- The paper introduces TaskLAMA, a novel dataset that benchmarks LLMs' ability to decompose complex tasks into context-driven steps with defined temporal dependencies.
- It employs innovative Hungarian matching metrics to evaluate both step generation and temporal ordering, addressing limitations of traditional precision measures.
- The study shows that while LLMs improve step generation by 15%-280%, they still struggle with accurately predicting the correct order of task steps.
Probing Complex Task Understanding with TaskLAMA
The paper "TaskLAMA: Probing the Complex Task Understanding of LLMs" (2308.15299) introduces a new dataset and methodology for evaluating the ability of LLMs to perform SCTD. This task involves breaking down complex, real-world tasks into a DAG of individual steps, with edges representing temporal dependencies. The authors highlight the importance of SCTD as a component of assistive planning tools and a challenge for commonsense reasoning systems. The paper presents TaskLAMA, a high-quality, human-annotated dataset, along with novel metrics designed for fair assessment of LLMs against several baselines.
TaskLAMA Dataset Construction
The TaskLAMA dataset comprises 1612 tasks, each annotated with:
- Contextual assumptions to provide a setting for the task.
- A set of required steps for completing the task under the specified context.
- Temporal dependencies between the steps, forming a task graph.
This resulted in a collection of 12118 steps and 11105 temporal dependencies. The complex tasks were sourced from the MSComplexTasks dataset and popular "How To" search queries. Annotators were instructed to provide steps in their own words, ensuring each step started with a verb, represented a single action, and was actionable within the given context. The dataset was split into training, validation, and test sets, with conceptual differences maintained across the sets to ensure a diverse evaluation.
Methodology for Task Graph Generation and Evaluation
The paper explores various strategies for generating task graphs using LLMs, focusing on two key aspects: generating the steps and determining the order dependencies. For step generation, the following approaches were evaluated: ICL, MultSeq, S{content}F, SPT, and combinations thereof. To transform the generated sequences into task graphs, several approaches were considered: Linear, ICL, ICL with CoT, SPT, and LLM Scoring.
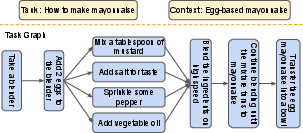
Figure 1: An example of a task graph for a complex task from the TaskLAMA dataset.
The evaluation metrics included standard measures like Rouge scores, but the authors identified a flaw in existing precision and recall metrics that could be exploited by simply adding duplicate sub-steps. To address this, they introduced metrics based on Hungarian matching to enforce a one-to-one mapping between generated and golden steps. They also reported a relaxed version of Hungarian matching allowing one-to-two mappings to account for cases where a single golden step might correspond to multiple generated steps. For edge evaluation, the paper introduces metrics like In-Degree, Out-Degree, and step proximity, all based on Rouge score overlap between parent and child nodes in the generated and ground truth graphs.
Results and Analysis
The study's findings indicate that LLMs excel at decomposing complex tasks into individual steps. Specifically, off-the-shelf LLMs demonstrated a 15%−280% relative improvement over the best baseline in step generation. Furthermore, the paper shows that LLMs can understand the context and adapt the generated steps accordingly. The performance with and without context is shown in (Figure 2).
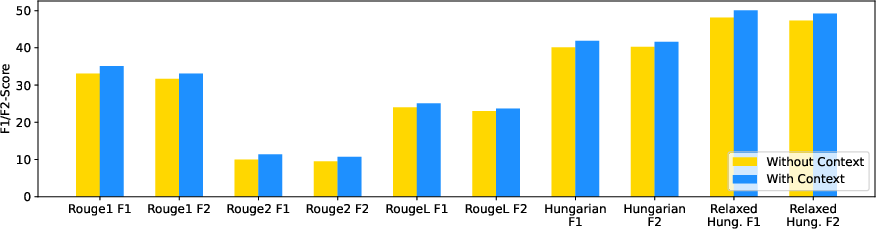
Figure 2: The model performance with and without the context provided as input.
However, the results also reveal a significant limitation: LLMs struggle to accurately predict pairwise temporal dependencies between steps. While they can generate good sequences of steps, their ability to determine the correct order remains unsatisfactory. The paper presents a qualitative analysis of LLM-generated task graphs, highlighting instances where the steps and dependencies are sensible, but also pointing out potential issues and inaccuracies. An example of the model outputs with and without the context provided to the model is shown in (Figure 3).

Figure 3: An example of model outputs for a task with and without the context provided as input to the model.
Implications and Future Directions
The research has notable implications for the development of AI-powered assistive planning tools. The TaskLAMA dataset and the proposed metrics provide a valuable resource for benchmarking and improving LLMs' ability to understand and decompose complex tasks. The finding that LLMs struggle with temporal dependency prediction highlights a critical area for future research. Potential avenues for improvement include:
- Developing new approaches to enhance LLMs' temporal reasoning abilities.
- Exploring methods for generating entire task graphs at once, rather than sequentially.
- Employing recursive decomposition strategies to break down complex tasks into simpler sub-tasks.
The paper concludes by acknowledging the limitations of the current work, such as the lack of conditional task graphs, the challenges of granularity in task graph generation, and the use of similarity-based metrics instead of entailment models. These limitations provide a clear roadmap for future research aimed at advancing the state-of-the-art in structured complex task decomposition.