Prototype-based Aleatoric Uncertainty Quantification for Cross-modal Retrieval
Abstract: Cross-modal Retrieval methods build similarity relations between vision and language modalities by jointly learning a common representation space. However, the predictions are often unreliable due to the Aleatoric uncertainty, which is induced by low-quality data, e.g., corrupt images, fast-paced videos, and non-detailed texts. In this paper, we propose a novel Prototype-based Aleatoric Uncertainty Quantification (PAU) framework to provide trustworthy predictions by quantifying the uncertainty arisen from the inherent data ambiguity. Concretely, we first construct a set of various learnable prototypes for each modality to represent the entire semantics subspace. Then Dempster-Shafer Theory and Subjective Logic Theory are utilized to build an evidential theoretical framework by associating evidence with Dirichlet Distribution parameters. The PAU model induces accurate uncertainty and reliable predictions for cross-modal retrieval. Extensive experiments are performed on four major benchmark datasets of MSR-VTT, MSVD, DiDeMo, and MS-COCO, demonstrating the effectiveness of our method. The code is accessible at https://github.com/leolee99/PAU.
- VATT: transformers for multimodal self-supervised learning from raw video, audio and text. In NeurIPS, pages 24206–24221, 2021.
- Bottom-up and top-down attention for image captioning and visual question answering. In CVPR, pages 6077–6086, 2018.
- Frozen in time: A joint video and image encoder for end-to-end retrieval. In ICCV, pages 1708–1718, 2021a.
- Frozen in time: A joint video and image encoder for end-to-end retrieval. In ICCV, pages 1708–1718, 2021b.
- Variational dropout and the local reparameterization trick. In NeurIPS, pages 2575–2583, 2015.
- Weight uncertainty in neural network. In ICML, volume 37, pages 1613–1622, 2015.
- Collecting highly parallel data for paraphrase evaluation. In ACL, pages 190–200, 2011.
- Learning the best pooling strategy for visual semantic embedding. In CVPR, pages 15789–15798, 2021.
- Fine-grained video-text retrieval with hierarchical graph reasoning. In CVPR, pages 10635–10644, 2020.
- S. Chun. Improved probabilistic image-text representations. arXiv preprint arXiv:2305.18171, 2023.
- Probabilistic embeddings for cross-modal retrieval. In CVPR, pages 8415–8424, 2021.
- A. P. Dempster. A generalization of bayesian inference. Journal of the Royal Statistical Society: Series B (Methodological), 30(2):205–232, 1968.
- Similarity reasoning and filtration for image-text matching. In AAAI, pages 1218–1226, 2021.
- R. Durrett. Probability: theory and examples, volume 49. Cambridge university press, 2019.
- MDMMT: multidomain multimodal transformer for video retrieval. In CVPR Workshops, pages 3354–3363, 2021.
- A new metric for probability distributions. IEEE Trans. Inf. Theory, 49(7):1858–1860, 2003.
- VSE++: improving visual-semantic embeddings with hard negatives. In BMVC, page 12, 2018.
- Clip2video: Mastering video-text retrieval via image CLIP. CoRR, abs/2106.11097, 2021.
- Multi-modal transformer for video retrieval. In ECCV, volume 12349, pages 214–229, 2020a.
- Multi-modal transformer for video retrieval. In ECCV, volume 12349, pages 214–229, 2020b.
- Y. Gal and Z. Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In ICML, volume 48, pages 1050–1059, 2016.
- CLIP2TV: an empirical study on transformer-based methods for video-text retrieval. CoRR, abs/2111.05610, 2021.
- MILES: visual BERT pre-training with injected language semantics for video-text retrieval. In ECCV, volume 13695, pages 691–708, 2022.
- X. Glorot and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. In AISTATS, pages 249–256, 2010.
- Improving image-sentence embeddings using large weakly annotated photo collections. In ECCV, volume 8692, pages 529–545, 2014.
- X-pool: Cross-modal language-video attention for text-video retrieval. In CVPR, pages 4996–5005, 2022.
- Trusted multi-view classification. In ICLR, 2021.
- Canonical correlation analysis: An overview with application to learning methods. Neural Comput., 16(12):2639–2664, 2004.
- Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, pages 1026–1034, 2015.
- Localizing moments in video with natural language. In ICCV, pages 5804–5813, 2017.
- D. Hendrycks and T. G. Dietterich. Benchmarking neural network robustness to common corruptions and perturbations. In ICLR, 2019.
- S. C. Hora. Aleatory and epistemic uncertainty in probability elicitation with an example from hazardous waste management. Reliability Engineering & System Safety, 54(2-3):217–223, 1996.
- E. T. Jaynes. Information theory and statistical mechanics. Physical review, 106(4):620, 1957.
- Densecap: Fully convolutional localization networks for dense captioning. In CVPR, pages 4565–4574, 2016.
- A. Jøsang. Subjective logic, volume 4. Springer, 2016.
- A. Karpathy and L. Fei-Fei. Deep visual-semantic alignments for generating image descriptions. IEEE Trans. Pattern Anal. Mach. Intell., 39(4):664–676, 2017.
- Improving cross-modal retrieval with set of diverse embeddings. In CVPR, pages 23422–23431, 2023.
- D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In Y. Bengio and Y. LeCun, editors, ICLR, 2015.
- Fisher vectors derived from hybrid gaussian-laplacian mixture models for image annotation. CoRR, abs/1411.7399, 2014.
- A probabilistic u-net for segmentation of ambiguous images. In NeurIPS, pages 6965–6975, 2018.
- Simple and scalable predictive uncertainty estimation using deep ensembles. In NeurIPS, pages 6402–6413, 2017.
- Less is more: Clipbert for video-and-language learning via sparse sampling. In CVPR, pages 7331–7341, 2021.
- A differentiable semantic metric approximation in probabilistic embedding for cross-modal retrieval. In NeurIPS, volume 35, pages 11934–11946, 2022.
- Panoptic scene graph generation with semantics-prototype learning. CoRR, abs/2307.15567, 2023.
- Microsoft COCO: common objects in context. In ECCV, volume 8693, pages 740–755, 2014.
- Use what you have: Video retrieval using representations from collaborative experts. In BMVC, page 279, 2019.
- I. Loshchilov and F. Hutter. SGDR: stochastic gradient descent with warm restarts. In ICLR, 2017.
- I. Loshchilov and F. Hutter. Decoupled weight decay regularization. In ICLR, 2019.
- Clip4clip: An empirical study of CLIP for end to end video clip retrieval and captioning. Neurocomputing, 508:293–304, 2022.
- D. J. C. Mackay. Bayesian methods for adaptive models. California Institute of Technology, 1992.
- Variational dropout sparsifies deep neural networks. In ICML, volume 70, pages 2498–2507, 2017.
- R. M. Neal. Bayesian learning for neural networks, volume 118. Springer Science & Business Media, 2012.
- A straightforward framework for video retrieval using CLIP. In MCPR, volume 12725 of Lecture Notes in Computer Science, pages 3–12, 2021.
- Learning transferable visual models from natural language supervision. In ICML, volume 139, pages 8748–8763, 2021.
- Black box variational inference. In AISTATS, volume 33, pages 814–822, 2014.
- Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. In ICLR, 2014.
- Evidential deep learning to quantify classification uncertainty. In NeurIPS, pages 3183–3193, 2018.
- G. Shafer. A mathematical theory of evidence, volume 42. Princeton university press, 1976.
- C. E. Shannon. A mathematical theory of communication. ACM SIGMOBILE Mob. Comput. Commun. Rev., 5(1):3–55, 2001.
- Y. Song and M. Soleymani. Polysemous visual-semantic embedding for cross-modal retrieval. In CVPR, pages 1979–1988, 2019.
- Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res., 15(1):1929–1958, 2014.
- MSR-VTT: A large video description dataset for bridging video and language. In CVPR, pages 5288–5296, 2016.
- Attngan: Fine-grained text to image generation with attentional generative adversarial networks. In CVPR, pages 1316–1324, 2018.
- Conceptual and syntactical cross-modal alignment with cross-level consistency for image-text matching. In ACM MM, pages 2205–2213, 2021.
- Negative-aware attention framework for image-text matching. In CVPR, pages 15640–15649, 2022.
- Centerclip: Token clustering for efficient text-video retrieval. In SIGIR, pages 970–981, 2022.
- Complementarity-aware space learning for video-text retrieval. IEEE Trans. Circuits Syst. Video Technol., 33(8):4362–4374, 2023.
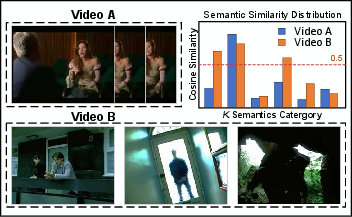
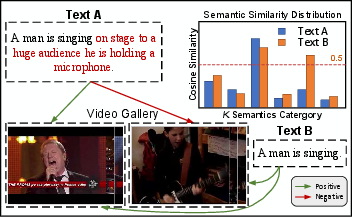
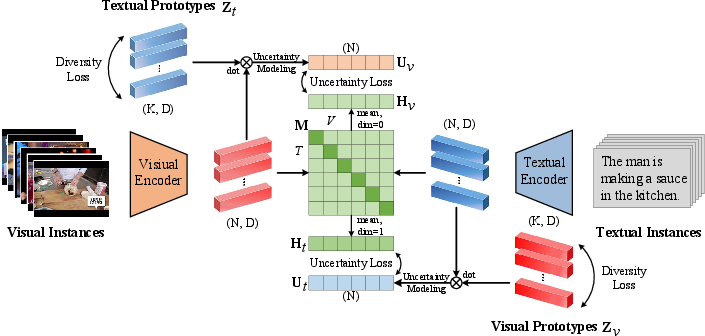

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.