- The paper introduces WorldLM, a federated learning framework that aggregates language model layers across autonomous federations.
- It employs attention-based personalized aggregation and residual sharing to mitigate challenges from legal, privacy, and data heterogeneity issues.
- Experimental results reveal up to a 1.91x improvement in perplexity over standard federated models, nearing centralized performance.
Worldwide Federated Training of LLMs
Introduction
The paper "Worldwide Federated Training of LLMs" (2405.14446) explores a novel federated learning framework aimed at training LLMs collaboratively on a global scale while accommodating distinct legal, privacy, and security requirements. Addressing the inherent challenges in standard federated learning such as statistical heterogeneity and constraints due to varying jurisdictional policies, the authors introduce a system named WorldLM, which builds on a federation of federations model. This system enables autonomous federations to locally aggregate model layers and facilitates cross-federation information sharing via residual layer embeddings. Such mechanisms are especially crucial given the privacy and heterogeneity concerns in handling language data in federated settings.
Federated Learning Challenges
Federated learning strives to integrate disparate data sets across diverse organizations, promising the optimization of LLMs without necessitating central data storage. However, this paper identifies critical issues inherent in scaling federated learning on a global scale. Legal and privacy challenges arise from different regulatory regimes, exemplified by requirements within the EU's General Data Protection Regulation (GDPR). There is also the amplified issue of data heterogeneity—where organizations manage data in various languages and domains (e.g., scientific versus general information). This variance can significantly impede model convergence, a problem exacerbated in federated learning settings where standard single-federation approaches often fall short.
WorldLM System Design
Federation Structure and Personalized Aggregation: The design of the WorldLM system (Figure 1) involves structuring federations to reflect relevant jurisdictional or sectoral boundaries. It implements a partially personalized aggregation scheme using attention mechanisms for hierarchical aggregation of model components. In this schema, models are partitioned into a generalized backbone trained utilizing federated strategies (e.g., FedAvg or FedOPT), and personalized key layers are aggregated attentively, optimizing performance for both local and global distributions.
Residual Information Sharing: The system further innovates through dynamic routing of residual parameters among federations. This feature addresses intra-federation heterogeneity, preventing divergence by efficiently routing and integrating parameters with a strong emphasis on cross-federation collaboration based on data similarities.
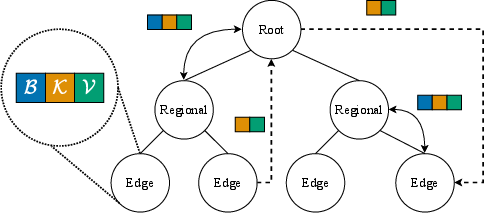
Figure 1: WorldLM federations exchange information in the form of models containing a backbone, personalized layers (B,K,V), and residual embeddings dynamically routed for attention-based aggregation.
Experimental Validation and Results
The empirical evaluation involves extensive tasks assessing WorldLM across distributed datasets such as The Pile and mC4. Strong quantitative results demonstrate its superiority in handling federated learning's challenges. On diverse datasets, WorldLM achieves up to 1.91 times improvement in perplexity over standard federated models and approaches the performance level of centralized models. The system's application also reveals robustness in the face of differential privacy protocols, exhibiting resilience where traditional federated models fall into divergence.
Figure 2: Data perspectives in hierarchical datasets constructed from The Pile, showing naturally heterogeneous groupings.
Practical and Theoretical Implications
WorldLM facilitates collaboration across geographical and regulatory divides, promising a transformative impact on the democratization of AI by harnessing underutilized data resources. The architecture's flexible aggregation strategy underscores the potential scalability of federated learning across diverse environments. The paper highlights future research opportunities to extrapolate WorldLM's advantages to larger-scale models and broader heterogeneities, potentially underpinning a shift in how LLMs are collaboratively developed on an international scale.
Conclusion
The "Worldwide Federated Training of LLMs" provides critical insights and methodologies to guide federated learning’s evolution in diverse, globally distributed environments. Its federations-of-federations approach offers tangible solutions to pressing data privacy and heterogeneity challenges while opening vistas for future computational paradigms. The scalable, privacy-compliant strategies outlined could very well pioneer future frameworks for ethically and effectively training large-scale LLMs across global datasets.