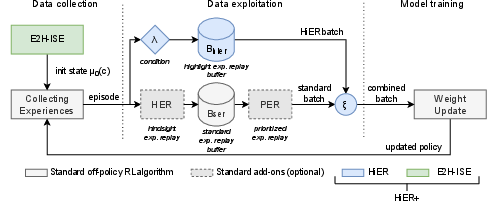
- The paper introduces HiER, which uses a secondary replay buffer to store high-impact transitions determined by a dynamic reward threshold.
- It incorporates E2H-ISE to adjust the initial state entropy, providing a curriculum that transitions from simple to complex tasks.
- The combined HiER+ framework achieves superior performance on robotic tasks, surpassing state-of-the-art baselines in success metrics.
HiER: Highlight Experience Replay for Boosting Off-Policy Reinforcement Learning Agents
The paper "HiER: Highlight Experience Replay for Boosting Off-Policy Reinforcement Learning Agents" introduces novel approaches to enhance off-policy reinforcement learning (RL) performance in challenging continuous control tasks, particularly within robotics, where environments often present sparse rewards and continuous state and action spaces. The paper presents three key contributions: Highlight Experience Replay (HiER), Easy2Hard Initial State Entropy (E2H-ISE), and their combination into HiER+. The subsequent sections elaborate on these methodologies, their implementation, evaluation, and findings.
HiER: Highlight Experience Replay
Highlight Experience Replay (HiER) addresses the challenge of sparse rewards by maintaining a secondary replay buffer dedicated to high-impact experiences. This serves as an automatic demonstration generator where only critical experiences, marked by achieving rewards beyond a certain threshold (λ), are stored.
HiER implementation involves:
- Secondary Buffer Management: Transition storage into Bhier occurs if the sum of rewards R=∑i=0Tri exceeds λ.
- Adaptive λ Modes:
- Fix: A constant threshold.
- Predefined: A linearly increasing threshold.
- Adaptive Moving Average (AMA): Threshold adapts based on historical rewards over a window size w.
Sampling Strategies:
E2H-ISE: Easy2Hard Initial State Entropy
E2H-ISE implements curriculum learning through adaptive manipulation of the initial state-goal distribution’s entropy, helping agents tackle tasks with a gradual increase in complexity.
- Entropy Management: μ0 transitions from deterministic (zero entropy) to maximally distributed (high entropy).
- Adaptation Techniques:
- Predefined: A linear profile with saturation.
- Self-Paced and Control: Dynamically modify cj based on recent success rates, aiming to balance between exploration and exploitation.
HiER+ Combination
HiER+ integrates HiER and E2H-ISE, enhancing learning adaptability and performance by using the advantages of both highlight retention and structured task difficulty adjustment.
- Overall Architecture: As described in Algorithm 1, HiER+ iteratively refines λ and c, facilitating a progressively demanding learning regime.
Experimental Results
Experiments were conducted on standardized robotic tasks within the panda-gym benchmark. HiER, E2H-ISE, and HiER+ configurations consistently outperformed state-of-the-art baselines, showing superior success rates across push, slide, and pick-and-place tasks.
- Performance Metrics: HiER+ achieved near-perfect success rates in complex tasks:
- Push Task: Mean success rate of 1.0
- Slide Task: Improved to 0.83 from baseline 0.38
- Pick-and-Place Task: Achieved 0.69 compared to a baseline of 0.27
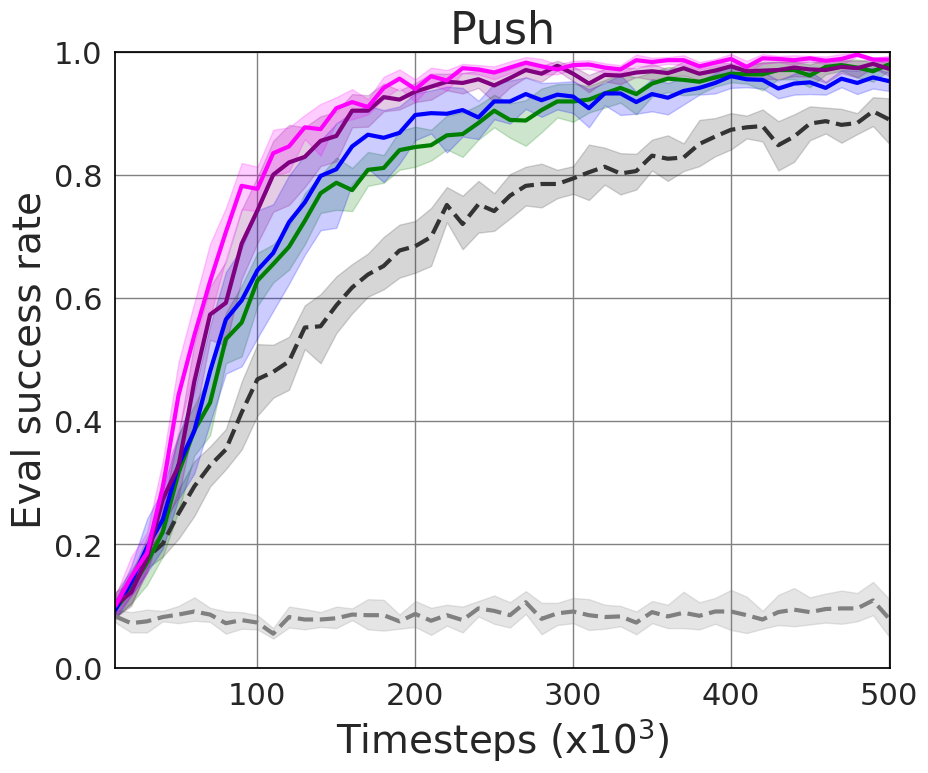
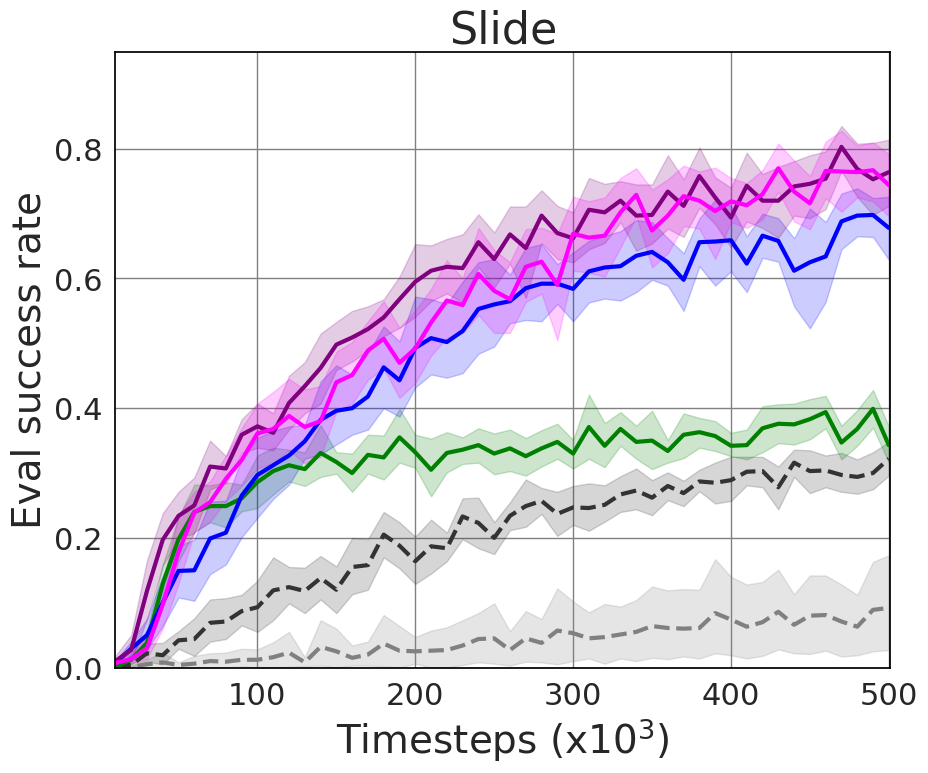
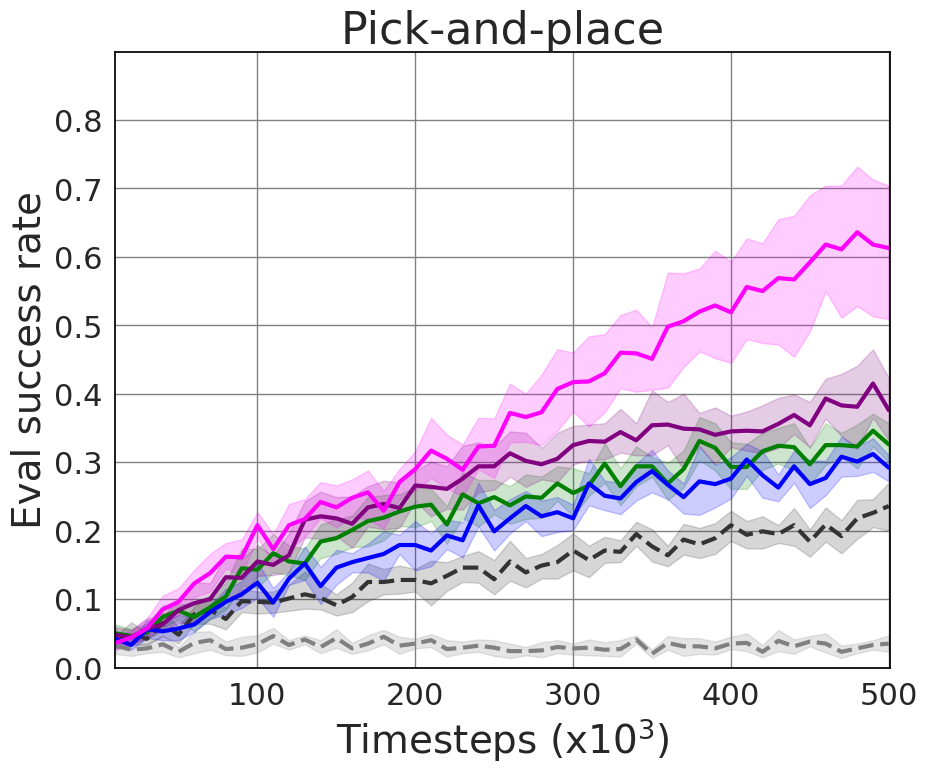

Figure 2: Our method compared to the state-of-the-art based on the evaluation success rate, demonstrating significant improvement.
Implementation Considerations
- Computational Cost: HiER+ necessitates additional memory for dual buffer management and may increase computational overhead due to entropy calculations.
- Scalability: Designed to generalize across various RL algorithms like SAC, TD3, and DDPG.
- Configurability: The choice between fix, predefined, AMA for λ, and predefined, self-paced, control for cj offers flexibility in tailoring to specific environments.
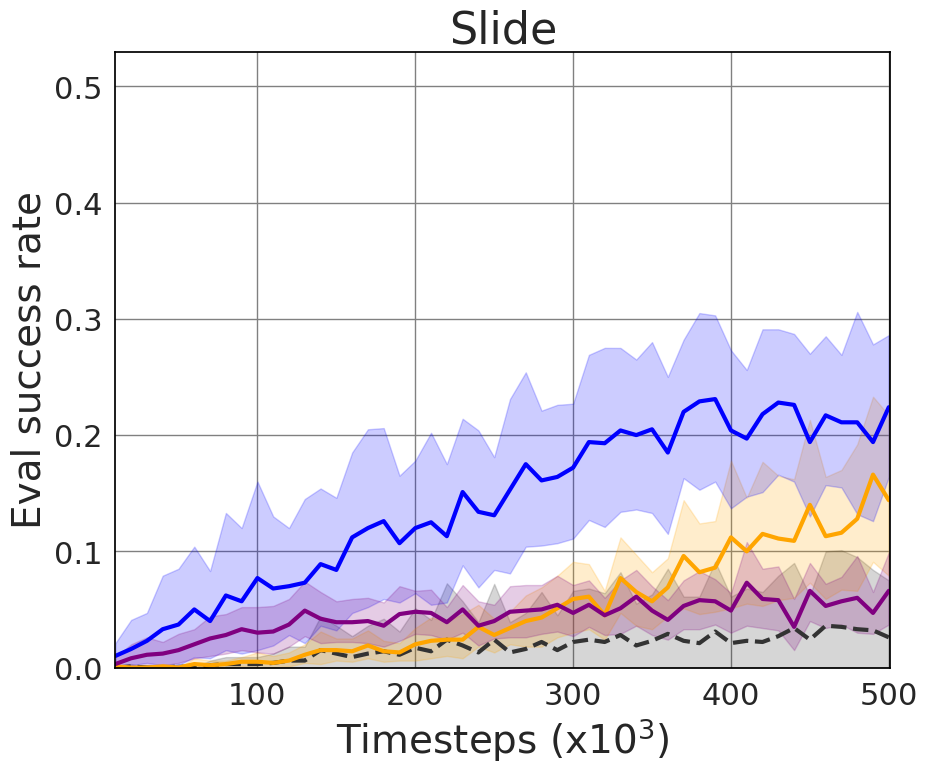

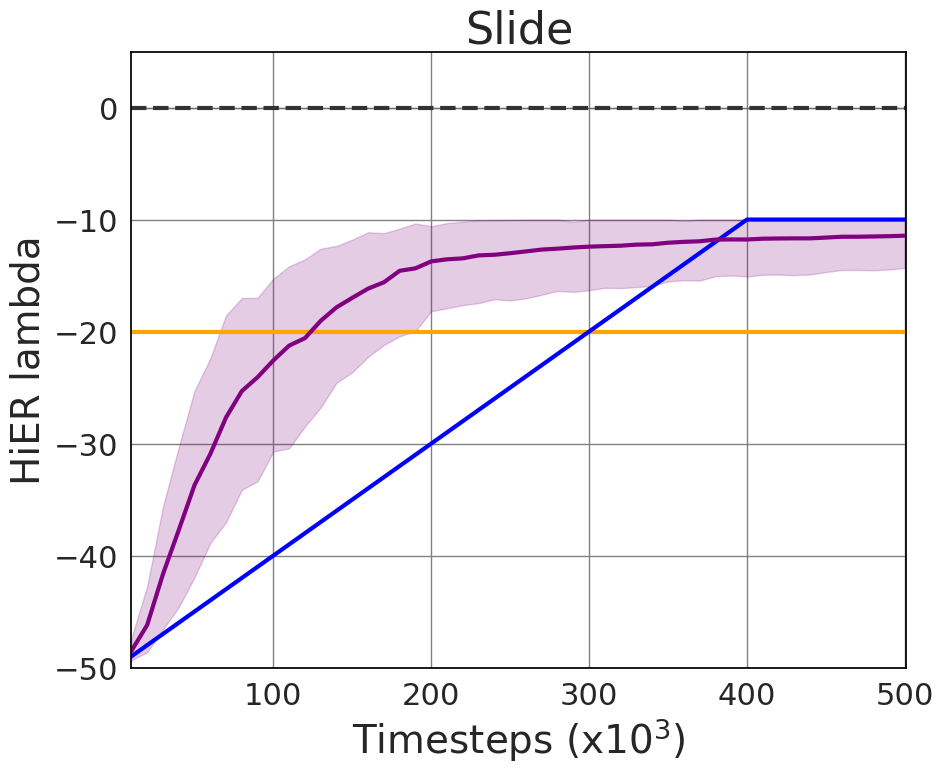
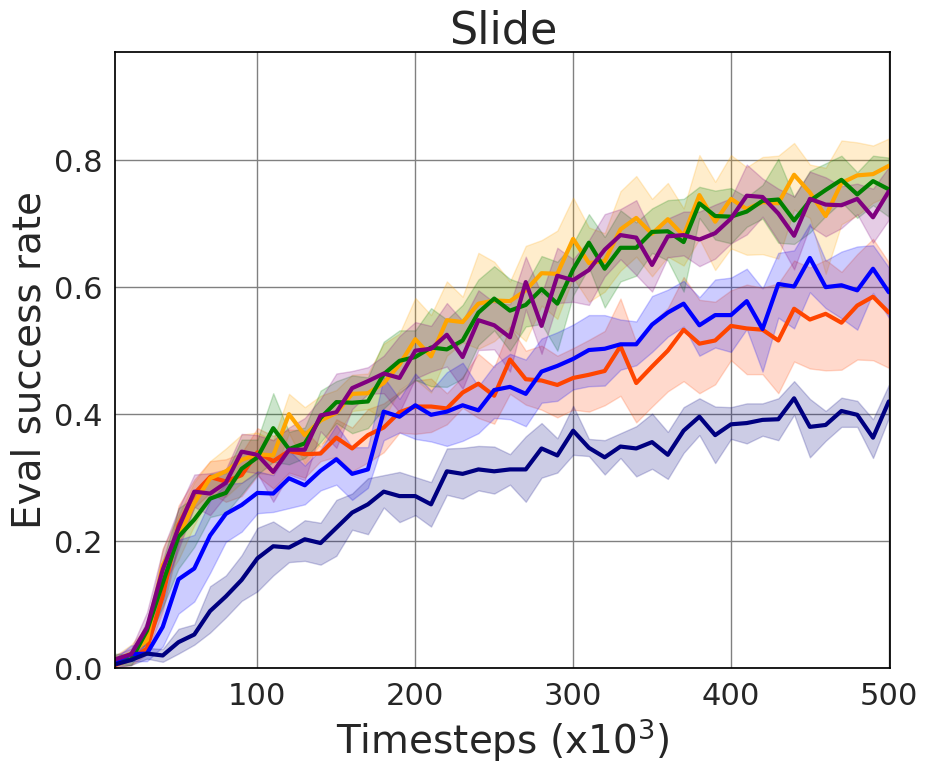

Figure 3: The effect of HiER lambda versions (a) and (b), and HiER xi versions (c). Parameters are clearly specified for replication.
Conclusion
The paper successfully introduces strategies for overcoming challenges in RL within continuous and sparse environments. HiER+ not only achieves remarkable results but also sets a precedent for algorithmic flexibility and robustness. Future exploration may explore optimizing HiER and E2H-ISE further, or exploring sim2real transfer efficiencies.
This research provides a structured pathway for practitioners aiming to enhance agent learning robustness in high-dimensional and reward-sparse environments.