- The paper introduces Diffusion-Amortized MCMC to efficiently sample latent space EBMs, enhancing training stability and generation quality.
- It leverages denoising diffusion processes to replace long-run MCMC with a learnable neural sampler, reducing computational costs.
- Experiments on SVHN, CelebA, and CIFAR-10 show improved FID and MSE performance, demonstrating robust handling of complex generative tasks.
Learning Energy-Based Prior Model with Diffusion-Amortized MCMC
Introduction
The paper introduces a novel approach for improving latent space Energy-Based Models (EBMs), termed Energy-Based Prior Models, used in generative modeling. The focus is on ameliorating issues related to non-convergent short-run Markov Chain Monte Carlo (MCMC) sampling, which typically leads to suboptimal generation quality and training instability. The authors propose a Diffusion-Amortized MCMC (DAMC) method, designed to offer a more effective sampling strategy for learning latent Space EBMs.
Methodology
Diffusion-Amortized MCMC
The core contribution is the introduction of the DAMC method, which leverages a diffusion process for amortizing long-run MCMC sampling. This is inspired by the connection between MCMC sampling and denoising diffusion probabilistic models (DDPMs), where the noise prediction plays a similar role to the gradient of log density.
The DAMC approach involves iteratively distilling the MCMC process into a learnable neural sampler, effectively replacing expensive long-run simulations with computationally efficient amortized inference.
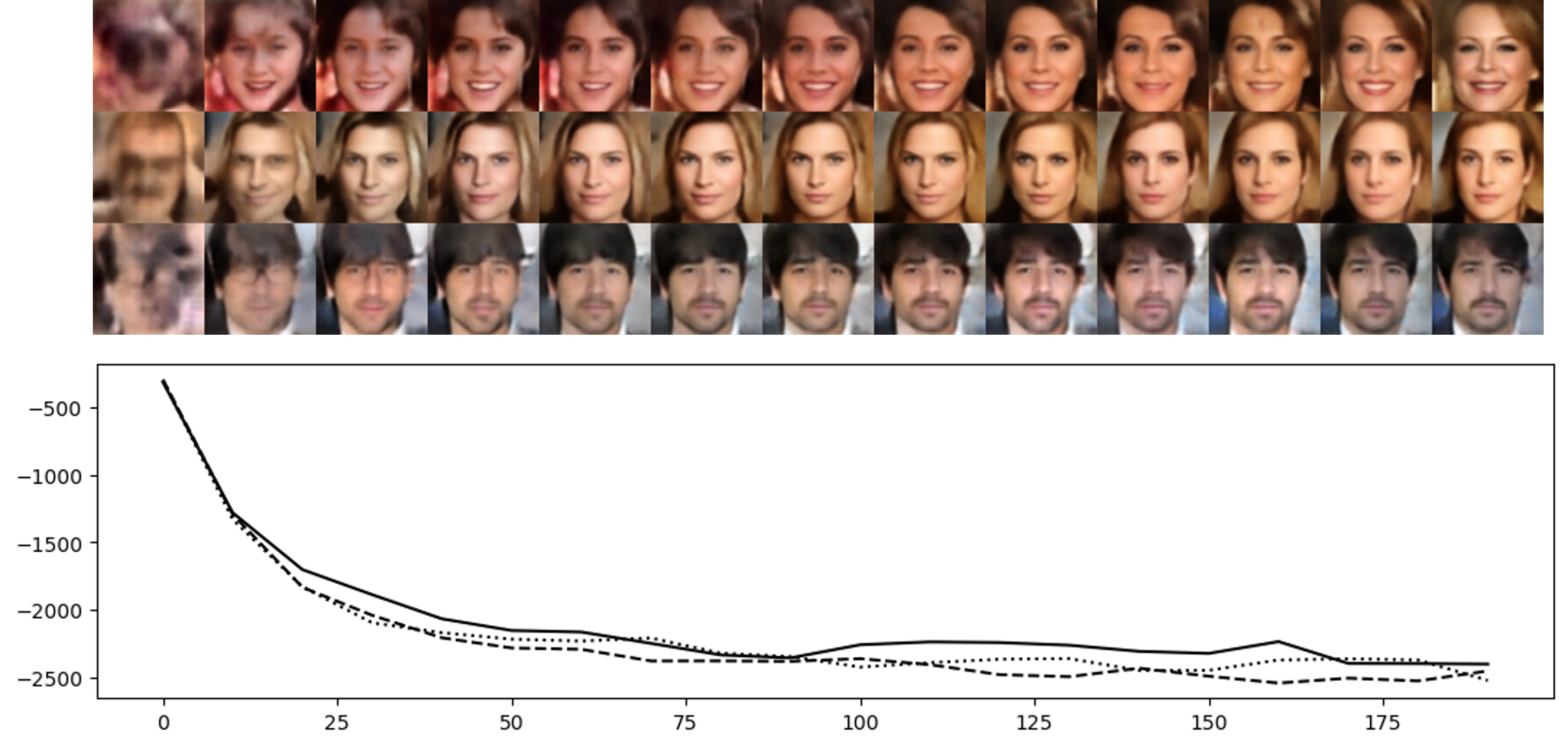
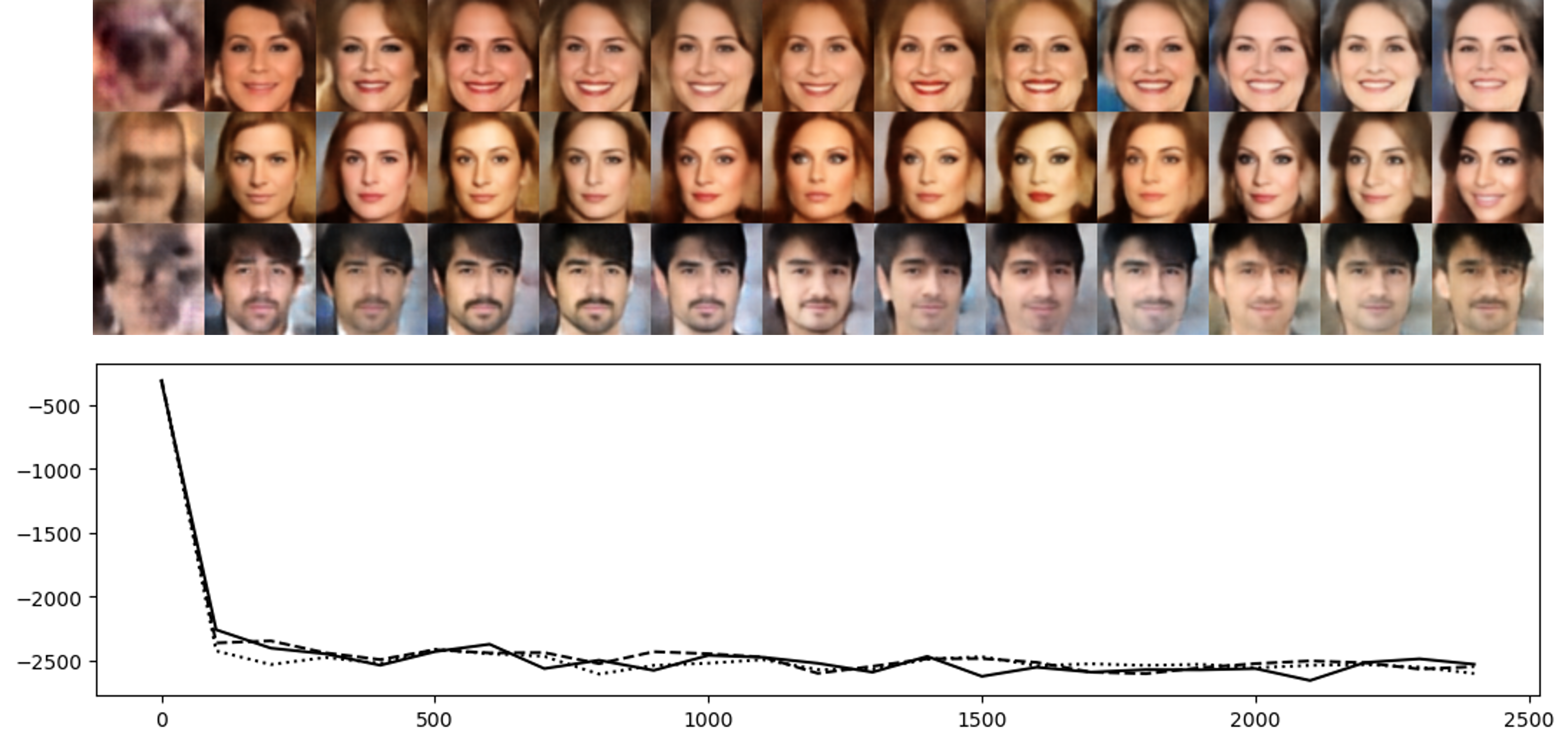
Figure 1: Transition of Markov chains initialized from N(0,Id) towards p(z).
Learning Algorithm
The learning algorithm integrates DAMC with Maximum Likelihood Estimation (MLE) for training latent space EBMs. The key steps include:
- Sampling: Using the current DAMC sampler to initialize short-run MCMC chains.
- Distillation: Iteratively refine the DAMC sampler to approximate the long-run MCMC distribution.
- Optimization: Utilizing gradient-based methods to update the parameters of the EBM and the DAMC sampler.
This iterative scheme ensures that both prior and posterior distributions are accurately represented, enhancing model expressivity and performance.
Experiments
The authors conduct experiments on several benchmark datasets, including SVHN, CelebA, and CIFAR-10. The results demonstrate that models trained with DAMC exhibit superior performance in terms of FID scores and mean squared error (MSE), validating the efficacy of the approach.




Figure 2: Samples generated from the DAMC sampler and LEBM.
The study also highlights the robustness of DAMC in handling high-dimensional and multi-modal distributions, showcasing its applicability to complex generative tasks.
Implications and Future Work
The integration of diffusion-based amortization in training EBMs presents significant advancements in generative modeling, particularly for applications requiring rich latent representations. The proposed method offers a scalable and efficient framework, potentially extendable to other forms of unnormalized continuous densities.
Future work could explore the application of DAMC to other domains involving latent variable models and extend the approach to concurrent learning of EBMs with other generative paradigms.
Conclusion
The paper successfully addresses longstanding challenges in sampling for latent space EBMs, providing both empirical and theoretical validation for the proposed DAMC approach. By marrying diffusion processes with MCMC techniques, the method paves the way for more effective and efficient generative model training.