- The paper introduces a framework that prioritizes training levels based on TD-error, establishing a self-discovered curriculum for reinforcement learning.
- It integrates a dynamic replay distribution and staleness measures with policy-gradient methods to enhance sample efficiency and prevent off-policy drift.
- Experimental evaluations on Procgen and MiniGrid environments demonstrated significant improvements in mean episodic returns over uniform sampling baselines.
Prioritized Level Replay
The paper "Prioritized Level Replay" presents a framework for improving the sample efficiency and generalization of reinforcement learning (RL) agents by exploiting varied learning potentials across training levels in procedurally generated environments. This approach, termed Prioritized Level Replay (PLR), selectively samples training levels based on their estimated potential to contribute to agent learning, as measured by temporal-difference (TD) errors.
Methodology
PLR leverages the inherent diversity within procedurally generated environments, utilizing the TD-error as a measure of a level's learning potential when revisited. The framework constructs a replay distribution that prioritizes levels based on these errors, allowing the agent to follow an emergent curriculum from simpler to more complex challenges.
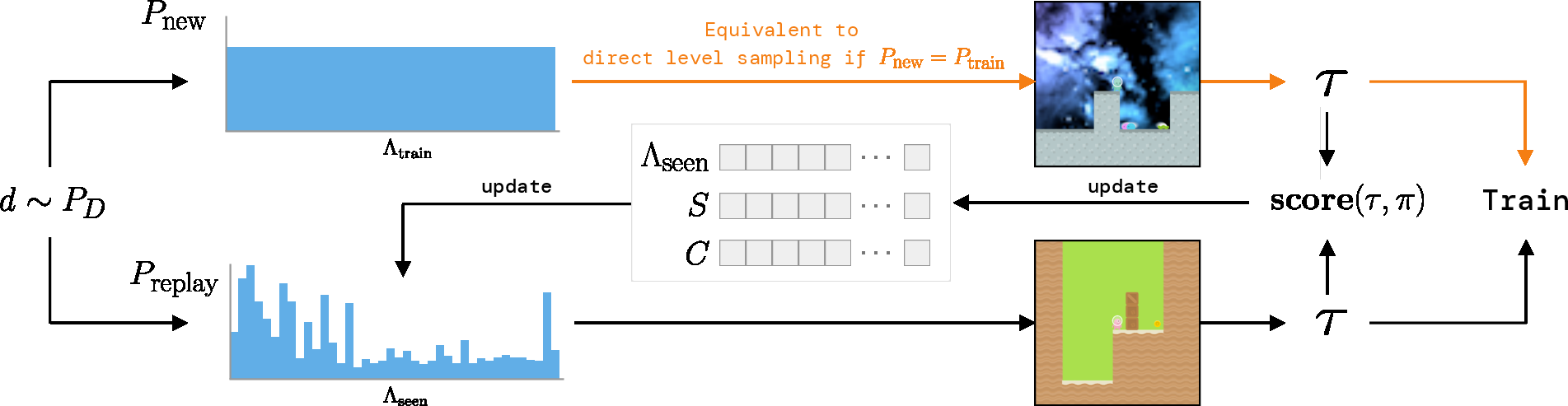
Figure 1: Overview of Prioritized Level Replay. The next level is either sampled from an unseen distribution or the prioritized replay distribution, with updates based on learning potential.
The algorithm computes a dynamic replay distribution, $P_{\text{replay}(l|\Lambda_{\text{seen})$, which combines level scores with a staleness measure to prevent off-policy drift. The prioritization function is defined by the absolute value of the Generalized Advantage Estimate (GAE), controlled by a temperature parameter β.
Implementation
The implementation proceeds by integrating PLR with policy-gradient methods like PPO. The level scores are updated during training based on TD-errors from observed trajectories, while staleness coefficients ensure levels are revisited appropriately to keep the agent's policy aligned with learning opportunities.
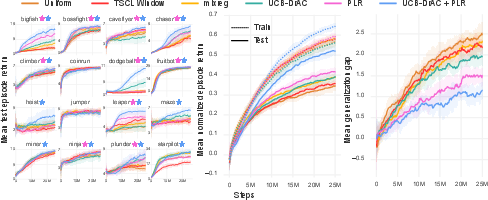
Figure 2: Mean episodic test returns illustrating statistically significant improvements in sample efficiency and performance over uniform sampling.
Experimental Evaluation
Experiments conducted across the Procgen Benchmark and MiniGrid environments show substantial improvements in test performance, validation of the self-discovered curriculum induced by PLR. PLR outperformed several baselines, including TSCL and uniform sampling, by a significant margin in terms of both sample efficiency and generalization capability.
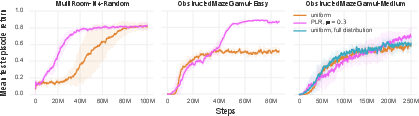

Figure 3: Demonstrates significant improvements in mean episodic returns with PLR across various environments.
The findings highlight that PLR effectively manages to reduce overfitting by refining the training distribution according to the agent's current capabilities, leading to more robust generalization on unseen test levels.
Discussion
Key outcomes from the experiments underscore PLR's efficacy in automatically generating a curriculum tailored to the agent's evolving proficiency, without explicit difficulty labels or additional environmental modifications. This effect is notably consistent across both continuous and discrete state spaces.
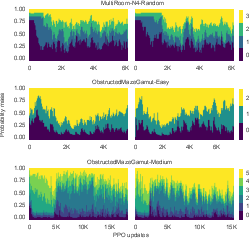
Figure 4: PLR consistently evolves emergent curricula, illustrating progressive adaptation to levels of increasing complexity.
Although PLR shows promise when extended to an unbounded set of levels, future work could explore integrating PLR with exploration strategies to further enhance its applicability to complex RL challenges, including those with sparse rewards.
Conclusion
Prioritized Level Replay demonstrates an advanced method for improving RL through selective level replay driven by learning potential, as evidenced by its increased generalization and efficiency across various procedurally generated environments. These insights pave the way for further explorations into curriculum learning and adaptive sampling techniques in RL.