Revisiting Energy Based Models as Policies: Ranking Noise Contrastive Estimation and Interpolating Energy Models
Abstract: A crucial design decision for any robot learning pipeline is the choice of policy representation: what type of model should be used to generate the next set of robot actions? Owing to the inherent multi-modal nature of many robotic tasks, combined with the recent successes in generative modeling, researchers have turned to state-of-the-art probabilistic models such as diffusion models for policy representation. In this work, we revisit the choice of energy-based models (EBM) as a policy class. We show that the prevailing folklore -- that energy models in high dimensional continuous spaces are impractical to train -- is false. We develop a practical training objective and algorithm for energy models which combines several key ingredients: (i) ranking noise contrastive estimation (R-NCE), (ii) learnable negative samplers, and (iii) non-adversarial joint training. We prove that our proposed objective function is asymptotically consistent and quantify its limiting variance. On the other hand, we show that the Implicit Behavior Cloning (IBC) objective is actually biased even at the population level, providing a mathematical explanation for the poor performance of IBC trained energy policies in several independent follow-up works. We further extend our algorithm to learn a continuous stochastic process that bridges noise and data, modeling this process with a family of EBMs indexed by scale variable. In doing so, we demonstrate that the core idea behind recent progress in generative modeling is actually compatible with EBMs. Altogether, our proposed training algorithms enable us to train energy-based models as policies which compete with -- and even outperform -- diffusion models and other state-of-the-art approaches in several challenging multi-modal benchmarks: obstacle avoidance path planning and contact-rich block pushing.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of gaps and open questions that remain unresolved and could guide future research:
- Model misspecification: All core guarantees (optimality, consistency, asymptotic normality) assume realizability/identifiability (the true conditional density is in the EBM class). What happens under misspecification? Can we characterize convergence targets, error decomposition, and robustness when ?
- Assumption strength and verifiability: The analysis relies on compactness of measure spaces, regular conditional distributions, uniform integrability, and continuity with dominated convergence. These are strong and nontrivial to verify for neural EBMs; practical conditions or weaker assumptions that still yield guarantees are not provided.
- Negative sampler convergence: Asymptotic normality requires the learned negative sampler parameters to be -consistent to a fixed point. Under joint training, what conditions on architectures, losses, and optimization ensure this rate? Are there cases where joint training fails to achieve the required consistency?
- Finite-sample behavior: Beyond asymptotics, there are no finite-sample generalization bounds, variance/bias analyses, or sample complexity guarantees for R-NCE with learned negative samplers, especially as a function of , the sampler quality, and energy model capacity.
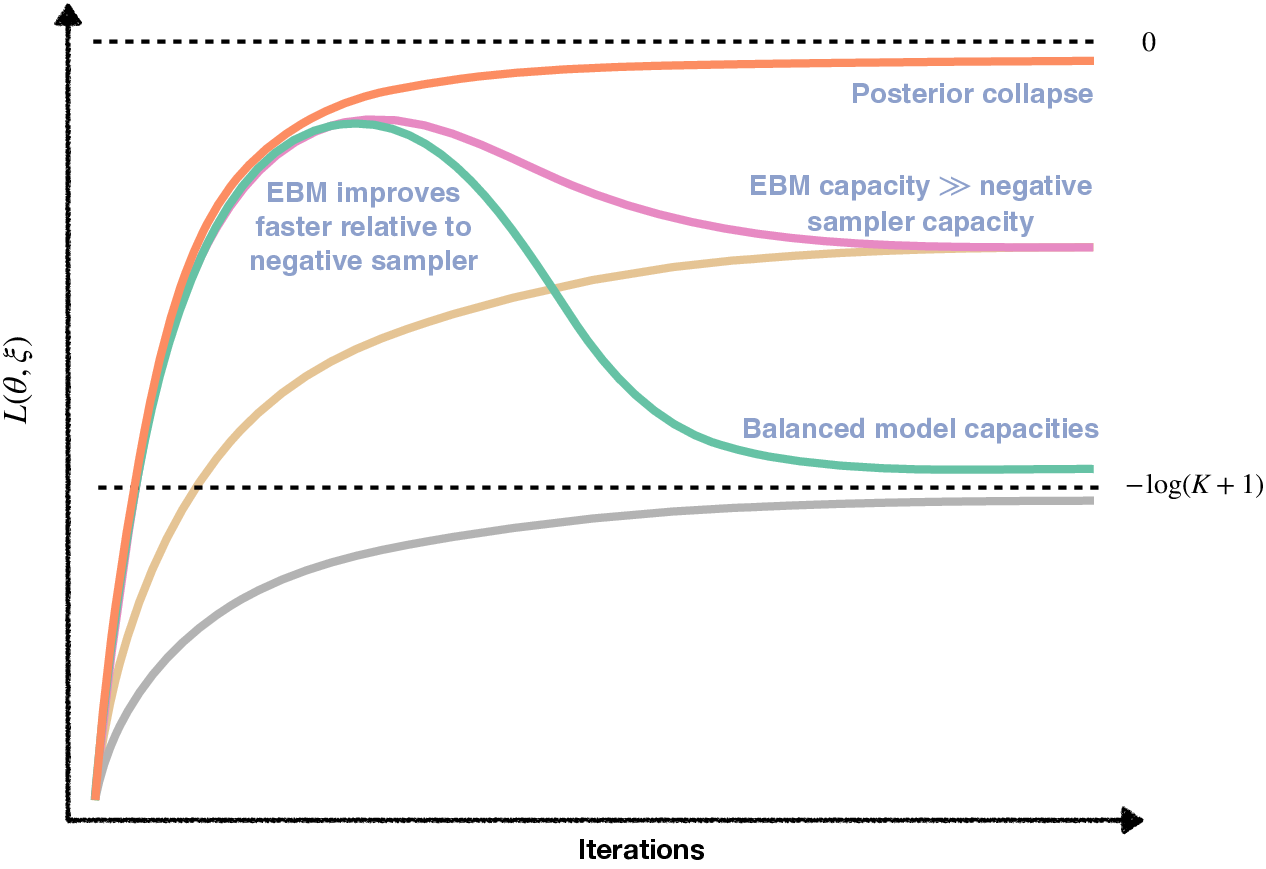
- Posterior collapse formalization: While gradient collapse is identified when the negative sampler is too weak, there is no formal criterion to detect it during training nor principled mitigation strategies (e.g., adaptive hard-negative mining, curriculum on , contrastive reweighting).
- Optimal design of the negative sampler: The paper sketches the idea of “nearly asymptotically efficient” samplers (and begins to define conditional Fisher information) but does not complete a design methodology. How should and be chosen to minimize the asymptotic variance or optimize optimization conditioning in practice?
- Impact of (number of negatives): Theoretical and empirical guidance for choosing is missing. How do and its schedule affect optimization stability, estimator variance, and compute/memory trade-offs?
- Joint training dynamics: Non-adversarial joint training is proposed, but there is no theory guaranteeing avoidance of mode collapse or degenerate equilibria. Under what conditions (loss coupling, update ratios, architectures) is training provably stable?
- IBC bias quantification: The paper proves that IBC is biased (towards modeling the density ratio ) but does not quantify the bias magnitude for realistic , nor explore correction strategies beyond adopting R-NCE (e.g., reweighting, alternative priors, improved contrastive setups).
- MCMC correctness and efficiency: Inference relies on warm-started Langevin/HMC from the learned sampler, yet there are no mixing-time analyses, convergence guarantees, or diagnostics. What are the failure modes in multimodal energy landscapes, and when is an accept-reject correction (e.g., Metropolis-adjusted Langevin) necessary to avoid sampling bias?
- Energy-to-action selection: The paper emphasizes EBMs’ implicit action selection via energy minimization but does not compare or analyze optimization-based selection (MAP) versus sampling-based selection in terms of safety, latency, and performance, nor provide guarantees under constraints.
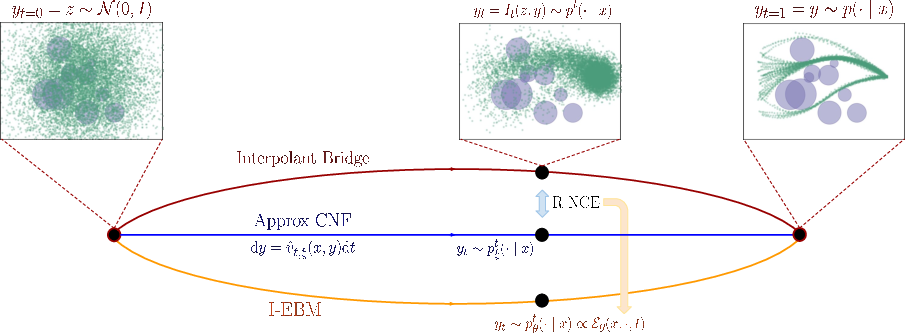
- Multi-scale “interpolating EBMs”: The proposed scale-indexed EBM family is motivated by diffusion-like multi-noise training, but key questions remain: how to select noise schedules, ensure cross-scale consistency/identifiability, couple losses across scales, and design sampling schemes that traverse scales with guarantees.
- Coverage and support issues: There is no analysis of what happens when the negative sampler does not adequately cover the support of (common in high-dimensional actions), nor mechanisms to diagnose/expand coverage (e.g., tempered proposals, mixture samplers).
- Scalability to high-dimensional, long-horizon settings: Experiments focus on obstacle avoidance and block pushing. It remains unclear how the approach scales to very high-dimensional actions (dexterous hands), long-horizon sequential decision-making (trajectory EBMs), or partially observable settings, and how to extend theory to sequence models.
- Safety and distribution shift: The paper does not address robustness under covariate shift, out-of-distribution contexts, or safety constraints common in real robots, nor propose uncertainty calibration or risk-aware planning mechanisms for EBMs.
- Compositionality and priors: EBMs are claimed to enable straightforward composition and prior incorporation, but there is no formal framework or empirical demonstration (e.g., how to compose task constraints, safety priors, or multiple skills without pathological interactions).
- Discrete/hybrid action spaces and non-Euclidean domains: The sampling and analysis focus on Euclidean . Extensions to discrete, hybrid, or manifold-valued action spaces (and their samplers) are not developed.
- Hyperparameter sensitivity and architecture choices: Practical guidance is missing for selecting sampler architecture (normalizing flows vs. stochastic interpolants), energy model capacity, optimization hyperparameters (step sizes, update ratios), and their impact on stability and performance.
- Normalization and calibration: EBMs trained via R-NCE avoid partition function estimation during training, but there is no guidance for calibrating probabilities (e.g., for risk-aware policies) or estimating partition functions when needed.
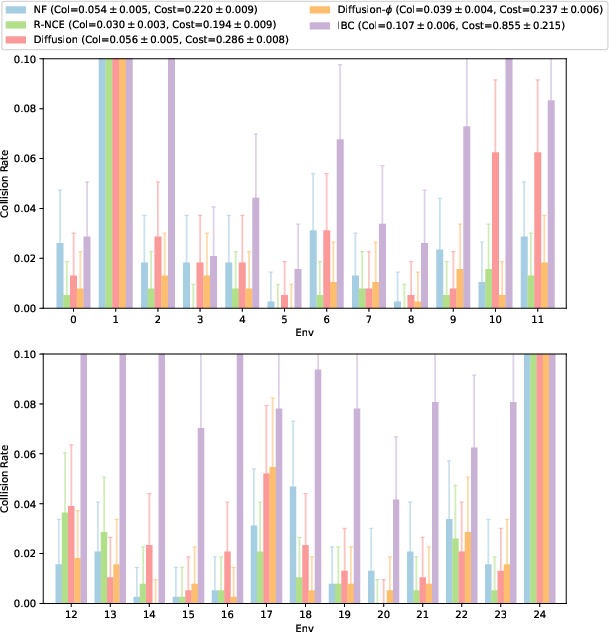
- Comparative evaluation: Claims of outperforming diffusion policies are promising, yet broader evaluations are needed (more tasks, real hardware, multiple seeds, compute budgets, inference latency, ablations for K, sampler choice, and MCMC settings) to validate generality and practical advantages.
Glossary
- Adversarial optimization: Min-max training setup where models are optimized in opposition, often unstable without careful design. Example: "Unfortunately, adversarial optimization is notoriously challenging and requires several stabilization tricks to prevent mode-collapse"
- Asymptotic consistency: Property that an estimator converges to the true parameter as the number of samples grows. Example: "We prove that our proposed objective function is asymptotically consistent and quantify its limiting variance."
- Asymptotic normality: Property that an estimator’s scaled error converges in distribution to a normal distribution as sample size increases. Example: "preserving the asymptotic normality properties of R-NCE."
- Block-diagonal Hessian: A Hessian matrix whose off-diagonal blocks are zero, implying parameter decoupling in second-order curvature. Example: "This implies that the joint Hessian ∇2_γ L(θ⋆, ξ⋆) is block-diagonal, yielding the necessary simplification."
- Continuous normalizing flows: Generative models that use continuous-time invertible transformations to model complex distributions. Example: "for non-trivial backbone models (e.g., continuous normalizing flows~\cite{chen2018neural}) yields a non-negligible computational overhead."
- Diffusion models: Generative models that learn to reverse a noise-adding process to sample from complex data distributions. Example: "Due to the recent advances in diffusion models across a wide variety of domains"
- Energy-based models (EBMs): Models that define a scalar energy function over inputs; densities are proportional to the exponential of negative energy. Example: "Energy-based models have a number of appealing properties in the context of robotics."
- Exponential tilting: Adjusting a base distribution by multiplying by an exponential of a function to reweight probabilities. Example: "commonly referred to as exponential tilting."
- Generative Adversarial Networks (GANs): Framework where a generator and discriminator are trained adversarially to produce realistic samples. Example: "drawing a natural analogy with Generative Adversarial Networks (GANs)."
- Hamiltonian Monte Carlo (HMC): MCMC method that uses Hamiltonian dynamics to propose distant moves with high acceptance rates. Example: "Hamiltonian Monte Carlo (HMC) leapfrog integration steps"
- Hessian: Matrix of second-order partial derivatives indicating local curvature of an objective function. Example: "The Hessian of \bar{\ell}_{\gamma} is Lipschitz-continuous"
- Identifiability: A model property where the true parameter is uniquely determined by the distribution. Example: "If Θ_\star is a singleton, we say that F is identifiable."
- Implicit Behavior Cloning (IBC): Contrastive objective for training EBMs as policies, shown here to be biased at the population level. Example: "the Implicit Behavior Cloning (IBC) objective is actually biased even at the population level"
- InfoNCE: Contrastive learning objective that lower-bounds mutual information; often used to train representation models. Example: "an InfoNCE~\cite{vandenOord2018_cpc} inspired objective"
- Langevin sampling: Stochastic gradient-based MCMC method using noisy gradient ascent on log-density. Example: "We outline the simplest possible MCMC implementation (Langevin sampling), however one may leverage any additional variations and tricks, including Hamiltonian Monte Carlo (HMC) and Metropolis-Hastings adjustments."
- Latent space: Low-dimensional space used by generative models to represent data; sampling and operations may be performed there. Example: "perform MCMC sampling within the latent space"
- Lebesgue Dominated Convergence theorem: A result ensuring interchange of limits and integrals under domination, used for asymptotic analysis. Example: "by the continuity of for a.e.\ and the Lebesgue Dominated Convergence theorem"
- Limiting variance: The variance that an estimator’s scaled error converges to asymptotically. Example: "quantify its limiting variance."
- Lipschitz-continuous: A function whose rate of change is bounded linearly by the change in input; used to control curvature behavior. Example: "The Hessian of \bar{\ell}_{\gamma} is Lipschitz-continuous"
- Markov Chain Monte Carlo (MCMC): Family of algorithms that sample from complex distributions by constructing a Markov chain with the target as its stationary distribution. Example: "This necessitates the use of expensive Markov Chain Monte Carlo (MCMC) techniques to estimate the gradient"
- Maximum Likelihood Estimation (MLE): Estimation method that chooses parameters maximizing the likelihood of observed data. Example: "maximum likelihood estimation (MLE)"
- Metropolis-Hastings: MCMC algorithm that accepts or rejects proposed moves based on an acceptance probability to ensure correct stationary distribution. Example: "Metropolis-Hastings adjustments."
- Mode-collapse: Failure mode in adversarial training where a generator produces limited variety of outputs. Example: "to prevent mode-collapse"
- Multi-modal: Distributions or tasks exhibiting multiple distinct high-probability regions or solutions. Example: "are inherently multi-modal"
- Negative proposal distribution: The distribution used to sample contrastive “negative” examples in NCE-style objectives. Example: "p_\xi(\cdot \mid x) is the negative proposal distribution."
- Negative sampler: A model that generates negative examples for contrastive training. Example: "(ii) learnable negative samplers, and (iii) non-adversarial joint training."
- Noise Contrastive Estimation (NCE): Technique that trains generative models by framing density estimation as a classification task against noise samples. Example: "maximum likelihood estimation (MLE) and noise contrastive estimation (NCE)."
- Normalizing flows: Generative models that transform a simple base distribution into a complex one via invertible mappings with tractable Jacobians. Example: "Some examples of models which satisfy these requirements include normalizing flows~\cite{grathwohl2018_ffjord} and stochastic interpolants~\cite{albergo2022building, albergo2023_stochastic_interpolants}."
- Partition function: Normalizing constant ensuring that an unnormalized density integrates to one; often intractable for EBMs. Example: "can be difficult to train due to the intractable computation of the partition function."
- Persistent chains: Long-running MCMC chains continued across training iterations to reduce bias in gradient estimates. Example: "A common heuristic involves using persistent chains"
- Posterior collapse: Training pathology where posterior probabilities concentrate on trivial solutions, flattening gradients. Example: "We term this phenomenon posterior collapse."
- Pullback: The distribution induced in latent space via inverse mapping from data space. Example: "using the pullback of the exponentially tilted distribution."
- Pushforward: The distribution obtained by mapping latent samples forward through a generative model. Example: "Pushing forward the samples from the latent space via the backbone model yields the necessary samples for defining the MLE objective."
- Ranking Noise Contrastive Estimation (R-NCE): NCE variant using a multi-class ranking objective, consistent for conditional models. Example: "ranking noise contrastive estimation (R-NCE)"
- Realizability: Existence of parameters within a model class that represent the true data-generating distribution. Example: "We say that F is realizable if"
- Score-based models: Generative models that learn gradients (scores) of log-densities instead of normalized densities. Example: "which is not possible with score-based models"
- Self-normalized: Property of a model where outputs are normalized implicitly, affecting consistency of certain objectives. Example: "consistency requires the EBM model class to be self-normalized."
- Stochastic interpolants: Generative modeling framework constructing time-indexed bridges between noise and data. Example: "stochastic interpolants~\cite{albergo2023_stochastic_interpolants,lipman2023_flow,liu2023_flow}"
- Stochastic process: A time-indexed collection of random variables, used here to bridge noise and data. Example: "learn a continuous stochastic process that bridges noise and data"
- Transport map: Function that deterministically moves probability mass from one distribution to another. Example: "which, for non-trivial backbone models (e.g., continuous normalizing flows~\cite{chen2018neural}) yields a non-negligible computational overhead." (context: "the transport map as well")
- Uniform Integrability: Technical condition ensuring controlled integrals under limits; used to guarantee convergence properties. Example: "[Uniform Integrability]"
- Variational approximations: Approximations that replace intractable objectives with tractable bounds via variational methods. Example: "variational approximations for the inner optimization."
- Variational lower bound: Lower bound on likelihood derived via variational methods, enabling tractable optimization. Example: "yields a variational lower bound and thus, a max-min optimization problem"
Collections
Sign up for free to add this paper to one or more collections.

