- The paper introduces Pushdown Layers, an architectural innovation inspired by pushdown automata, to enable recursion handling in Transformer models.
- It integrates a stack-tape memory and attachment head to dynamically track token depths and build parse trees during language processing.
- Experimental results show that Pushdown Layers significantly improve syntactic generalization and sample efficiency on both synthetic and natural language datasets.
The paper "Pushdown Layers: Encoding Recursive Structure in Transformer LLMs" introduces a novel architectural feature for enhancing the handling of recursive structures in Transformer-based LMs. By incorporating pushdown automaton-inspired mechanisms, the proposed Pushdown Layers provide a memory augmentation strategy that maps structural manipulations in a LLM, thus enabling more efficient syntactic generalization.
Recursive State Modeling
Human languages exhibit recursive structures that are fundamental to syntactic constructs. While traditional neural sequence models like RNNs have explicit state-tracking to model recursion, Transformers rely on self-attention mechanisms without inherent state-memory capacities. This work integrates Pushdown Layers as a recursion-capable modification to Transformers. Pushdown Layers employ stack-tape memory to track token depths in parse trees, facilitating context-based recursive computations.
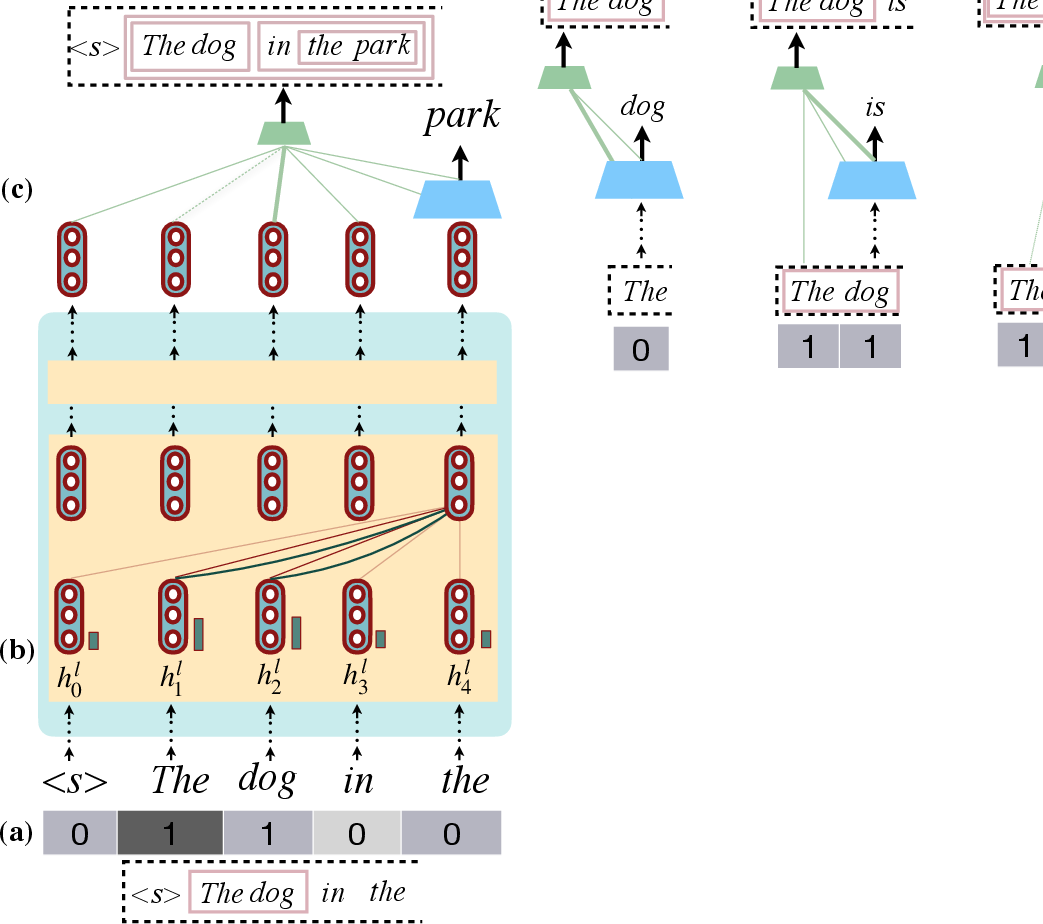
Figure 1: Pushdown Layers model recursive states using a stack-tape for token depth tracking, biasing attention towards recursive syntactic computations.
Implementation of Pushdown Layers
Architecture
Pushdown Layers act as a drop-in replacement for standard self-attention layers. They comprise:
- Stack Tape: This memory mechanism stores and updates token depths during parsing, simulating a pushdown automaton's operations.
- Attachment Head: Predicts attachment operations, influencing stack tape updates based on token predictions. Attachment decisions are modulated through self-attention to select parse constituents for combining new tokens.
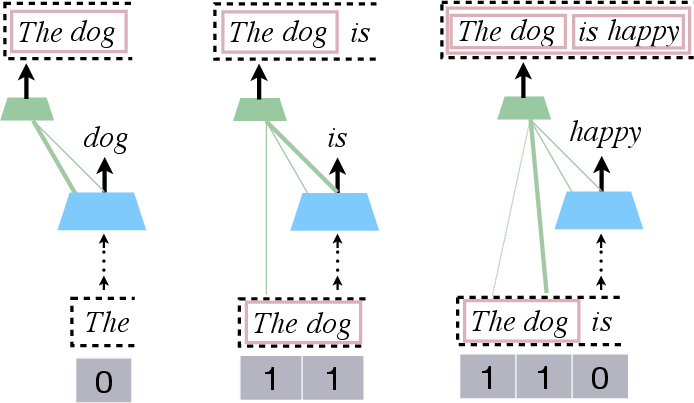
Figure 2: Demonstration of parse building via stack-tape updates in Pushdown LMs, where attention mechanisms drive attachment decisions.
Computational Considerations
Integrating Pushdown Layers in a Transformer involves a shift from 2D matrix operations to 3D, slightly impacting memory but maintaining FLOP equivalence. The added memory footprint stems from storing depth-augmented key tensors for attention computations.
Training and Inference
Models utilize joint learning of word predictions and attachment operations during training, paralleling standard LMs in data processing. During inference, structures are updated dynamically, employing beam search to navigate the combinatorial parsing possibilities and generate parse trees.
Experimentation and Results
Synthetic and Natural Language Evaluation
Experiments encompassed formal languages like Dyck and real language datasets, such as BLLIP-lg and a novel "WikiTrees" corpus. Pushdown Layers demonstrated superior generalization on recursive structures with significantly reduced data requirements compared to baseline LMs.
Sample Efficiency
Pushdown LMs exhibited a dramatic reduction in data dependency for syntactic generalization. For instance, syntactic abilities of Pushdown-LMs were achieved with considerably lesser training examples compared to standard LMs.
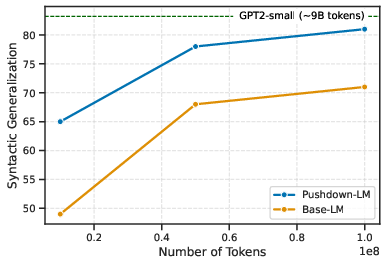
Figure 3: Pushdown Layers improve sample efficiency in syntactic generalization over multiple datasets.
Syntactic Language Modeling
The paper measured syntactic generalization through controlled experiments on tasks like subject-verb agreement, showing Pushdown-LMs outperform standard models significantly, particularly in confounding contexts.
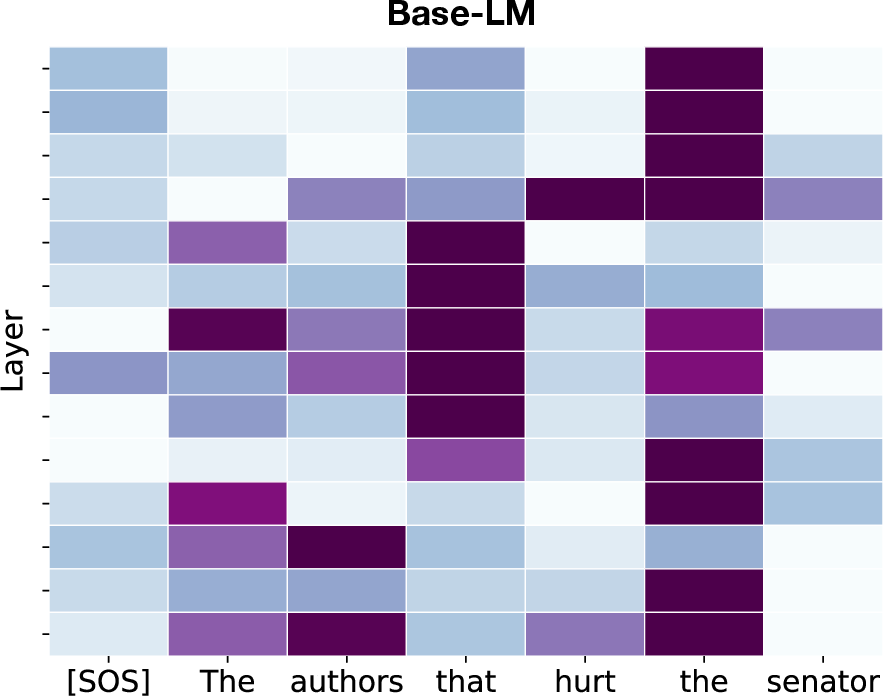
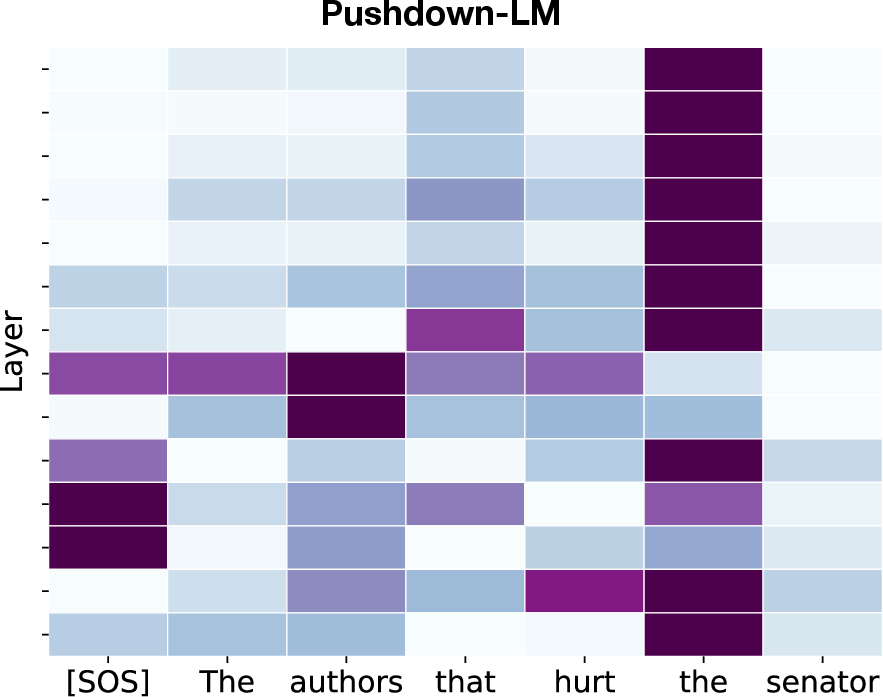
Figure 4: Attention maps show Pushdown-LM's focus shift away from distractor nouns to maintain subject-verb agreement.
Implications and Future Work
Pushdown Layers represent a step toward embedding explicit structural biases within neural LMs, targeting recursive phenomena. This development has the potential to expand syntactic learning in low-resource scenarios, augment semantic parsing in NLP applications, and provide a template for extending formal language understanding capacities in neural architectures.
Upcoming directions include exploring unsupervised structural bias learning, extending syntactic scaffolds to domains beyond natural language, and integrating non-constituency parsing like dependency structures into the framework.
Conclusion
Pushdown Layers enhance Transformer LMs by embedding recursive structure processing capabilities, achieving syntactic generalization and syntactic memory efficiency. Through this approach, the paper expands the applicability and robustness of Transformers in modeling linguistically-intricate data.