- The paper introduces GPT-4-generated instruction data for tuning LLaMA models to enhance instruction-following abilities.
- It demonstrates that models tuned with GPT-4 data significantly outperform benchmarks like Alpaca and Vicuna in both human and automated evaluations.
- The approach yields practical improvements in adaptability and task alignment, validated across English and Chinese datasets.
Instruction Tuning with GPT-4
The paper "Instruction Tuning with GPT-4" proposes the utilization of GPT-4-generated data to improve the instruction-following capabilities of LLMs, specifically focusing on LLaMA models. By leveraging the superior abilities of GPT-4 in generating instruction-following data, the authors demonstrate enhanced performance over previously established models such as Alpaca and Vicuna.
Introduction
Instruction tuning for LLMs involves fine-tuning models on datasets with tasks described in natural language prompts, thereby enriching the models' capabilities to generalize across diverse tasks. This approach is significantly beneficial in enhancing zero-shot performance. Prior methods relied on human-generated instructions, but recent advances allow machine-generated data via leading models such as GPT-3.5 and GPT-4. The paper presents an initial exploration into harnessing GPT-4 for generating high-quality instruction-following data, aiming to boost the performance of open-source LLaMA models.

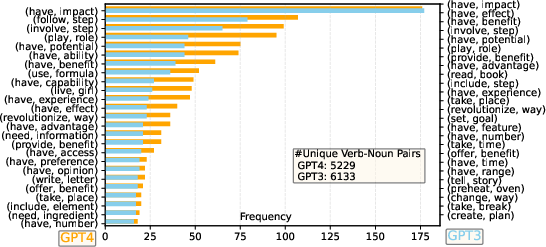
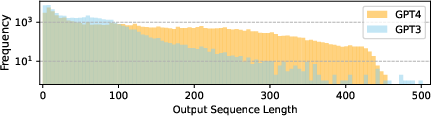
Figure 1: Comparison of generated responses using GPT-4 and GPT-3 showcasing superior alignment performance of GPT-4-generated data.
Dataset
The paper details the generation of 52K instruction-following samples in both English and Chinese using GPT-4, aimed at refining LLaMA models. The authors designed multiple datasets, including English and Chinese instruction-following data, comparison data, and unnatural instructions, to test the generative and evaluative performance of LLMs. Notably, the generated datasets are characterized by longer sequence lengths and richer verb-noun pair frequencies, indicating a deeper alignment with the task requirements than previous iterations using GPT-3.5.
Instruction-Tuning Models
Instruction tuning employs supervised fine-tuning of LLaMA models using the GPT-4-generated dataset. Two primary models were developed: LLaMA-GPT4 (English) and LLaMA-GPT4-CN (Chinese). These models provide a comparative base for assessing the effectiveness of GPT-4-generated data versus earlier models like Alpaca, demonstrating significant enhancements in model capabilities across unseen instructional tasks.
Human and Automatic Evaluation
The paper presents a dual evaluation approach using both human inputs based on HHH criteria (helpfulness, honesty, harmlessness) and automated evaluations leveraging GPT-4. Human evaluations reveal higher adaptability and alignment of GPT-4-trained models compared to GPT-3.5-based models (Figure 2).

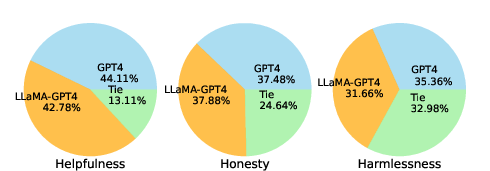
Figure 2: Human evaluation results showing the alignment criteria comparison between models.
Automated evaluations depict a consistent improvement of the LLaMA-GPT4 model, particularly when benchmarked against ChatGPT and existing LLMs across diverse and challenging instruction sets. The results confidently underline the value added by GPT-4-generated data in terms of instructional task adherence.
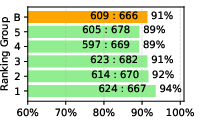
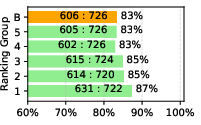
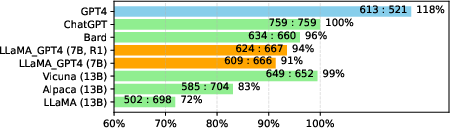
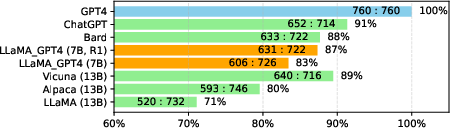
Figure 3: Performance comparisons evaluated by GPT-4 indicating competitive alignment and instruction-following capabilities of LLaMA-GPT4 models.
Theoretical and Practical Implications
Practically, the paper opens avenues for developing robust, instruction-aligned open-source LLMs capable of diverse task execution. Theoretically, it challenges the conventional reliance on human dataculture, suggesting a pivot towards machine-generated instructional data to refine LLMs’ architectures and capabilities. This shift could redefine training paradigms, optimize resource usage, and enhance model scalability.
Speculations on Future Developments
Future research could explore the scaling of data and model sizes to encompass broader instructional scopes. Also, implementing reinforcement learning from human feedback (RLHF) using reward models trained on machine-generated comparison data could further refine alignment strategies, developing LLMs that inherently adapt to evolving human-centric task requirements.
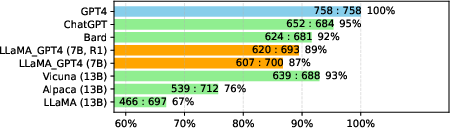
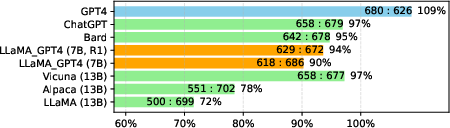

Figure 4: Performance comparisons of LLaMA-GPT4 in Chinese, showing adaptability across languages.
Conclusion
The exploration of instruction tuning using GPT-4 marks a significant stride in advancing LLM efficiencies and generalization capabilities. The empirical success demonstrated by aligning LLaMA models with GPT-4-generated data suggests promising pathways for the evolution of instruction-tuned LLMs, showcasing improvements in alignment and performance while cultivating open-source efforts towards highly efficient models capable of complex task execution.

