- The paper presents MUVO, a world model that integrates camera and lidar data to deliver high-resolution future predictions for autonomous driving.
- It employs a transformer-based encoder and a GRU-based transition model to fuse multimodal sensor inputs and generate detailed 3D occupancy grids, images, and point clouds.
- The model’s advanced sensor fusion and probabilistic predictions improve downstream planning while also revealing challenges in handling pedestrian detection and adverse conditions.
"MUVO: A Multimodal Generative World Model for Autonomous Driving with Geometric Representations" (2311.11762)
Introduction
The paper introduces MUVO, a Multimodal Generative World Model for autonomous driving, significantly advancing the domain by incorporating geometric representations using sensor-agnostic 3D voxel representations. By focusing on raw camera and lidar data, this work deviates from traditional methods that rely heavily on RGB images and often neglect the physical attributes of the environment. By integrating these multimodal inputs, MUVO aims to enhance prediction quality in both camera images and lidar point clouds, offering improvements for downstream tasks such as planning.

Figure 1: This example shows a high-resolution future prediction from MUVO for 3D occupancy and camera and lidar observations.
Methodology
The MUVO model is structured into three key stages: processing raw sensory inputs, modeling transitions, and decoding future states. First, high-resolution camera images and lidar point clouds are processed and fused using a transformer-based architecture to obtain latent representations. These representations are then fed into a transition model, where action-conditioned future states are predicted. Finally, the predicted states are decoded into 3D occupancy grids, raw RGB images, and point clouds, facilitating both geometric and sensor-specific interpretations.
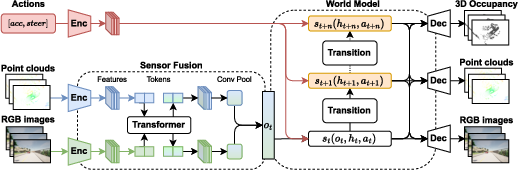
Figure 2: Overview of MUVO. Our model consists of three stages, from camera and lidar data processing, through a transition model to decoding into multimodal outputs.
The transition model uses a GRU-based deterministic historical state model, with probabilistic modeling for both posterior and prior states, enhancing future prediction capabilities through unsupervised learning. The 3D voxel decoder further allows for action-conditioned predictions, providing a detailed geometric representation of the world.
Sensor Fusion and Encoding
MUVO’s fusion mechanism relies on a transformer-based method to optimally integrate features from different sensor modalities, demonstrating superior performance over naive fusion approaches that merely average or concatenate features. The encoder processes high-resolution camera images and lidar data, with lidar being represented via range views, maximizing efficiency over point cloud voxelization techniques.

Figure 3: Predictions for lidar, camera, and 3D occupancy. Ground truth and decoded observations reveal the system's robust prediction capability.
Training and Evaluation
The paper details a robust training pipeline, leveraging data from simulated environments such as CARLA with varying weather conditions. The model was validated using metrics like PSNR for camera data, Chamfer Distance for lidar data, and IoU metrics for 3D occupancy grids. Through quantitative assessments, MUVO illustrated superior predictive power, especially in representing geometric details crucial for autonomous processes. Pre-training on camera and lidar data alone proved effective, enhancing both geometric representation quality and traditional sensor predictions.

Figure 4: Diverse Predictions: MUVO’s ability to forecast multiple plausible future scenarios, enhancing decision-making in dynamic environments.
Observed Cases and Challenges
Despite advancements, MUVO occasionally faced challenges such as missing predictions under certain circumstances, like pedestrian detection or blurred reconstructions in adverse conditions.

Figure 5: Observed failure cases: Examples include missing pedestrians, viewpoint mismatches, and blurred reconstructions.
Conclusion
MUVO represents a significant step forward in autonomous driving systems by integrating multimodal sensor data with geometric representations. The proposed generative model effectively predicts multiple scenarios, enhancing planning and decision-making. While aligning predictions with 3D occupancy data showcases the model's potential, future developments should aim to address observed limitations and scale training with real-world data to boost robustness and authenticity in dynamic settings.