- The paper's main contribution is the use of factuality scores to dynamically calibrate trust in LLM-generated content.
- It employs a scenario-based study testing multiple design styles and granularities to enhance error validation and user experience.
- The study underscores the importance of interface flexibility and user training for effective human-LLM collaboration in real-world applications.
Facilitating Human-LLM Collaboration through Factuality Scores and Source Attributions
Introduction
The paper "Facilitating Human-LLM Collaboration through Factuality Scores and Source Attributions" addresses the challenges faced by users interacting with LLMs which are prone to generating hallucinations—factually incorrect information presented as truth. This research explores technical strategies, such as using factuality scores and source attributions, to improve user trust and collaboration with LLMs by effectively communicating the accuracy and origins of the model's responses.
Background and Motivation
LLMs, such as those in natural language processing tasks, often generate outputs not entirely faithful to the source data, leading to mistrust from users. Despite advancements in algorithmic techniques to identify and mitigate false content, effectively conveying this information to users remains a critical unsolved problem. The study by Do et al. investigates design strategies for representing factuality scores and source attributions with an end-user focus to enhance trust calibration and facilitate proper usage of AI-generated content.
Methodology
The researchers conducted a scenario-based study with 104 participants evaluating different design strategies for presenting LLM responses. The design strategies tested included:
- Highlight-all: Full color coding according to factuality.
- Highlight-threshold: Highlighting only below-threshold factuality scores.
- Score: Numerical and color-coded factuality scores with underlines.
These styles were examined at two linguistic granularities (word and phrase level).
- Source Attribution Styles:
- Reference numbers: Inline citations with the corresponding source.
- Highlight gradients: Source content importance marking.
The designs were tested for user trust, preference, and accuracy validation ease compared to a baseline with no markup.
Results and Analysis
Trust Ratings
All factuality design styles improved trust ratings over the baseline, with word-level granularities slightly outperforming phrase-level in fostering trust. The study noted significant trust calibration influences—the initial perceived accuracy significantly impacted subsequent trust adjustments when factuality scores were visible.
Participants who initially underestimated accuracy increased trust, while those who overestimated decreased trust upon exposure to factuality information.
Ease of Validation
Ease of validating the LLM response accuracy showed variations across designs. Highlight-threshold and highlight-all at word-level performed favorably compared to the baseline, facilitating better error detection and validation.
Preference
Participants generally preferred the highlight-all design at phrase-level granularity, viewed as a comprehensive overview of potential inaccuracies. Among source attribution methods, the reference number strategy was marginally preferred, attributed to clarity and structured referencing.
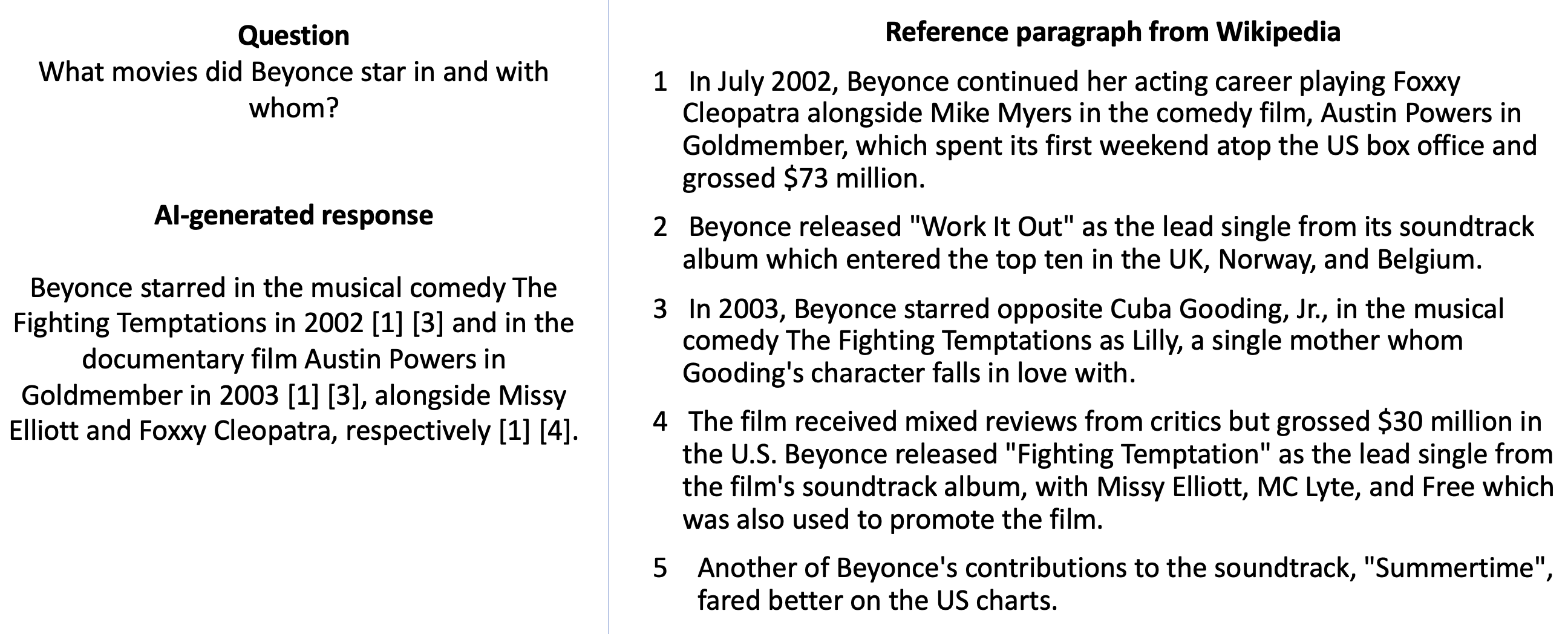
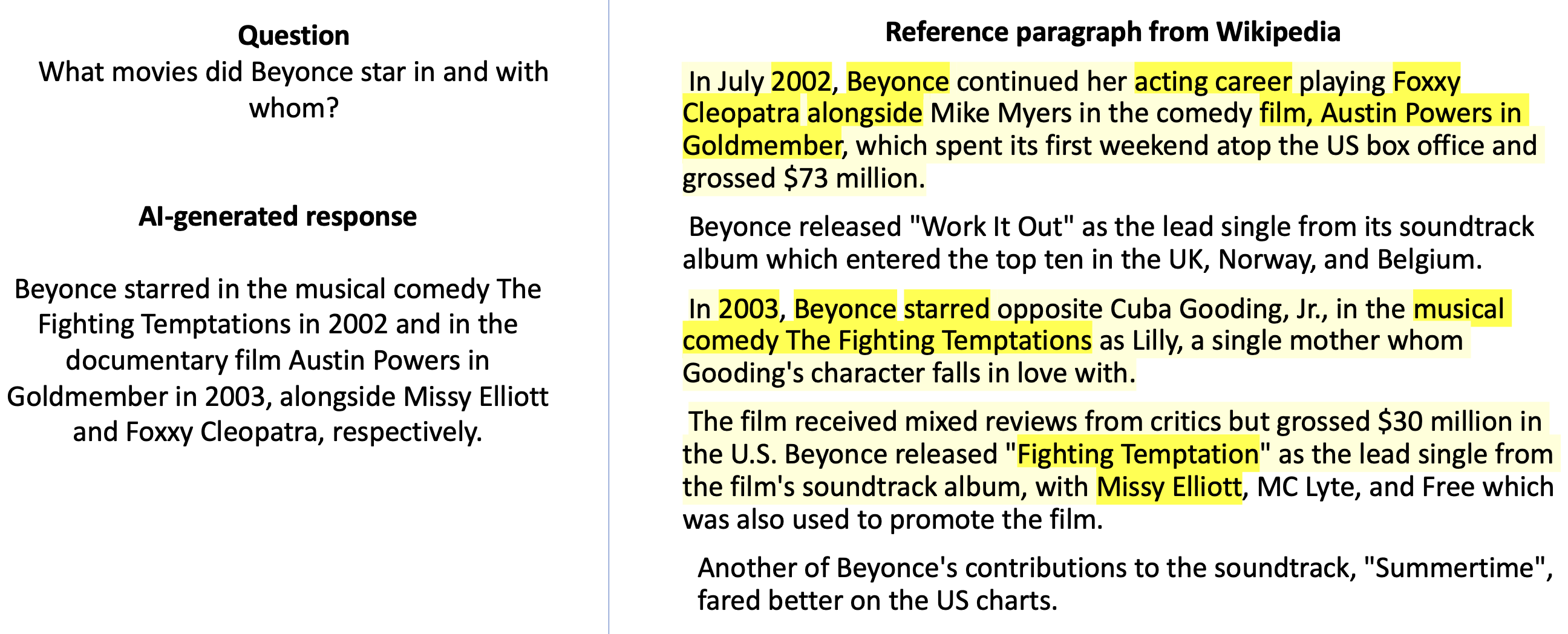
Figure 1: Reference numbers
Implications and Recommendations
The study presents several implications for designing LLM interfaces:
- Highlighting Factuality: The highlight-all style is recommended for addressing user trust and presenting factuality. For real-world applications, balancing comprehensive information with cognitive load is crucial.
- User Training: Trust calibration remains essential. Users must understand the potential inaccuracies in LLM outputs and rely on supplementary source attribution to verify content.
- Tools Flexibility: Interfaces should allow users to toggle highlighting options, adapting to user preferences and minimizing distraction during in-depth analyses.
Conclusion
This paper contributes significant insights into improving human-LLM interaction through strategic UI designs that communicate factuality and source information. Future research could explore these designs in different cultural and contextual settings or develop automated systems for dynamic adjustment based on user behavior and feedback. Through these strategies, the study empowers users to confidently, accurately, and responsibly interact with LLMs, enhancing AI's applicability in society.