Cross-Lingual Transfer with Target Language-Ready Task Adapters
Abstract: Adapters have emerged as a modular and parameter-efficient approach to (zero-shot) cross-lingual transfer. The established MAD-X framework employs separate language and task adapters which can be arbitrarily combined to perform the transfer of any task to any target language. Subsequently, BAD-X, an extension of the MAD-X framework, achieves improved transfer at the cost of MAD-X's modularity by creating "bilingual" adapters specific to the source-target language pair. In this work, we aim to take the best of both worlds by (i) fine-tuning task adapters adapted to the target language(s) (so-called "target language-ready" (TLR) adapters) to maintain high transfer performance, but (ii) without sacrificing the highly modular design of MAD-X. The main idea of "target language-ready" adapters is to resolve the training-vs-inference discrepancy of MAD-X: the task adapter "sees" the target language adapter for the very first time during inference, and thus might not be fully compatible with it. We address this mismatch by exposing the task adapter to the target language adapter during training, and empirically validate several variants of the idea: in the simplest form, we alternate between using the source and target language adapters during task adapter training, which can be generalized to cycling over any set of language adapters. We evaluate different TLR-based transfer configurations with varying degrees of generality across a suite of standard cross-lingual benchmarks, and find that the most general (and thus most modular) configuration consistently outperforms MAD-X and BAD-X on most tasks and languages.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about helping AI systems do language tasks (like finding names in text, answering questions, or checking if one sentence follows from another) in many different languages—especially languages with little training data. The authors propose a new, simple way to “prepare” small add-on modules, called adapters, so they work better across languages without needing to retrain huge models over and over.
What questions were the researchers asking?
They focused on two main questions:
- Can we make small, reusable “task adapters” that are already ready for the target language before testing, so they perform better when switching from English to other languages?
- Can we do this while keeping the system modular and efficient—so we can mix and match pieces instead of training a new model for every language pair?
How did they study it?
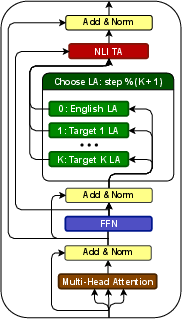
Think of a big multilingual model as a powerful game console. Adapters are plug-in cartridges that add skills without changing the console itself:
- A language adapter is like a “language ear”—it helps the model understand a specific language (like Swahili or Arabic).
- A task adapter is like a “task brain”—it helps the model do a specific job (like name tagging or question answering).
Two earlier setups:
- MAD-X: Keeps language and task adapters separate and mixable (very modular). But during training, the task adapter only “practices” with English, then meets the target language adapter for the first time during testing. That mismatch can hurt performance.
- BAD-X: Trains special “bilingual” language adapters for each English→target pair. This improves performance but loses modularity—you need many custom pieces and more compute.
The new idea:
- Target Language-Ready (TLR) task adapters. During training, the task adapter takes turns (“cycles”) practicing with different language adapters, not just English. That way, the task adapter gets used to the target language(s) before test time.
- Variants they tried:
- Target-only TLR: Practice only with the target language adapter.
- Bilingual TLR: Alternate between English and one target language.
- Multilingual TLR: Cycle through English and many target languages so one task adapter works across all of them (the most modular version).
What they tested on:
- They used well-known multilingual models (like mBERT and XLM-R).
- They evaluated across 6 datasets in 4 task families, covering 35 languages:
- Named Entity Recognition (NER): finding names of people, places, etc.
- Dependency Parsing (DP): figuring out grammatical structure.
- Natural Language Inference (NLI): deciding if one sentence follows from another.
- Question Answering (QA): answering questions from passages.
What did they find, and why is it important?
Here are the key takeaways:
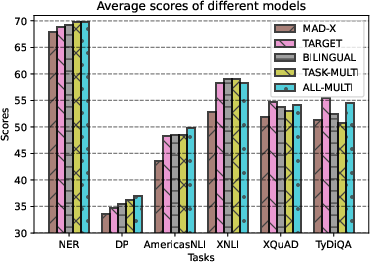
- TLR adapters consistently beat the standard modular approach (MAD-X) across most tasks and languages.
- The most general and reusable version—one multilingual TLR task adapter per task—often performed best. This means one small “task brain” can serve many languages well.
- TLR also matched or outperformed the less modular BAD-X on some tasks, showing you can keep modularity and still gain accuracy.
- Even when the task adapter hadn’t practiced with a specific language (“unseen” during training), the multilingual TLR still transferred better than the baseline. Practicing with many languages seems to teach it more general, language-agnostic skills.
- Analysis suggested TLR improves how well English and target-language representations “line up” inside the model, especially in key layers—likely explaining the accuracy boost.
- Results were robust across different training settings and random seeds.
Why this matters:
- Better performance for low-resource languages: TLR closes part of the “transfer gap” (the usual drop when moving from English to other languages).
- Efficiency and reuse: You can keep language adapters separate and train just one task adapter per task for many languages—saving time and compute.
What could this mean in the real world?
- Faster, cheaper multilingual AI: Organizations can support more languages (including underrepresented ones) without training a new model for each language pair.
- Easier maintenance: Modular pieces (language adapters and a shared task adapter) are simpler to update and reuse across projects.
- Fairer technology: Improved transfer helps languages with less data, bringing more equitable AI tools (like better search, chat, or information access) to more communities.
- A path to “universal” task adapters: With enough multilingual practice, a single task adapter may work well even on new languages it hasn’t seen—moving us closer to truly language-agnostic tools.
In short, the paper shows a practical way to get better multilingual performance by letting the task module “practice” with target languages during training—while keeping the system modular, efficient, and ready to serve many languages.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and could guide follow-up research:
- TA capacity and scaling: How do adapter bottleneck size, depth, and placement (e.g., which Transformer layers) affect performance as the number of target languages K grows? Are there “curse of multilinguality” effects at the TA level, and what are the capacity/regularization sweet spots?
- Scheduling of language adapters during TA training: What cycling/sampling policies (round-robin vs. stochastic; temperature- or resource-weighted; curriculum by typological distance) optimize transfer? Does progressive scheduling (e.g., source-heavy early, target-heavy later) help?
- Source/target data mix: TLR currently uses only English task data with target LAs. What is the impact of introducing target-language task data (gold, translated, pseudo-labeled) or unlabeled target text (auxiliary objectives) during TA training?
- Language set selection: How does the number, relatedness, and diversity of languages included in ALL-MULTI affect transfer to each target? Are there principled strategies to select languages that maximize benefit and minimize negative transfer?
- Variant selection criteria: When is TARGET vs. BILINGUAL vs. ALL-MULTI preferable? Can we predict the best variant from resource levels, token overlap, or typological distance, and design a decision procedure?
- Interaction with LA quality: How sensitive are TLR gains to the quality/size of monolingual corpora used to train LAs? What happens for very low-resource or noisy LAs, and can vocabulary adaptation or invertible adapters mitigate issues?
- Unseen languages and scripts: TLR assumes a pre-trained LA exists. How well does TLR work with generated LAs (e.g., MAD-G/UDapter) or vocabulary-adapted LAs for unseen scripts, and for languages outside the pretraining coverage (e.g., Amharic for mBERT)?
- Retaining source-language performance: Does TLR fine-tuning degrade English task accuracy? Quantify any source performance trade-offs and explore multi-objective training to preserve source while improving targets.
- Training/inference efficiency: What are the wall-clock time, memory, and energy costs of TLR vs. MAD-X/BAD-X, including overhead from per-step LA switching? Are there batching or caching strategies that reduce this overhead?
- Stability and robustness: Extend multi-seed significance testing to all tasks/languages; characterize variance across seeds and runs, and identify configurations with high variance.
- Hyperparameter sensitivity: Systematically study sensitivity to TA/LAs’ reduction factors, dropout, learning rates, last-layer adapter removal, and early stopping across tasks and languages; provide tuning guidelines.
- Partial unfreezing: Would unfreezing a subset of MMT or LA parameters during TLR training further reduce TA–LA incompatibility? Identify minimal unfreezing that yields consistent gains.
- Auxiliary alignment objectives: Beyond cycling LAs, do auxiliary losses (contrastive alignment, bilingual lexicon constraints, CCA-based objectives) further improve alignment and transfer when paired with TLR?
- Representation alignment analysis: Move beyond [CLS]-cosine to stronger diagnostics (e.g., CKA/CCA across layers, probing tasks, causal interventions) to establish how TLR alters cross-lingual representations and why that helps accuracy.
- Multi-task TLR: Can a single TA be trained to serve multiple tasks (NER/DP/NLI/QA) while cycling over many LAs? What are interference and parameter-sharing trade-offs vs. per-task TAs?
- Applicability to other PEFT methods: Do the TLR principles transfer to parallel adapters, prefix/prompt tuning, LoRA/IA3, or sparse subnetworks, and how do trade-offs compare?
- Larger and generative models: Validate TLR on larger backbones (e.g., XLM-R large, mDeBERTa, mT5) and on generation tasks (summarization, NMT) to test generality beyond classification/extractive QA.
- Code-switching and mixed inputs: Does TLR improve robustness on code-switched or mixed-script inputs where language identity shifts within examples?
- Domain shift: Evaluate TLR under cross-domain transfer (e.g., news → social media) to test whether multilingual regularization also aids domain robustness.
- Negative transfer detection: Identify when including distant or noisy languages in ALL-MULTI harms a target; design language selection/weighting methods to avoid negative transfer.
- Practical deployment footprint: Quantify the memory/storage trade-off of maintaining many LAs plus fewer TAs, and explore compression/sharing of LAs for on-device or low-resource deployment.
- Combining with BAD-X: Do TLR TAs stacked over bilingual (BAD-X) LAs yield additive gains, or do they redundantly specialize? Empirically test the interaction.
- Why TARGET excels on QA: Analyze whether TARGET’s advantage on QA stems from task complexity, answer-span localization, or language resource/tokenization effects; derive recommendations for QA-specific TLR setups.
- Data choice for QA: Using SQuAD to train TAs for TyDiQA improved results; quantify this cross-dataset effect more broadly and test alternative training data mixtures for QA.
- Learning curves vs. K: Provide systematic curves showing how performance changes as K (number of LAs in training) increases; identify saturation points and diminishing returns.
- Tokenization effects: Study how subword coverage and tokenization quality influence TLR gains; test synergy with vocabulary adaptation and adapter-based vocab expansion.
- Reproducibility details: Release per-run logs and random seeds for all experiments; report exact training times and GPU hours for transparent comparison.
Practical Applications
Immediate Applications
The paper’s TLR (Target Language-Ready) adapters provide modular, parameter-efficient improvements for zero-shot cross-lingual transfer across NER, dependency parsing, NLI, and QA. The authors released code and models, enabling deployment now (https://github.com/parovicm/tlr-adapters).
Industry
- Multilingual customer support and self-service QA
- Use case: Deploy TARGET or ALL-MULTI TLR task adapters on top of mBERT/XLM-R for FAQ-style QA and policy Q&A in Arabic, Hindi, Swahili, Chinese, etc., reducing English-only reliance.
- Sector: Software, customer experience.
- Tools/workflow: Hugging Face Transformers + AdapterHub; train or reuse LAs per target language; fine-tune TLR TA on English task data and cycle over LAs; serve via existing inference stack.
- Dependencies/assumptions: Availability of a language adapter (LA) per target language; mBERT/XLM-R tokenizer coverage for the script; domain mismatch may require light domain adaptation.
- Cross-lingual content moderation and compliance triage
- Use case: Use TLR-based NLI for entailment/contradiction checks of community guideline violations across languages; faster onboarding of new locales than full-model fine-tuning.
- Sector: Trust & safety, media platforms.
- Tools/workflow: NLI TA fine-tuned with ALL-MULTI cycling over LAs; thresholded decisions; human-in-the-loop escalation.
- Dependencies/assumptions: Label taxonomy alignment across regions; representative examples in English; cultural context and dialect variation may affect performance.
- Product catalog enrichment and search in e-commerce
- Use case: TLR NER for attribute extraction (brands, sizes, materials) and query understanding across African and Indic languages.
- Sector: Retail/e-commerce.
- Tools/workflow: Batch-process product text with TLR NER TA; integrate with search/ranking; active learning loop to correct systematic errors.
- Dependencies/assumptions: Domain shift from news/web to product text; availability/training of LAs for target markets.
- Multilingual document structuring for KYC/operations
- Use case: Combine TLR dependency parsing (DP) and NER to parse forms, IDs, and contracts in multiple languages without collecting labeled data for each.
- Sector: Finance, insurance, logistics.
- Tools/workflow: Pipeline: OCR -> TLR DP/NER -> downstream validation; adapter registry to swap LAs by language.
- Dependencies/assumptions: OCR quality; legal name/entity variants per locale; sufficient monolingual corpora to train LAs.
- News and social listening for global brand monitoring
- Use case: TLR NER to track people/organizations/locations across diverse languages; improved recall in low-resource settings.
- Sector: Marketing, competitive intelligence.
- Tools/workflow: Stream processing with language ID -> LA selection -> TLR TA inference; entity linking downstream.
- Dependencies/assumptions: Language identification accuracy; coverage for code-switching; LA availability.
Academia
- Rapid bootstrapping of NLP tools for under-resourced languages
- Use case: Generate initial NER/DP annotations using TLR TAs, then refine via active learning with native speakers.
- Sector: Computational linguistics, field linguistics.
- Tools/workflow: Train or reuse LAs on monolingual corpora (Wikipedia/Common Crawl); apply ALL-MULTI TA; iterative annotation.
- Dependencies/assumptions: Some monolingual text exists; script covered by base model; human validation capacity.
- Strong baselines for cross-lingual benchmarks
- Use case: Replace MAD-X/BAD-X baselines with ALL-MULTI TLR to improve SOTA baselines on MasakhaNER, UD DP, AmericasNLI, XNLI, TyDiQA.
- Sector: NLP research.
- Tools/workflow: Adopt authors’ hyperparameters; seed averaging when publishing; ablate LEAVE-OUT variants for unseen-language generalization.
- Dependencies/assumptions: Compute for LA training (one-time per language); consistent evaluation protocols.
Policy and Public Sector
- Multilingual citizen service portals
- Use case: Use TLR QA to answer queries about public services in minority languages without task-specific labels per language.
- Sector: Government, e-services.
- Tools/workflow: Knowledge base + retrieval + TLR QA TA; LA per language; accessibility testing.
- Dependencies/assumptions: High-quality, up-to-date knowledge base; careful evaluation for safety and fairness.
- Crisis communication and monitoring
- Use case: NER and NLI for early warning signals in local languages (e.g., disease outbreaks, disasters).
- Sector: Public health, emergency management.
- Tools/workflow: Stream social/media text; LA switch per language; prioritize human review on high-risk outputs.
- Dependencies/assumptions: Data access agreements; bias monitoring; dialect coverage.
Daily Life and NGOs
- Community chatbots for local languages
- Use case: NGOs deploy lightweight chatbots for health/education FAQs in low-resource languages using TLR QA.
- Sector: Non-profits, grassroots organizations.
- Tools/workflow: Cloud or edge deployment with adapter stacks; periodic updates as new languages’ LAs become available.
- Dependencies/assumptions: Device connectivity; culturally adapted content; privacy compliance.
- Open-source localization support
- Use case: Prelabel entity spans or structural cues to aid volunteer translators/localizers.
- Sector: Open-source software communities.
- Tools/workflow: TLR NER suggestions in translation interfaces; human confirmation.
- Dependencies/assumptions: Integration with CAT tools; community moderation.
Long-Term Applications
TLR introduces a path to universal, modular task adapters that generalize across many languages and tasks, but scaling and integration research remains.
Industry
- Universal multilingual task adapters-as-a-service
- Use case: Offer enterprise APIs with a single ALL-MULTI TA per task covering dozens to hundreds of languages; seamless addition of new LAs.
- Sector: NLP platforms, cloud providers.
- Tools/workflow: Adapter registry, versioning, and governance; automated LA training pipelines; SLAs per language tier.
- Dependencies/assumptions: Managing “curse of multilinguality” within TA capacity; continuous evaluation across languages/domains.
- On-device multilingual assistants
- Use case: Run adapter stacks on smartphones/IoT for private, low-latency NLU in local languages (commands, QA).
- Sector: Mobile, consumer electronics.
- Tools/workflow: Quantization/pruning of adapters; LoRA/parallel adapters integration; hardware-aware compilation.
- Dependencies/assumptions: Tight memory/compute budgets; ASR/TTS availability in target languages; energy constraints.
- Cross-lingual retrieval-augmented QA for enterprise search
- Use case: Employees query in their language; system retrieves from multilingual corpora and answers using TLR QA.
- Sector: Enterprise software, legal, pharma, finance.
- Tools/workflow: Cross-lingual dense retrieval + TLR QA; document governance.
- Dependencies/assumptions: Multilingual embeddings alignment; security and compliance controls; domain adaptation.
Academia
- Multi-task, multi-domain universal adapters
- Use case: A single TA that covers NER, NLI, QA, DP across languages via shared and task-specific submodules.
- Sector: NLP research and toolkits.
- Tools/workflow: Adapter composition, mixture-of-experts, sparsity; curriculum learning over tasks/languages.
- Dependencies/assumptions: New training regimes; catastrophic interference mitigation; robust evaluation suites.
- Adapter ecosystems with alternative PEFT methods
- Use case: Combine TLR with LoRA, prefix-tuning, and parallel adapters to optimize footprint vs. performance.
- Sector: Research-to-production pipelines.
- Tools/workflow: Unified APIs and schedulers for cycling LAs; auto-tuning reduction factors and routing.
- Dependencies/assumptions: Framework support; reproducibility standards.
Policy and Public Sector
- National language technology infrastructure
- Use case: Public registries of audited LAs for national and minority languages; standardized TLR TAs for common civic tasks.
- Sector: Digital public goods, language preservation.
- Tools/workflow: Funding pipelines for LA creation; open licensing; community review boards.
- Dependencies/assumptions: Stable funding; data governance; participation of language communities.
- Sustainability standards for NLP deployments
- Use case: Encourage PEFT (adapters) over full fine-tuning to reduce carbon footprint in multilingual services.
- Sector: Regulators, standards bodies.
- Tools/workflow: Reporting templates for compute/energy; procurement guidelines specifying adapter-based fine-tuning.
- Dependencies/assumptions: Agreement on metrics; vendor buy-in.
Daily Life and Education
- Low-resource voice assistants and accessibility tools
- Use case: Pair ASR with TLR NLU to support voice commands and reading comprehension for visually impaired users.
- Sector: Accessibility, EdTech.
- Tools/workflow: End-to-end pipelines integrating ASR/TTS with LA+TLR stacks; personalization via user LAs.
- Dependencies/assumptions: High-quality ASR/TTS for target languages; privacy, on-device constraints.
- Multilingual classroom support and assessment
- Use case: Reading comprehension QA and feedback in students’ home languages; formative assessment at scale.
- Sector: Education.
- Tools/workflow: Curriculum-aligned content; TLR QA with retrieval; teacher dashboards.
- Dependencies/assumptions: Safety/factuality guardrails; equitable performance across dialects.
Cross-cutting Assumptions and Risks
- Language adapter availability: LAs must be trained once per language on monolingual corpora; some languages may lack sufficient data.
- Tokenizer/script coverage: Base model vocabularies (mBERT/XLM-R) must support scripts; otherwise performance drops (e.g., Amharic with mBERT).
- Domain transfer: Zero-shot from English task data can degrade on specialized domains; light domain adaptation or few-shot data may be needed.
- Governance and fairness: Pretraining biases and uneven performance across languages/dialects require monitoring, human evaluation, and bias mitigation.
- Operational constraints: Storage for per-language LAs and per-task TAs; MLOps for adapter versioning, evaluation, and rollout.
Glossary
- Adapter reduction factor: The ratio controlling how much an adapter compresses and expands hidden representations (i.e., model hidden size to adapter bottleneck size). Example: "the adapter reduction factor (i.e., the ra- tio between MMT's hidden size and the adapter's bottleneck size)"
- Adapters: Lightweight, pluggable modules added to pretrained models to enable parameter-efficient fine-tuning and modular knowledge reuse. Example: "Adapters have emerged as a modular and parameter-efficient approach to (zero-shot) cross-lingual transfer."
- ALL-MULTI (TLR variant): A target language-ready training variant where a single task adapter cycles over language adapters for all target languages across tasks. Example: "the ALL-MULTI TLR variant combines the source language with all target languages across datasets of multiple tasks"
- BAD-X: An adapter framework that uses bilingual language adapters specialized for a particular source–target language pair, trading off modularity for performance. Example: "BAD-X trains bilingual LAs (Parović et al., 2022)."
- Bilingual language adapter (LA): A language adapter trained jointly on two languages (source and target) to better support transfer between them. Example: "A bilingual LA is trained on the un- labeled data of both Ls and Lt"
- BILINGUAL (TLR variant): A TLR training setup in which the task adapter alternates between the source and a single target language adapter during training. Example: "the bilingual variant with a TLR TA trained by alternating between the source and target LA"
- Bottleneck (adapter bottleneck): The reduced-dimensional layer inside an adapter that compresses information before re-expanding it, enabling parameter efficiency. Example: "the adapter's bottleneck size"
- CLS token: The special classification token in Transformer models whose representation is often used for sentence-level tasks. Example: "mBERT's [CLS] token"
- Contextual parameter generation: A method that generates adapter parameters conditioned on language or task contexts to enable flexible sharing. Example: "contextual parameter generation method"
- Cosine similarity: A measure of vector alignment used here to quantify representation alignment across languages. Example: "cosine similarity between English and target representations"
- Cross-lingual transfer gap: The performance difference between a source language and target languages in zero-shot transfer. Example: "the cross-lingual trans- fer gap"
- Curse of multilinguality: The phenomenon where adding more languages can degrade performance due to limited capacity. Example: "'the curse of multilin- guality'"
- Dependency parsing (DP): The task of predicting syntactic head–dependent relations between words in a sentence. Example: "dependency parsing (DP)"
- Exact Match (EM): A QA evaluation metric indicating the percentage of predictions that exactly match the gold answer span. Example: "F1/EM"
- Invertible adapters: Adapters that include reversible transformations (often used for vocabulary/script adaptation) to better retain information. Example: "with invertible adapters"
- Labeled Attachment Score (LAS): A dependency parsing metric measuring the percentage of words attached to the correct head with the correct label. Example: "LAS"
- Language adapter (LA): An adapter module trained on monolingual data to capture language-specific representations. Example: "language adapters (LAs)"
- Language-universal task adapters: Task adapters trained to generalize across many target languages rather than specializing to one. Example: "language-universal TAs."
- Masked language modeling (MLM): A pretraining objective where random tokens are masked and the model learns to predict them from context. Example: "masked language modeling (MLM) objective"
- Massively multilingual Transformer (MMT): A Transformer model pretrained on many languages to enable multilingual representation learning. Example: "massively multilingual Transformer models (MMTs)"
- Multilingual regularization: The effect where exposing a task adapter to multiple languages during training reduces overfitting and promotes cross-language generality. Example: "acts as a multi- lingual regularization"
- Named entity recognition (NER): The task of identifying and classifying named spans (e.g., people, locations) in text. Example: "For NER, we use the MasakhaNER dataset"
- Natural language inference (NLI): The task of determining the entailment relationship between a premise and a hypothesis. Example: "natural lan- guage inference (NLI)"
- Parameter-efficient fine-tuning: Techniques that adapt large models by modifying or adding only a small number of parameters (e.g., adapters, prompts). Example: "Parameter-Efficient Fine-Tuning has emerged"
- Perplexity: A language modeling metric used here to select the best language adapters based on held-out data. Example: "lowest perplexity"
- Pfeiffer adapter configuration: A specific adapter architecture/configuration (including invertible adapters for LAs) widely used in adapter-based transfer. Example: "use the Pfeiffer configura- tion"
- Residual connection: A skip connection that adds an input to a layer’s output to ease optimization and preserve information flow. Example: "residual connection"
- ReLU: A non-linear activation function defined as max(0, x), used within adapter modules. Example: "with ReLU as the activation function."
- Serial adapters: Adapter modules inserted sequentially within Transformer layers, forming a stack in the forward pass. Example: "serial adapters"
- Subword vocabulary: The set of subword units (e.g., WordPiece/BPE) used by tokenizers in multilingual models like mBERT. Example: "subword vocabulary"
- Task adapter (TA): An adapter trained on task-specific data to encode task knowledge while leveraging a frozen backbone model. Example: "task adapters (TAs)"
- TASK-MULTI (TLR variant): A TLR setup where a single task adapter cycles over language adapters for all target languages within the same task. Example: "the so-called TASK-MULTI TLR variant"
- TARGET-only (TLR variant): A TLR approach where the task adapter is trained only with the target language adapter (without cycling with the source). Example: "Such TARGET-only TLR TAs"
- Training-vs-inference discrepancy: The mismatch when components (e.g., a task adapter) encounter unseen language adapters only at inference time. Example: "training-vs-inference discrepancy"
- Universal Dependencies: A cross-linguistic framework for consistent dependency annotation across languages. Example: "Universal Dependencies"
- Zero-shot cross-lingual transfer: Applying a model trained on a source language directly to a target language without target-language task training data. Example: "zero-shot cross-lingual transfer"
Collections
Sign up for free to add this paper to one or more collections.

