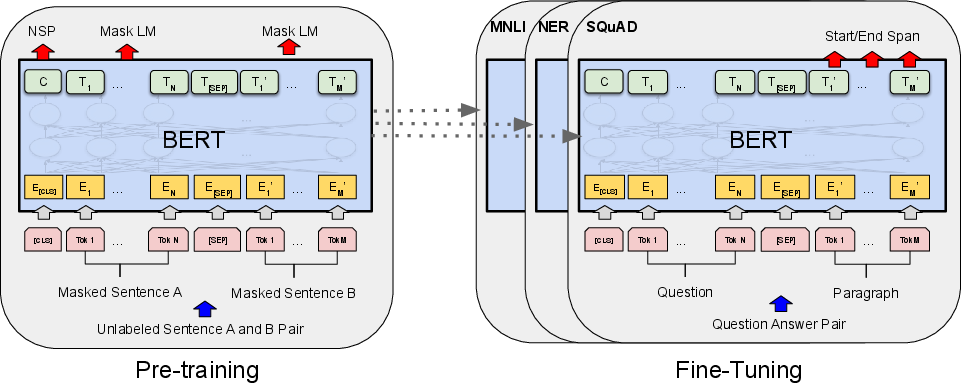
Figure 2: Overall pre-training and fine-tuning procedures, highlighting the unified architecture across different tasks.
Experimental Results and Ablation Studies
The paper presents BERT fine-tuning results on 11 NLP tasks, demonstrating state-of-the-art performance on the GLUE benchmark, SQuAD v1.1, SQuAD v2.0, and SWAG datasets. Notably, BERT achieves a GLUE score of 80.5%, a MultiNLI accuracy of 86.7%, a SQuAD v1.1 Test F1 score of 93.2, and a SQuAD v2.0 Test F1 score of 83.1.
Ablation studies are conducted to evaluate the importance of different components of BERT, including the pre-training tasks and model size. The results indicate that both the MLM and NSP tasks contribute to the model's performance, and that larger models lead to strict accuracy improvements across various datasets. Additionally, the feature-based approach with BERT is shown to be effective, achieving competitive results on the CoNLL-2003 NER task.
Impact and Future Directions
The research demonstrates the significance of bidirectional pre-training for language representations, reducing the need for heavily engineered task-specific architectures. BERT's ability to achieve state-of-the-art performance on a broad range of NLP tasks highlights the effectiveness of deep bidirectional Transformers. Future research could explore further scaling of model size, investigating alternative pre-training objectives, and applying BERT to additional NLP tasks and modalities. The success of BERT has paved the way for numerous subsequent advancements in pre-trained LLMs, solidifying its impact on the field.