Visual Instruction Tuning
Abstract: Instruction tuning LLMs using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. In this paper, we present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. By instruction tuning on such generated data, we introduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.
- Langchain. https://github.com/hwchase17/langchain, 2022.
- Flamingo: a visual language model for few-shot learning. arXiv preprint arXiv:2204.14198, 2022.
- Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2018.
- A general language assistant as a laboratory for alignment. arXiv preprint arXiv:2112.00861, 2021.
- Openflamingo, March 2023.
- Instruct pix2pix: Learning to follow image editing instructions. arXiv preprint arXiv:2211.09800, 2022.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In CVPR, 2021.
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023.
- Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
- CVinW. Computer vision in the wild. https://github.com/Computer-Vision-in-the-Wild/CVinW_Readings, 2022.
- PaLM-E: An embodied multimodal language model. arXiv preprint arXiv:2303.03378, 2023.
- Reinforce data, multiply impact: Improved model accuracy and robustness with dataset reinforcement. arXiv preprint arXiv:2303.08983, 2023.
- Make-a-scene: Scene-based text-to-image generation with human priors. ArXiv, abs/2203.13131, 2022.
- Vision-language pre-training: Basics, recent advances, and future trends. Foundations and Trends® in Computer Graphics and Vision, 2022.
- Chatgpt outperforms crowd-workers for text-annotation tasks. arXiv preprint arXiv:2303.15056, 2023.
- Visual programming: Compositional visual reasoning without training. arXiv preprint arXiv:2211.11559, 2022.
- Towards learning a generic agent for vision-and-language navigation via pre-training. In CVPR, 2020.
- Language is not all you need: Aligning perception with language models. arXiv preprint arXiv:2302.14045, 2023.
- Openclip. July 2021. If you use this software, please cite it as below.
- Opt-iml: Scaling language model instruction meta learning through the lens of generalization. arXiv preprint arXiv:2212.12017, 2022.
- Visual prompt tuning. In ECCV, 2022.
- Grounding language models to images for multimodal generation. arXiv preprint arXiv:2301.13823, 2023.
- Language-driven semantic segmentation. ICLR, 2022.
- Multimodal foundation models: From specialists to general-purpose assistants. arXiv preprint arXiv:2309.10020, 2023.
- ELEVATER: A benchmark and toolkit for evaluating language-augmented visual models. In NeurIPS Track on Datasets and Benchmarks, 2022.
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
- Grounded language-image pre-training. In CVPR, 2022.
- Gligen: Open-set grounded text-to-image generation. arXiv preprint arXiv:2301.07093, 2023.
- Microsoft COCO: Common objects in context. In ECCV, 2014.
- Improved baselines with visual instruction tuning, 2023.
- Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023.
- Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in Neural Information Processing Systems, 2022.
- OpenAI. ChatGPT. https://openai.com/blog/chatgpt/, 2023.
- OpenAI. Gpt-4 technical report, 2023.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Instruction tuning with GPT-4. arXiv preprint arXiv:2304.03277, 2023.
- Combined scaling for open-vocabulary image classification. arXiv preprint arXiv: 2111.10050, 2021.
- Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
- Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 2020.
- Hierarchical text-conditional image generation with clip latents. ArXiv, abs/2204.06125, 2022.
- High-resolution image synthesis with latent diffusion models. CVPR, pages 10674–10685, 2022.
- Photorealistic text-to-image diffusion models with deep language understanding. ArXiv, abs/2205.11487, 2022.
- Laion-5b: An open large-scale dataset for training next generation image-text models. arXiv preprint arXiv:2210.08402, 2022.
- Vipergpt: Visual inference via python execution for reasoning. arXiv preprint arXiv:2303.08128, 2023.
- Habitat 2.0: Training home assistants to rearrange their habitat. In Advances in Neural Information Processing Systems (NeurIPS), 2021.
- Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Git: A generative image-to-text transformer for vision and language. arXiv preprint arXiv:2205.14100, 2022.
- Self-instruct: Aligning language model with self generated instructions. arXiv preprint arXiv:2212.10560, 2022.
- Benchmarking generalization via in-context instructions on 1,600+ language tasks. arXiv preprint arXiv:2204.07705, 2022.
- Visual chatgpt: Talking, drawing and editing with visual foundation models. arXiv preprint arXiv:2303.04671, 2023.
- Unified contrastive learning in image-text-label space. CVPR, 2022.
- Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv preprint arXiv:2303.11381, 2023.
- Scaling autoregressive models for content-rich text-to-image generation. ArXiv, abs/2206.10789, 2022.
- Florence: A new foundation model for computer vision. arXiv preprint arXiv:2111.11432, 2021.
- A simple framework for open-vocabulary segmentation and detection. arXiv preprint arXiv:2303.08131, 2023.
- Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199, 2023.
- OPT: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- Multimodal chain-of-thought reasoning in language models. arXiv preprint arXiv:2302.00923, 2023.
- Regionclip: Region-based language-image pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16793–16803, 2022.
- Generalized decoding for pixel, image, and language. arXiv preprint arXiv:2212.11270, 2022.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Visual Instruction Tuning (LLaVA) — Explained Simply
Overview
This paper introduces LLaVA, a computer system that can look at pictures and talk about them like a helpful assistant. It combines “vision” (seeing images) with “language” (understanding and writing text). The main idea is to teach this system to follow instructions about images—like “What’s unusual in this photo?”—so it can handle many real-world tasks.
Key Objectives
The researchers wanted to:
- Build a smart assistant that can understand both images and text, and follow instructions about them.
- Create high-quality practice data (questions and answers about images) to train such assistants.
- Test how well the system can chat about images and solve science problems that use pictures and text.
How They Did It (Methods)
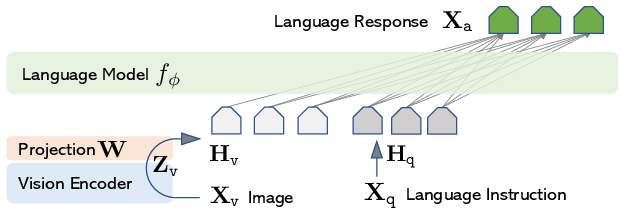
Think of LLaVA as having two parts:
- Eyes: a vision model that turns images into numbers the computer can understand.
- Brain and voice: a LLM that reads text and writes answers.
Here’s how they trained it:
- Making practice data with GPT-4 and ChatGPT:
- The world has many “image + caption” pairs (pictures with short descriptions), but not many “image + instruction + answer” examples.
- The team used text-only GPT-4/ChatGPT to turn existing image data into instruction-following examples. Since GPT-4 can’t directly see images, they “described” images in text using:
- Captions: sentences about what’s in the picture.
- Bounding boxes: labels and positions of objects (like sticky notes with names and coordinates).
- From these, GPT-4 produced:
- Conversations: Q&A about the image.
- Detailed descriptions: rich, thorough write-ups.
- Complex reasoning: step-by-step thinking about what’s happening and why.
They built a dataset of about 158,000 examples across these types.
- Building the model:
- Vision encoder: CLIP ViT-L/14 (a popular “eyes” model) turns images into features.
- LLM: Vicuna (a strong open-source “brain” for chatting).
- Connector: a simple “adapter” (a small layer) that translates image features into the kind of tokens the LLM understands—like plugging a camera into a computer with the right cable.
- Training in two stages:
- Stage 1: Feature alignment
- They trained only the small adapter layer on a large set of image-caption pairs (about 595,000) so the “eyes” and “brain” learned to speak to each other properly.
- Stage 2: End-to-end fine-tuning
- They trained the adapter and the LLM together on the 158K instruction-following examples (conversations, detailed descriptions, complex reasoning), so LLaVA learns to follow questions and give helpful answers.
- How learning works (in simple terms):
- The model reads the instruction plus the image features and then predicts the answer word-by-word, like finishing a sentence one token at a time.
Main Findings and Why They Matter
What did LLaVA achieve?
- Strong multimodal chat:
- LLaVA can answer questions about images in a helpful way, not just describe them. For example, when asked, “What’s unusual about this image?” it points out odd details (like someone ironing clothes on top of a car) instead of giving a generic caption.
- Competitive performance compared to advanced systems:
- On their synthetic instruction-following benchmark, LLaVA reached about 85% of GPT-4’s score (where GPT-4 had access to perfect text descriptions of the image).
- On a tougher “in-the-wild” benchmark with diverse images, LLaVA beat other open models like BLIP-2 and OpenFlamingo by a large margin and did especially well on complex reasoning questions.
- Science question answering:
- On the ScienceQA dataset (questions with text or images), LLaVA scored about 90.9% accuracy.
- When combined with GPT-4 as a “judge” to pick the better answer if LLaVA and GPT-4 disagreed, the accuracy rose to 92.53%, a new state-of-the-art at the time. This shows a smart teamwork method: an image-capable model plus a strong text-only model can perform better together.
Limitations they noticed:
- Very fine details in high-resolution images can be hard to read correctly (like specific yogurt brands in a packed fridge).
- Sometimes the model guesses wrongly if it treats an image like separate patches rather than understanding the full scene (for example, confusing “strawberries” with “strawberry-flavored yogurt”).
- Some questions require broad knowledge or multilingual understanding (like recognizing restaurant names in another language).
Implications and Potential Impact
- A step toward general-purpose visual assistants: LLaVA shows that instruction tuning—originally used for text-only models—also works well for image+text systems. This could make future assistants more helpful in everyday tasks, from describing photos to reasoning about scenes.
- Better training recipes: Using GPT-4/ChatGPT to generate diverse, high-quality practice data is a practical way to teach multimodal models to follow instructions without needing huge amounts of hand-labeled data.
- Strong benchmarks and open resources: The team released their data, code, model, and demo, and built new evaluation sets. This helps other researchers and developers build and test better multimodal assistants.
- Synergy with powerful LLMs: Using GPT-4 as a judge to combine answers can boost accuracy. This idea—models helping each other—could lead to smarter, more reliable AI systems.
In short, this work shows how to make an AI that can “see” and “talk” in a useful way, and sets a foundation for building assistants that understand visuals and follow human instructions more naturally.
Collections
Sign up for free to add this paper to one or more collections.